《Finding Tiny Faces》论文阅读笔记
论文地址:https://www.cs.cmu.edu/~peiyunh/tiny/
作者代码(Matlab版):https://github.com/peiyunh/tiny
其他代码(python-tensorflow版,亲测可用):https://github.com/cydonia999/Tiny_Faces_in_Tensorflow
博主有话说:
入门小白,本来以为只用看一篇论文,没想到论文涉及到一些网络和算法都是一带而过,需要东拼西凑才能看懂,所以将阅读这篇论文的心得和学习过程写下捋顺自己的学习脉络。
基础知识
本篇论文涉及到深度学习相关算法和人脸检测相关算法:
介绍深度学习相关知识是为了看懂作者放在GitHub的网络图,这些不是这篇论文最主要的内容。
CNN(卷积神经网络)
介绍CNN的知识是为了对接下来的Resnet网络作铺垫。
在这里我们需要知道两个概念 —— 卷积和池化。
1.卷积
卷积操作:假设输入是一个a × \times ×a的矩阵,我们构造一个b × \times ×b的矩阵,这个矩阵为filter(过滤器),通过逐步滑动之后,我们就得到一个(a-b+1) × \times ×(a-b+1)的输出
例:

在卷积层中,过滤器为要学习的参数。在这一层中,涉及到的超参数有:过滤器的大小,卷积步长(stride),填充大小(padding),过滤器个数。
2.池化(pool)
池化操作分为平均池化和最大池化。
平均池化就是输出每个过滤器区域的最大值,最大池化就是输出每个过滤器区域的最大值。
例: 池化中涉及到的超参数:步长、过滤器大小、池化类型最大池化or平均池化
池化中涉及到的超参数:步长、过滤器大小、池化类型最大池化or平均池化
从上面我们可以看出,卷积层是提取输入的不同特征;池化层是将特征切成几个区域,得到维度较小的特征。
详细内容:https://blog.csdn.net/ice_actor/article/details/78648780
Resnet(深度残差学习网络)
这篇论文中作者用了VGG-16,Resnet50和Resnet100网络来测试论文中提到的算法,实验结果发现Resnet101网络的效果是最好的,其他做过实验的网络有时间再更,我们来看一下Resnet网络。
怎么去解释作者的策略呢?
假设输入为X,某一有参网络层为H,经过这层后输出为H(X),一般直接学习X到H(X)。
残差学习就是学习输入输出之间的残差,即学习X到(H(X)-X)+X,如下图:
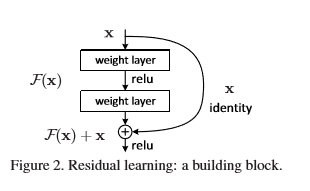
文章中用的下图所示结构块,这样可以降低参数数量:
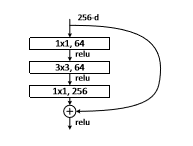
我们在看Tiny faces作者给出的网络结构图时,会发现是以下结构,这是为了保证输入输出通道数一致。

详细介绍:https://blog.csdn.net/xxy0118/article/details/78324256
NMS(非极大值抑制)
在人脸检测的最后阶段,在一个人脸上可能有不止一个检测框,这个时候我们需要选取最合适的那个检测框,因此就需要用到NMS算法。如何选取最合适的框,简单来说就是我们通过网络每个框都有一个分数,这里我们需要涉及到IOU(重叠率)的问题。
IOU就是候选框与原标记框之间的交叠率,如下:
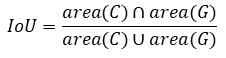
流程如下:
(1)将所有框的得分排序,选中最高分及其对应的框。
(2)遍历其余的框,如果和当前最高分框的重叠面积(IOU)大于一定阈值,我们就将框删除。
(3)从未处理的框中继续选一个得分最高的,重复上述过程。
这样我们就能保留所有最合适的框了。
 详细介绍:https://blog.csdn.net/shuzfan/article/details/52711706
