学习视频:
鲁鹏-计算机视觉与深度学习
同系列往期笔记:
【学习笔记】计算机视觉与深度学习(1.线性分类器)
【学习笔记】计算机视觉与深度学习(2.全连接神经网络)
【学习笔记】计算机视觉与深度学习(3.卷积与图像去噪/边缘提取/纹理表示)
【学习笔记】计算机视觉与深度学习(4.卷积神经网络)
【学习笔记】计算机视觉与深度学习(5.经典网络分析)
1 视觉识别任务
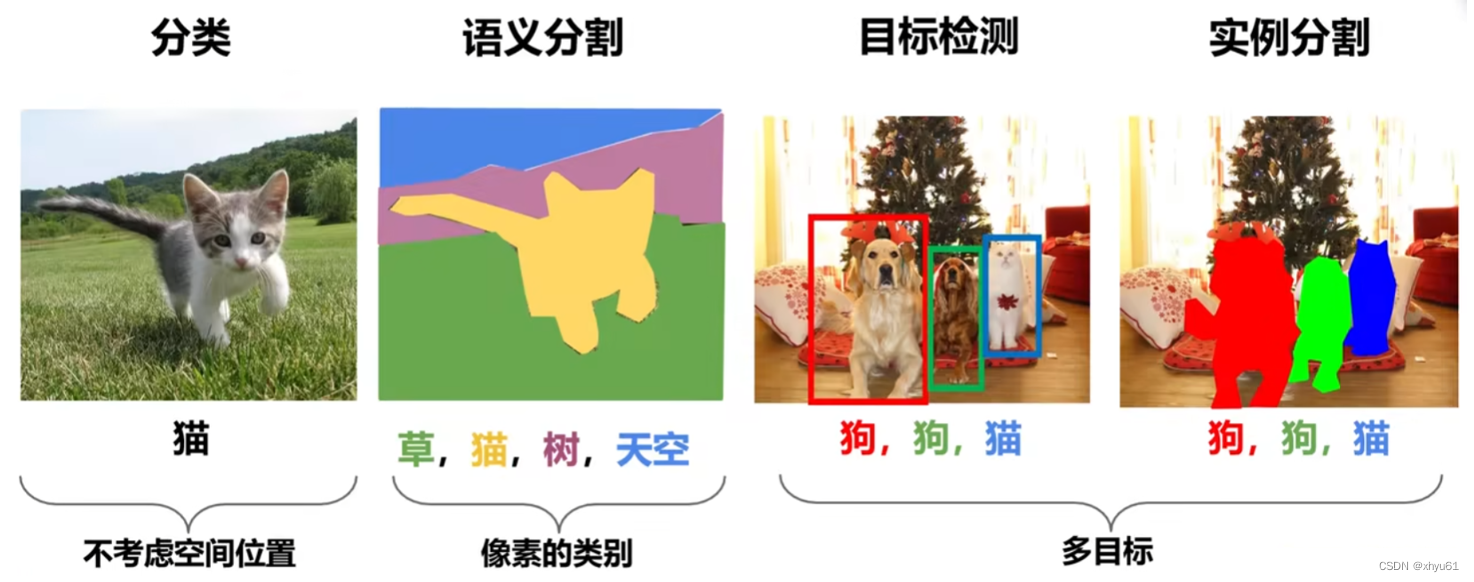
分类:前面讲的全都是分类。
语义分割:将不同的语义标记成不同的颜色,判断像素级的类别,即对于一张图片中的某一个像素,判断出其语义。
目标检测:是一个区域级的分类问题,即将目标所在的区域框选出来。
实例分割:将不同的实例标记成不同的颜色。
