UCI数据集官网链接 https://archive.ics.uci.edu/ml/datasets.php
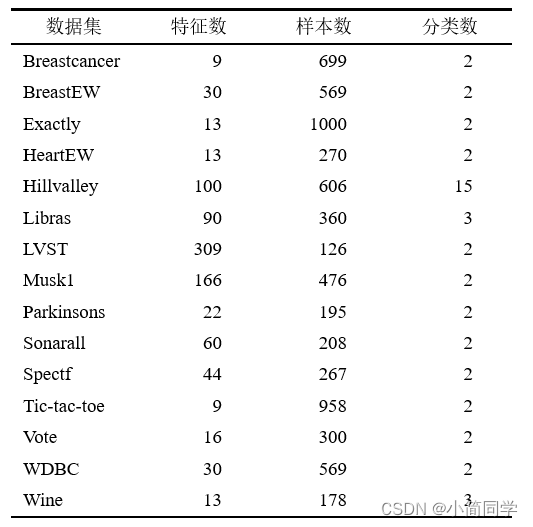
下面是部分UCI数据集包括 “Breastcancer”,“BreastEW”,“Exactly”,“HeartEW”,“Hillvalley”,“Libras”,“LVST”,“Musk1”,“Parkinsons”,“Sonarall”,“Spectf”,“Tic-tac-toe”,“Vote”,“WDBC”,"Wine"等
数据集均为.csv格式 其中第一列为样本属性。
百度网盘链接链接:https://pan.baidu.com/s/1kLXFKBFHGJpeNQWYDF7IFw
提取码:2mun
import pandas as pd
import numpy as np
def dataset_load(dataset):
data = pd.read_csv(dataset,header = None)
data = np.array(data)
n, m = data.shape
#数据预处理,将离散变量转变为数字量
for one in range(m):
col=data[:,one]
#是数字类型
if (str(list(col)[0]).split(".")[0]).isdigit() or str(list(col)[0]).isdigit() or ((str(list(col)[0]).split('-')[-1]).split(".")[-1].isdigit()and(str(list(col)[0]).split('-')[0]).isdigit()):
data[:,one]=data[:,one]
#是字符类型
else:
data[:,one]=pd.factorize(data[:,one])[0].astype(np.uint16)
x = data[:,1:] #x为特征
y = data[:,0] #y为标签
return x,y
if __name__=='__main__':
dataset='Wine.csv' #这里注意将数据集和程序放在同一路径
x,y=dataset_load(dataset) #读入数据
print(x)
如有问题欢迎大家讨论。