详细介绍:https://blog.csdn.net/shuzfan/article/details/52711706
论文翻译(粗翻)
为了方便自己复习将翻译放在博客里,很多细节并没有详细修正,可跳过,建议自己看原论文。
摘要
虽然在物体识别方面取得了巨大进步,但其中一个主要的开放挑战是检测小物体。我们在探讨小面孔的背景下探讨三个问题:尺度不变性,图像分辨率和上下文因素。虽然大多数识别方法的目标是尺度不变,但识别3px人脸的线索与识别300px人脸的线索基本不同。我们采用不同的方法,并为不同的尺度训练单独的探测器。为了保持效率,探测器以多任务方式进行训练:它们利用从单层(深层)特征层次结构的多个层提取的特征。虽然训练大型物体的探测器很简单,但关键的挑战仍然是训练小物体的探测器。我们证明了上下文是至关重要的,并且定义了利用大量接收场的模板(其中99%的模板超出了感兴趣的对象)。最后,我们探讨了规模在预训练深度网络中的作用,提供了将有限尺度调整到极端范围的网络外推的方法。我们在大规模基准面部数据集(FDDB和WIDER FACE)上展示了最先进的结果。特别地,当与WIDER FACE上的现有技术相比时,我们的结果将误差减少了2倍(我们的模型产生的AP为82%,而现有技术的范围为29-64%)。
介绍
虽然在物体识别方面取得了巨大进步,但其中一个主要的开放挑战是检测小物体。 我们在人脸检测的背景下探讨问题的三个方面:尺度不变性的作用,图像分辨率和上下文因素。 尺度不变性是几乎所有当前识别和物体检测系统的基本属性。 但是从实际的角度来看,尺度不变性不适用于具有有限分辨率的传感器:识别300px人脸的线索无疑与识别3px人脸的线索不同。
Multi-tasking modeling of scales
最近在物体检测方面的许多工作利用了尺度归一化的分类器(例如,在图像金字塔上运行的扫描窗口检测器或在“ROI” - 合并的图像特征上运行的区域分类器)。当调整区域时,我们会提出一个简单的问题 - 模板的大小应该是多少?一方面,我们想要一个可以检测小脸的小模板;另一方面,我们想要一个可以利用详细功能(比如面部部件)的大模板来提高准确性。我们不是采用“单一尺寸”方法,而是针对不同尺度(和纵横比)调整单独的探测器。训练大量的特定尺度探测器可能会因缺乏单个尺度的训练数据而受到影响,并且在测试时运行大量探测器会导致效率低下。为解决这两个问题,我们以多任务方式训练和运行规模特定的探测器:它们利用在多层单(深)特征层次结构上定义的特征。虽然这种策略可以为大型物体提供高精度的探测器,但找到小东西仍然具有挑战性。
How to generalize pre-trained networks?
我们提供了两个关于发现小物体问题的关键见解。 第一个是分析如何最好地从预训练的深度网络中提取尺度不变特征。 我们证明现有网络针对特征尺寸的对象进行了调整(在预训练数据集中遇到过,如ImageNet)。 为了将从这些网络中调整的特征扩展到新颖尺寸的对象,我们采用了一种简单的策略:通过插值和抽取在测试时调整图像大小。 虽然许多识别系统通过处理图像金字塔以“多分辨率”方式应用,但我们发现插入金字塔的最低层对于发现小物体尤其重要。 因此,我们的最终方法(图2)是尺度特定探测器的精细混合,以尺度不变的方式使用(通过处理图像金字塔来捕获大规模变化)。
 图2:捕获尺度不变性的不同方法。
图2:捕获尺度不变性的不同方法。
1.传统方法构建了一个单尺度模板,应用于完全离散化的图像金字塔(a)。
2.为了利用不同分辨率下可用的不同提示,可以为不同的物体尺度构建不同的探测器(b)。 这种方法可能在很少观察到(或预训练)数据的极端物体尺度上失败。
3.我们利用粗糙的图像金字塔来捕捉(c)中的极端尺度挑战。
4.最后,为了提高小脸的性能,我们建模了额外的上下文,它有效地实现了所有尺度特定模板的固定尺寸接收领域(d)。
5.我们为从深层模型的多个层提取的特征定义模板,这类似于中央凹描述符(e)。
How best to encode context?