语义分割和实例分割的不同之处在于,语义分割是将相同的语义标记成同一个颜色,而实例分割是要区分出不同的实例,如图中所示,两只狗具有相同的语义,但我们在实例分割中需要标记成不同的颜色。
2 语义分割

给每个像素分配类别标签,但不区分实例,只考虑像素类别。
语义分割思路:滑动窗口
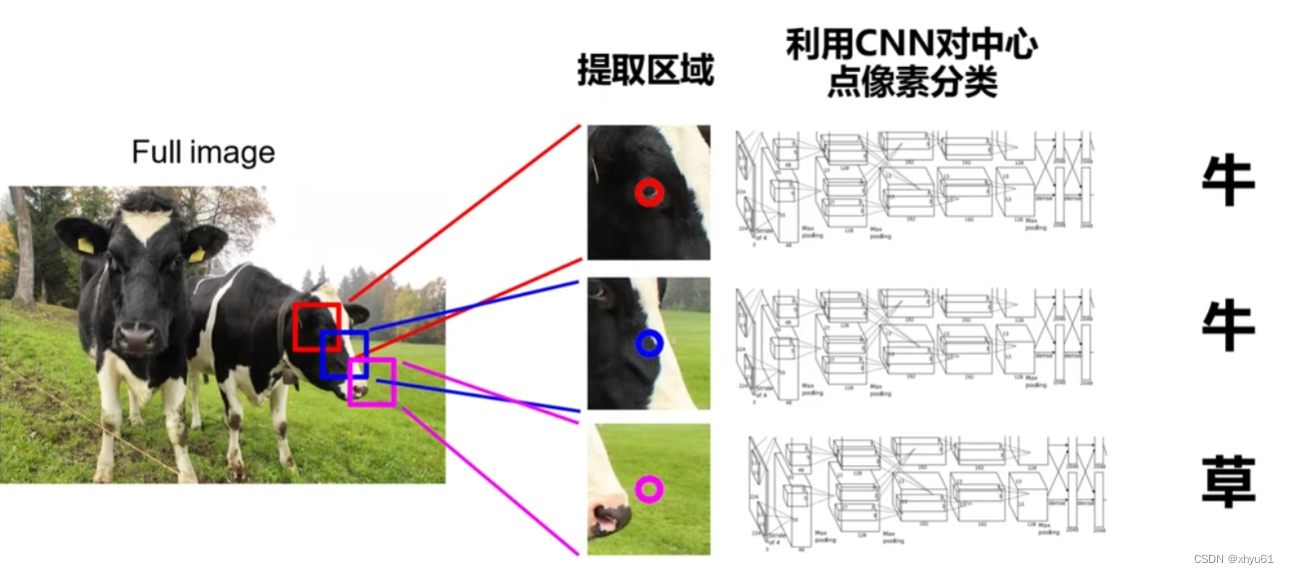
对于一个像素点,我们想要判断他的类别。围绕这个像素点,选取一个窗口,将其作为一个图像,送入神经网络进行分类,那个分类的结果就是这个像素点的结果。
问题 效率太低,重复区域的特征反复被计算。
语义分割思路:全卷积
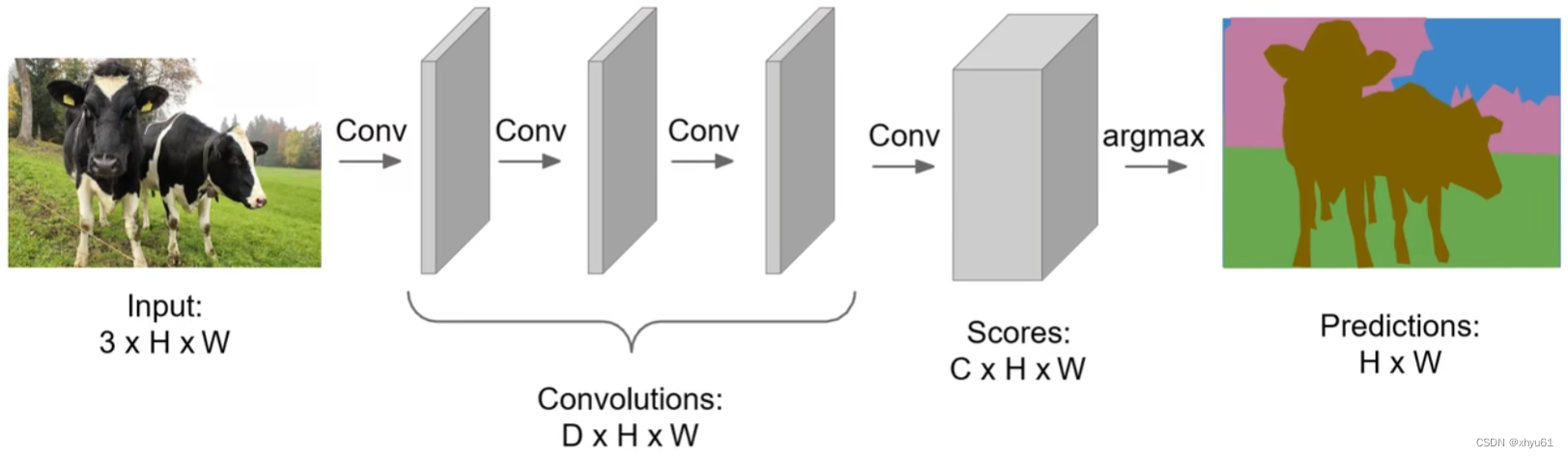
解决方案:让整个网络只包含卷积层,一次性输出所有像素的类别预测。
此时不需要考虑图像的尺寸,我们不需要连接全连接神经网络,没有输入向量维数的限制,所以这个全卷积神经网络,我们输入怎么样的图片大小都可以,卷积层中所有参数都与输入图片的大小无关。