寻找小对象具有根本性的挑战性,因为对象上几乎没有信号可以利用。因此,我们认为必须使用超出对象范围的图像证据。这通常被表述为“上下文”。在图3中,我们提出了一个简单的人体实验,用户试图对真实和假阳性面部进行分类(由我们的探测器给出)。很明显,人类需要上下文来准确地分类小脸。尽管这种观察在计算机视觉中是非常直观和高度探索的,但众所周知难以量化地证明上下文在识别中的好处。其中一个挑战似乎是如何有效地编码大图像区域。我们证明从多个层提取的卷积深度特征(也称为“超列”特征)是有效的“中心凹”描述符,可捕获大型接收场上的高分辨率细节和粗糙的低分辨率线索(图2(e)) 。我们表明,我们的中心凹描述符的高分辨率成分(从较低的卷积层中提取)对于图5中的这种精确定位至关重要。
 图3:在左侧,我们可视化大小的脸,无论是否有上下文。 一个人不需要上下文来识别大脸,而小脸在没有上下文的情况下会显着无法识别。 我们通过右侧的简单人体实验来量化这一观察结果,用户对我们提出的探测器的真实和假阳性面进行分类。 添加比例上下文(通过将窗口放大3倍)可以在大面积上进行小幅改进,但对于小面孔则不够。 添加300像素的固定上下文窗口可以将小脸上的错误减少20%。 这表明上下文应该以规模变化的方式建模。 我们使用大型接收场的中央凹模板(大约300x300,黄色框的大小)来操作这个观察。
图3:在左侧,我们可视化大小的脸,无论是否有上下文。 一个人不需要上下文来识别大脸,而小脸在没有上下文的情况下会显着无法识别。 我们通过右侧的简单人体实验来量化这一观察结果,用户对我们提出的探测器的真实和假阳性面进行分类。 添加比例上下文(通过将窗口放大3倍)可以在大面积上进行小幅改进,但对于小面孔则不够。 添加300像素的固定上下文窗口可以将小脸上的错误减少20%。 这表明上下文应该以规模变化的方式建模。 我们使用大型接收场的中央凹模板(大约300x300,黄色框的大小)来操作这个观察。
Our contribution
我们提供了对图像分辨率,对象比例和空间背景的深入分析,以便找到小面孔。 我们在大规模基准标记的人脸数据集(FDDB和WIDER FACE)上展示了最先进的结果。 特别是,当与WIDERFACE上的现有技术相比时,我们的结果将误差减少了2倍(我们的模型产生的AP为82%,而现有技术的范围为29-64%)。
相关工作
尺度不变性
绝大多数识别管道都集中在规模不变的表示上,可追溯到SIFT。 当前的检测方法如Faster RCNN也赞同这一理念,通过ROI池或图像金字塔提取尺度不变的特征。 我们提供了对尺度变量模板的深入探索,这些模板以前主要用于行人检测,有时在速度提高的情况下。 SSD是一种基于深度功能的最新技术,它使用了比例变量模板。 我们的工作在探索微小物体检测的背景方面有所不同。
上下文
如多个识别任务所示,上下文是发现小实例的关键。 在对象检测中,在感兴趣区域之外堆叠空间RNN(IRNN)模型上下文并且显示对小对象检测的改进。 在行人检测中,使用地平面估计作为上下文特征并在小实例中改进检测。 在面部检测中,同时在面部和身体周围设置ROI功能以进行评分检测,从而显着提高整体性能。 我们提出的工作以规模变化的方式(相对于)使用大的本地上下文(而不是全局上下文描述符)。 我们证明了上下文对于找到低分辨率的面部非常有用。
多尺度表示
已经证明多尺度表示对于许多识别任务是有用的。 表明深度多尺度描述符(称为“超级列”)对语义分割很有用。 在对象检测中证明了这些模型的改进。 池提供多尺度ROI功能。 我们的模型使用“超列”特征,指出细尺度特征对于定位小物体最有用(第3.1节和图5)。

图5:中心凹描述符对于小物体的准确检测至关重要。 小模板(顶部)仅使用res4执行率降低7%,仅使用res5执行率降低33%。 相反,去除中央凹结构不会伤害大模板(底部),这表明较低层的高分辨率主要用于发现小物体!
RPN
我们的模型非常类似于为特定对象类而不是一般“对象”提议生成器训练的区域提议网络(RPN)。 重要的区别在于我们使用中心凹描述符(通过多尺度特征实现),我们通过交叉验证选择对象大小和方面的范围,我们的模型利用图像金字塔来找到极端尺度。 特别是,我们发现小物体的方法利用了针对插值图像调整的尺度特定探测器。 如果没有这些修改,小脸上的表现会急剧下降超过10%(表1)。
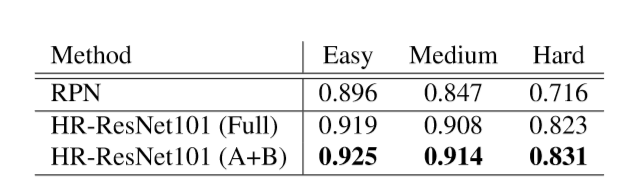
表一:修剪冗余模板不会影响性能(验证)。作为参考,我们还包括第2节中提到的RPN的性能。 有关(完整)和(A + B)的可视化,请参见图9。
Exploring context and resolution
在本节中,我们将对正在发挥作用的问题进行探索性分析,为我们的最终模型提供信息。 为了构思讨论,我们提出以下简单问题:找到固定尺寸(25x20)的小面孔的最佳方法是什么? 通过明确地根据期望的输出分解出尺度变化,我们可以探索上下文和规范模板大小的作用。 直观地说,上下文对于发现小面孔至关重要。 规范模板大小可能看起来像一个奇怪的维度 - 考虑到我们想要找到大小为25x20的面孔,为什么要定义除25x20以外的任何尺寸的模板? 我们的分析给出了一个惊人的答案,说明何时以及为什么要这样做。 为了更好地理解我们的分析的含义,我们还要问一个大对象大小的类似问题:找到固定大小(250x200)的大面积的最佳方法是什么?
设置
我们探索了为固定尺寸(例如,25x20)面部构建扫描窗口检测器的不同策略。 我们将固定大小的物体检测视为二元热图预测问题,其中像素位置(x,y)处的预测热图指定了以(x,y)为中心的固定尺寸检测的置信度。 我们使用完全卷积网络(FCN)在最先进的架构ResNet上定义热像图预测器。 我们探索从ResNet-50的最后一层提取的多尺度特征,即(res2cx,res3dx,res4fx,res5cx)。 我们今后将这些称为(res2,res3,res4,res5)特征。 我们在第5节讨论了我们训练的主要细节。
上下文
图4给出了上下文影响的分析,由用于进行热图预测的接收场(RF)的大小给出。回想一下,对于固定大小的检测窗口,我们可以选择使用与此窗口相比具有任意更小或更大接收字段的特征进行预测。因为较高层的卷积特征倾向于具有较大的接收场(例如,res4特征跨越291×291像素),较小的接收场需要使用较低层特征。我们看到了一些总体趋势。添加上下文几乎总是有帮助,但最终微小面孔(超过300x300像素)的额外上下文会受到伤害。我们确认这是由于过度使用(通过检查培训和测试性能)。有趣的是,较小的接收场对小脸更好,因为整个脸都是可见的 - 如果只寻找鼻尖,很难找到大脸。更重要的是,我们通过比较“紧”RF(限于对象范围)与bestscoring“松散”RF与附加上下文的性能来分析上下文的影响。小面孔的准确度提高了18.9%,而大面积的准确度提高了1.5%,与我们的人体实验一致(这表明背景对于小实例最有用)。我们的结果表明,我们可以为具有相同接收场(大小为291x291)的不同大小的探测器构建多任务模板,这很容易实现为多通道热图预测问题(其中每个规模特定的通道和像素位置都有自己的二进制损失)。在图5中,我们比较了有和没有中心凹结构的描述符,这表明我们的中央凹描述符的高分辨率成分对于小实例的准确检测是至关重要的。

图四:建模其他上下文有助于,特别是对于发现小面孔。 从小面孔(18.9%)增加上下文到紧密模板的改进比大面孔(1.5%)更大。 有趣的是,较小的接收场对小脸更好,因为整个脸部都是可见的。 绿色框表示实际的面部大小,而虚线框表示与来自不同层的特征相关联的接收字段(青色= res2,浅蓝色= res3,深蓝色= res4,黑色= res5)。 在图5和7中使用相同的颜色。
分辨率