只需要控制最后一个卷积层的深度是 C C C,其中 C C C为类别数。最后我们得到的是一个规模为 H × W × C H\times W\times C H×W×C的特征图组,每一个像素点都有 C C C个结果,对应这个像素点与第 i ( i ∈ [ 1 , C ] ) i(i∈[1,C]) i(i∈[1,C])个类别的相似关系。这样我们取结果最大的那个值所在的类别,就是这个点的分类结果。
学习时不断将结果与标答进行比较计算交叉熵损失,当损失最小时,我们就学好了这个网络。
可以看出,全卷积神经网络有效地降低了计算量,提高了分割效率。
问题:处理过程中一直保持原始分辨率,对于显存的需求会非常庞大。
解决方案:让整个网络只包含卷积层,并在网络中嵌入下采样与上采样的过程。
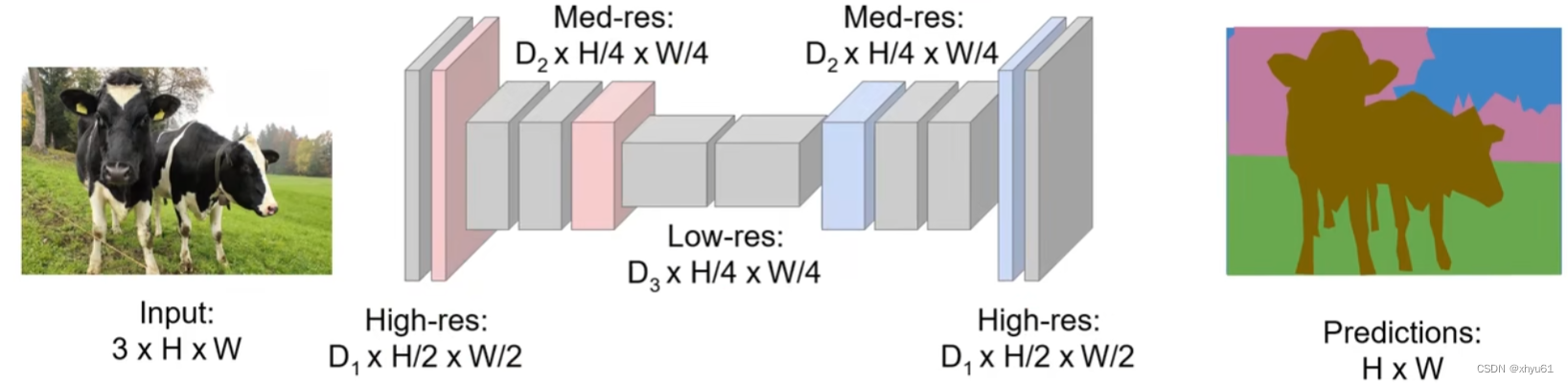