我们现在探讨一个相当奇怪的问题。如果我们训练的模板的大小有意地与要检测的目标对象不同,该怎么办?理论上,可以使用“中”大小模板(50x40)在2X上采样(插值)测试图像上找到小面(25x20)。图7实际上显示了令人惊讶的结果,这显着提升了性能,从69%到75%!我们问大面孔的相反问题:通过在测试图像上运行调整为“中”面(125x100)的模板,可以找到大面(250x200),填充2倍吗?再一次,我们看到性能显着提高,从89%提高到94%!一种解释是我们针对不同的对象大小有不同数量的训练数据,并且我们期望具有更多训练数据的那些大小的更好的性能。在“野外”数据集(如WIDER FACE和COCO )中反复观察的是,较小的物体大大超过较大的物体,部分原因是在固定尺寸的图像中标记了更小的物体扫描。对图8中的WIDER FACE进行了验证(灰色曲线)。虽然不平衡数据可以解释为什么使用中等模板检测大面部更容易(因为有更多中等大小的面部用于训练),但它并不能解释小面部的结果。中等面部的培训示例较少,但使用中型模板的性能仍然要好得多。我们发现罪魁祸首在于预训练数据集(ImageNet)中对象尺度的分布。图6显示ImageNet中80%的训练样例包含“中等”大小的对象,介于40到140px之间。具体而言,我们假设预训练的ImageNet模型(用于微调我们的尺度特定探测器)针对该范围内的物体进行了优化,并且应尽可能将规范尺寸模板尺寸偏置在该范围内。我们在下一节中验证了这个假设,我们在这里描述了用于构建具有不同规范分辨率的规模特定探测器的管道。

图6:ImageNet数据集中平均对象比例的分布(假设图像标准化为224x224)。 超过80%的类别的平均对象大小在40到140像素之间。 我们假设在ImageNet上预训练的模型针对该范围内的对象进行了优化。

图7:以原始分辨率构建模板不是最佳选择。 为了找到小的(25x20)面,以2倍分辨率构建模板可将整体精度提高6.3%; 在寻找大面积(250x200)的面部时,0.5x分辨率的建筑模板可将整体精度提高5.6%。

图8:模板分辨率分析。 X轴表示通过聚类导出的目标对象大小。 左Y轴显示每个目标尺寸的AP(忽略具有超过0.5个Jaccard距离的对象)。 自然体系出现在图中:为了找到大面孔(高度超过140像素),以0.5分辨率构建模板; 用于找到较小的面(高度小于40px),以2X分辨率构建模板。 对于介于两者之间的大小,以1X分辨率构建模板。 右Y轴和灰色曲线显示每个对象尺寸在0.5 Jaccard距离内的数据数量,表明更多小面被注释。
方法:特定尺度检测
提出后续问题是很自然的:是否有针对特定对象大小选择模板分辨率的一般策略? 我们证明,人们可以利用多任务学习来“蛮力”训练不同分辨率的几个模板,并贪婪地选择那些做得最好的模板。 事实证明,似乎有一个与我们上一节中的分析一致的一般策略。 首先,让我们来区分一些符号。 我们使用t(h,w,σ)来表示模板。 调整这样的模板以检测分辨率为σ的尺寸(h /σ,w /σ)的物体。 例如,右侧图7使用t(250,200,1)(顶部)和t(125,100,0.5)(底部)来找到250x200个面。 给定图像和边界框的训练数据集,我们可以定义一组大致覆盖边界框形状空间的规范边界框形状。 在本文中,我们通过聚类来定义这样的规范形状,这是基于Jaccard距离d(Eq(1))导出的:
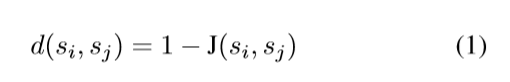
其中,si =(hi,wi)和sj =(hj,wj)是一对边界框形状,J代表标准的Jaccard相似性(在联合重叠上的交叉)。
现在,对于每个目标对象大小si =(hi,wi),我们会问:什么σi将最大化ti的性能(σihi,σiwi,σi)? 为了回答,我们只需为σ∈Σ(某些固定集)的每个值训练单独的多任务模型,并为每个对象大小取最大值。 我们将每个分辨率特定多任务模型的性能绘制为图8中的彩色曲线。对于每个(hi,wi),我们使用最佳σi重新训练一个具有“混合”分辨率的多任务模型(称为HR) ),实际上遵循所有曲线的上限。 有趣的是,存在不同策略的自然制度:找到大型物体(高度大于140px),使用2倍较小的规范分辨率。 要找到小物体(高度小于40像素),请使用2倍大的规范模板分辨率。 否则,使用相同(1X)分辨率。 我们的结果严格遵循ImageNet的统计数据(图6),大多数对象都属于这个范围。
修剪:上一节中的混合分辨率多任务模型有点多余。 例如,模板(62,50,2)是发现31x25面的最佳模板,因为存在模板(64,50,1),这是找到64x50面的最佳模板,因此是多余的。 我们能否删除这些裁员? 是! 我们将读者引用到图9中的标题以获得直观的描述。 如表1所示,修剪冗余模板导致一些小的改进。 基本上,我们的模型可以简化为一组小规模的特定模板(针对40-140px高的面调整),可以在粗糙的图像金字塔上运行(包括2X插值),并结合一组规模特定的模板设计 用于在2X插值图像中找到小面(高度小于20px)。## 标题

图9:修剪掉冗余模板。 假设我们在粗图像金字塔(包括2X插值)上测试以1X分辨率(A)构建的模板。 它们将覆盖更大范围的规模,除了极小的尺寸,最好使用2X的模板检测,如图8所示。因此,我们的最终模型可以简化为两组小规模的特定模板:(A 调整为40140px高的面部并在粗略图像金字塔上运行(包括2X插值)和(B)针对短于20px的面调整,并且仅在2X插值图像中运行。
结构
我们在图10中可视化我们提出的架构。我们训练二进制多通道热图预测器来报告一系列面部尺寸(高度为40-140px)的物体信度。 然后,我们使用粗糙的图像金字塔找到更大和更小的面,其中重要的是包括2X上采样阶段,其具有仅针对该分辨率预测的专用热图(例如,针对短于20像素的微小面设计)。 对于共享的CNN,我们使用ResNet101,ResNet50和VGG16进行了实验。 虽然ResNet101表现最佳,但我们在表2中列出了所有模型的性能。我们看到所有模型都在现有技术的“硬”设置上实现了实质性的改进,包括CMS-RCNN [28],它也模拟了上下文,但是成比例 方式(图3)。
 图10:鉴于我们的检测管道。 从输入图像开始,我们首先创建一个粗糙的图像金字塔(包括2X插值)。 然后我们将缩放的输入馈送到CNN以预测模板响应(用于检测和回归)以获得非常分辨率。 最后,我们在原始分辨率下应用非最大抑制(NMS)以获得最终检测结果。 虚线框表示端到端可训练部分。 我们在粗图像金字塔(包括2X插值)上运行A型模板(针对40-140px高的面调整),而仅在2X插值图像上运行B型(针对小于20px高的面调整)模板(图9)。
图10:鉴于我们的检测管道。 从输入图像开始,我们首先创建一个粗糙的图像金字塔(包括2X插值)。 然后我们将缩放的输入馈送到CNN以预测模板响应(用于检测和回归)以获得非常分辨率。 最后,我们在原始分辨率下应用非最大抑制(NMS)以获得最终检测结果。 虚线框表示端到端可训练部分。 我们在粗图像金字塔(包括2X插值)上运行A型模板(针对40-140px高的面调整),而仅在2X插值图像上运行B型(针对小于20px高的面调整)模板(图9)。
细节:给定具有对象和模板的地面实况注释的训练图像,我们将正面位置定义为IOU重叠超过70%的位置,将负位置定义为重叠低于30%的位置(所有其他位置被零忽略) - 渐变)。请注意,这意味着每个大对象实例比小实例生成更多积极的训练示例。由于这导致了高度不平衡的二元分类训练集,我们利用平衡采样和硬例采样来改善这种效应。我们通过后处理线性回归器来改善性能,该回归器调整了报告的边界框位置。为了确保我们对类似于测试条件的数据进行训练,我们将训练数据随机调整到我们在测试时考虑的Σ分辨率范围(0.5x,1x,2x),并从500x500区域的固定大小随机作物中学习每个图像(利用批处理)。我们在WIDER FACE训练集上进行了精确训练的图像网模型,固定学习率为10-4,并评估WIDER FACE验证集(用于诊断)和保持测试集的性能。为了生成最终检测,我们将标准NMS应用于检测到的热图,重叠阈值为30%。我们在附录B中讨论了我们程序的更多培训细节。我们的代码和模型都可以在https://www.cs.cmu.edu/~peiyunh/tiny在线获得。
实验
WIDER FACE:
我们在WIDER FACE的训练集上训练一个包含25个模板的模型,并在保持的测试集上报告我们最佳模型HR-ResNet101(A + B)的性能。 如图11所示,我们的混合分辨率模型(HR)在所有困难级别上都实现了最先进的性能,但最重要的是,将“硬”设置上的误差降低了2倍。 请注意,“硬”集包括高于10px的所有面,因此更准确地表示完整集上的性能。 我们在图13中的一些具有挑战性的情况下可视化我们的表现。请参考基准网站进行全面评估,并参考附录A进行更多定量诊断。

图11:WIDER FACE“硬”测试集的精确回忆曲线。 与现有技术相比,我们的方法(HR)将误差减少了2倍。
FDDB:
我们在FDDB上测试我们的WIDER FACE训练模型。 我们开箱即用的探测器(HR)输出在离散分数上执行所有已发布的结果,该分数使用标准的50%交叉结合阈值来确定正确性。 因为FDDB在使用边界框的WIDER FACE时使用边界椭圆,所以我们训练一个post-hoc线性回归量来将边界框预测变换为椭圆。 使用post-hoc回归量,我们的探测器在连续得分(测量平均边界框重叠)上也实现了最先进的性能。 我们的回归量训练有10倍交叉验证。 图12绘制了我们的探测器在有和没有椭圆回归器(ER)的情况下的性能。 定性结果如图14所示。 有关我们的椭圆回归器的配方,请参阅我们的附录B.
 图12:FDDB测试的ROC曲线。 我们的预训练探测器(HR)可以产生最先进的离散检测(左)。 通过学习将边界框转换为椭圆形的事后回归量,我们的方法(HR-ER)也会产生最先进的连续性(右)。 我们只比较公布的结果。
图12:FDDB测试的ROC曲线。 我们的预训练探测器(HR)可以产生最先进的离散检测(左)。 通过学习将边界框转换为椭圆形的事后回归量,我们的方法(HR-ER)也会产生最先进的连续性(右)。 我们只比较公布的结果。
 图14:FDDB的定性结果。 绿色椭圆是基础事实,蓝色边界框是检测结果,黄色椭圆是回归椭圆。 我们提出的探测器对于重度遮挡,重度模糊,大外观和尺度变化具有鲁棒性。 有趣的是,许多面临这种挑战的人甚至没有注释(第二个例子)。
图14:FDDB的定性结果。 绿色椭圆是基础事实,蓝色边界框是检测结果,黄色椭圆是回归椭圆。 我们提出的探测器对于重度遮挡,重度模糊,大外观和尺度变化具有鲁棒性。 有趣的是,许多面临这种挑战的人甚至没有注释(第二个例子)。
结论:我们提出了一个简单而有效的框架来发现小对象,证明大型上下文和规模变量表示都是至关重要的。我们特别指出,大规模接收场可以有效地编码为中心凹描述,捕获粗略上下文(检测小物体所必需的)和高分辨率图像特征(有助于定位小物体)。我们还探索了现有预训练深度网络中的规模编码,提出了一种简单的方法,可以在规模变化的方式中将有限尺度的外推网络调整到更极端的场景。最后,我们使用我们对比例,分辨率和背景的详细分析来开发最先进的人脸检测器,该检测器在标准基准测试中的表现明显优于之前的工作。
实验细节
多尺度特征灵感来自训练“FCN-8s一次”的方式,我们通过固定常数来扩展构建在每层之上的预测器的学习速率。 具体来说,我们对res4使用1的缩放因子,对res3使用0.1,对res2使用0.01。 我们的模型与[20]之间的另一个区别在于:我们的模型不是以原始分辨率进行预测,而是预测res3特征的分辨率(与输入分辨率相比,下采样率为8倍)。 输入采样我们首先随机地将输入图像重新缩放0.5X,1X或2X。然后我们从重新缩放的输入中随机裁剪500x500图像区域。 在裁剪图像边界外时,我们使用平均RGB值(平均减法之前)进行填充。
输入采样我们首先将输入图像随机重新缩放0.5X,1X或2X。然后我们从重新缩放的输入中随机裁剪500x500图像区域。 在裁剪图像边界外时,我们使用平均RGB值(平均减法之前)进行填充。
边界情况类似于[18],我们忽略来自热像图位置的渐变,其检测窗口穿过图像边界。 唯一的区别是,我们将填充的平均像素(如输入采样中所述)视为外部图像边界。
在线负挖掘和平衡抽样我们对正面和负面的例子进行挖掘。 我们在分类损失上设置了一个小的阈值(0.03)来过滤容易的位置。 然后我们从剩余的损失高于阈值的那些位置对最多128个位置(正面和负面)进行采样。 我们在表3中比较了有关验证性能的负挖掘和非负挖掘的培训。
损失函数我们的损失函数的表达方式与[18]相同。 请注意,我们还使用Huber loss作为边界框回归的损失函数。
Boundingbox回归我们的边界框回归公式为[18],并使用随机梯度下降与分类共同训练。 我们在WIDER FACE验证集上的有无性能回归测试之间进行比较。
 其中x * c,y * c,r * a,r * b,θ*表示中心x-,y-坐标,地面实况半轴和地面实况椭圆的旋转角度。 xc,yc,h,w表示我们预测的边界框的中心x-,y-坐标,高度和宽度。 我们离线学习边界椭圆线性回归,使用相同的特征训练边界框回归。
其中x * c,y * c,r * a,r * b,θ*表示中心x-,y-坐标,地面实况半轴和地面实况椭圆的旋转角度。 xc,yc,h,w表示我们预测的边界框的中心x-,y-坐标,高度和宽度。 我们离线学习边界椭圆线性回归,使用相同的特征训练边界框回归。
其他超参数我们使用10-4的固定学习率,0.0005的权重衰减和0.9的动量。 我们使用20个图像的批量大小,并从每个图像的重新缩放版本中随机裁剪一个500x500区域。 通常,我们训练50个时期的模型,然后在验证集上选择表现最佳的时期。
论文阅读笔记
当我们在说人脸检测的时候,我们在说什么问题?一个是判断是不是人脸,一个是找到人脸在哪,将这两个问题合在一起就是人脸检测。
1.首先是判断是不是人脸:“是不是”这个问题是一个分类问题,本篇论文通过实验最后采用的是resnet101网络进行分类回归。
2.第二个找到人脸在哪的问题:在一副有多个人脸的图像中,我们一般采用滑动窗口的方式,将边界框滑动识别在框内的是否是人脸。
在上述两个问题的解决过程中,我们发现了由于图像分辨率等原因,小人脸通常难以被检测到,这也是人脸检测中一个具有挑战的问题。小人脸之所以难以检测,基于以下三个问题:目标本身尺度变化,图像分辨率和上下文因素( the role of scale invariance,image resolution and contextual reasoning)。
为了解决这些问题,作者做了三个工作:
解决尺度问题
 (a)图建立了图像金字塔,设置不同尺度的输入图像
(a)图建立了图像金字塔,设置不同尺度的输入图像
(b)图建立了模板金字塔,设置不同尺度的模板
(c)图作者将上述两种方法结合起来,既构建了图像金字塔,又构建了模板金字塔
增加上下文信息
寻找小对象具有根本性的挑战性,因为小对象上几乎没有信号可以利用。因此,作者认为需要使用超出对象范围的图像信息,也就是“上下文”(可以理解为人脸周围的背景信息)。

我们从下图简单的人体实验可以看到增加上下文信息对人脸检测结果的影响。我们可以看出增加上下文能明显的提高人脸检测,尤其是小人连检测的准确率,在模板固定为300px时准确率增加的更为显著。对于大人脸而言,在3倍或固定300px时无太大差别。
多层特征融合
什么是多层特征融合?作者将多层特征融合定义为中心凹描述符。如下图:

设置检测策略
为了找到怎样增加上下文信息和怎样的中心凹特征能使检测更加准确,作者做了以下实验:
1.上下文信息实验:
图:绿色框表示实际的面部大小,而虚线框表示与来自不同层的特征(青色= res2,浅蓝色= res3,深蓝色= res4,黑色= res5)。
从上图我们可以得到:
增加上下文信息可以有助于检测,但是对于小人脸来说,483x483的感受野造成了性能下降,作者认为是过拟合的后果。对于大的人脸,增加感受野固然可以提升准确率,但是提升并不是很多。因此,作者认为不同尺度目标检测都使用同样大小的感受野,即291x291的感受野。
2.多层特征融合实验
从上图我们可以看到,多层信息融合对于小物体的准确检测至关重要。 小模板在只使用res4的情况下准确率降低7%,只使用res5的情况下执行率降低33%。 相反,多层特征融合对大物体不会造成什么影响,这表明较低层的高分辨率主要用于发现小物体。
为特定尺寸目标选择更合适的模板
作者通过实验采用以下方式,如下图:
A:1X 分辨率构建的模板,结合较为稀疏的图像金字塔来检测 40−140 大小的目标;
B:2X 分辨率构建的模板,结合2倍图像差值来检测 20以下的目标;
通过训练作者最后得到了25个模板对应各个分辨率(至于为什么是25个还没太明白)
总流程图
流程图中涉及到的分类网络和NMS算法在基础知识部分有提到。
结果图
在这张很有名的人脸检测图片上,作者检测出了800个人脸(一共1000个人脸)