下采样的方法比较多,有池化、增大卷积核步长等。
我们重点讨论上采样。
反池化 Unpooling
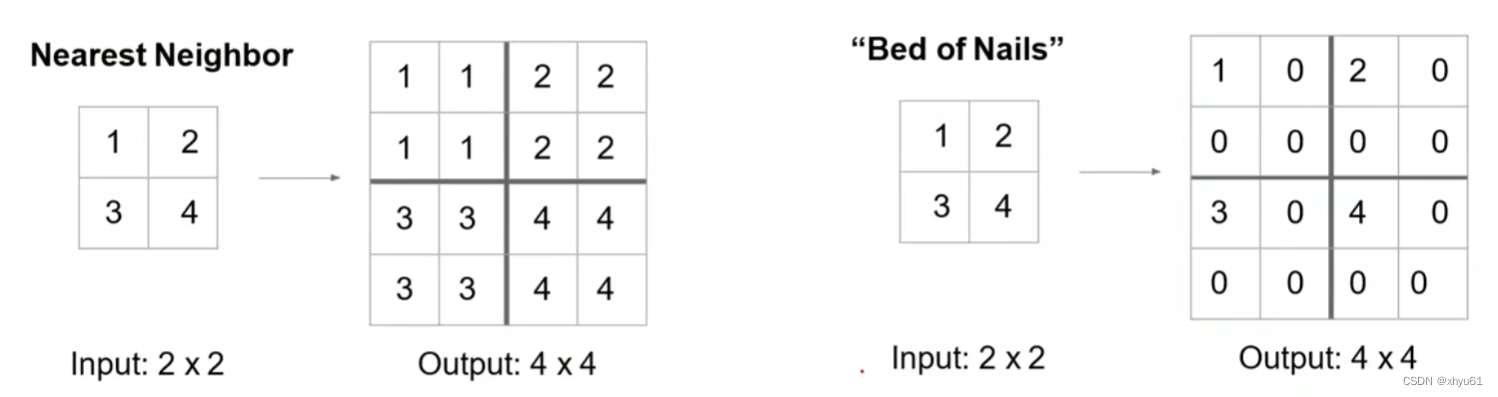
Nearest Neighbor:将对应区域全部填充为与其相同的数值。
Bed of Nails:将对应区域除了原有数值外,全部填充为0。
但上述两种方法由于填充方法可能不够还原原有的图像信息,导致产生很多噪声,所以产生了下面的这种方法:
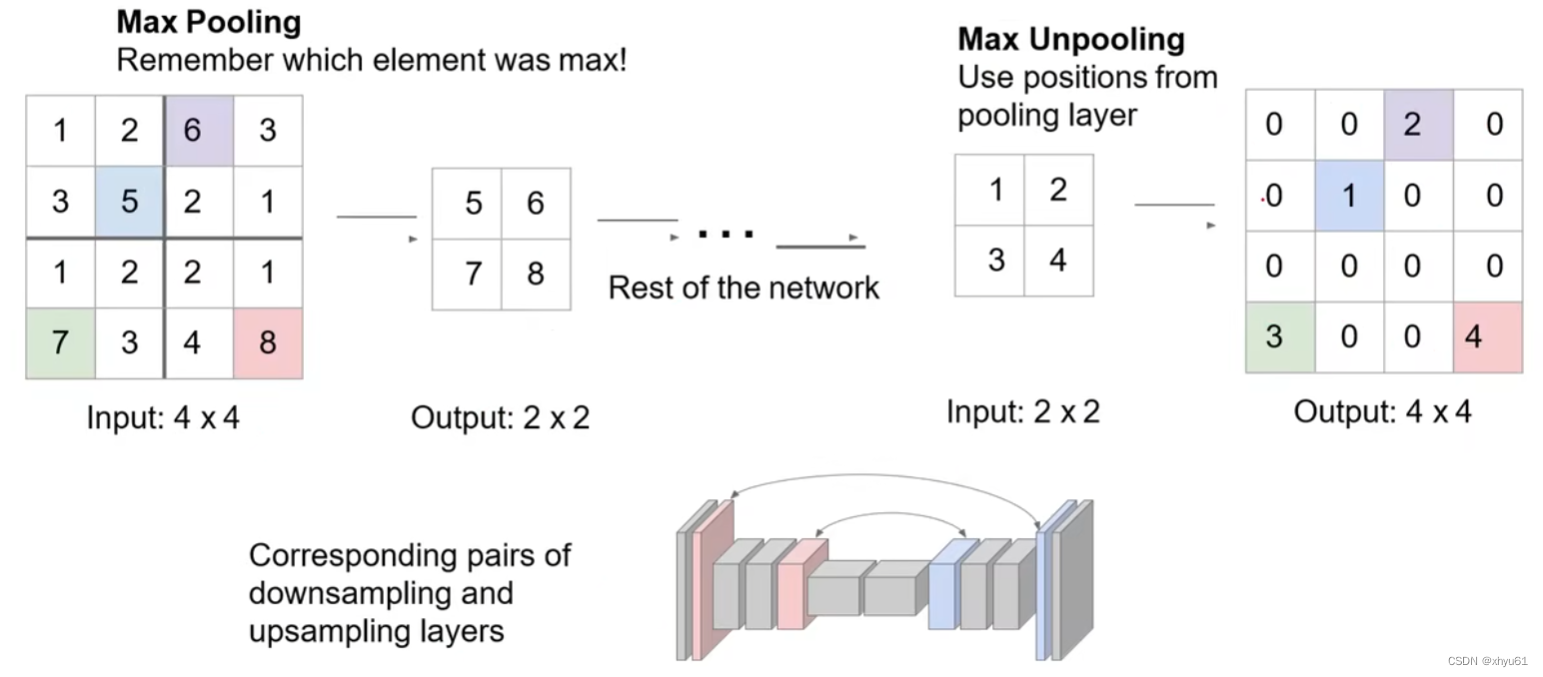
在池化时记录被保留的元素的位置,在反池化时将其还原至原来的位置上,而不是固定位置。
可学习的上采样:转置卷积 (Transpose Convolution)
回顾: 3 × 3 3\times 3 3×3卷积,步长为1,零填充 p = 1 p=1 p=1。
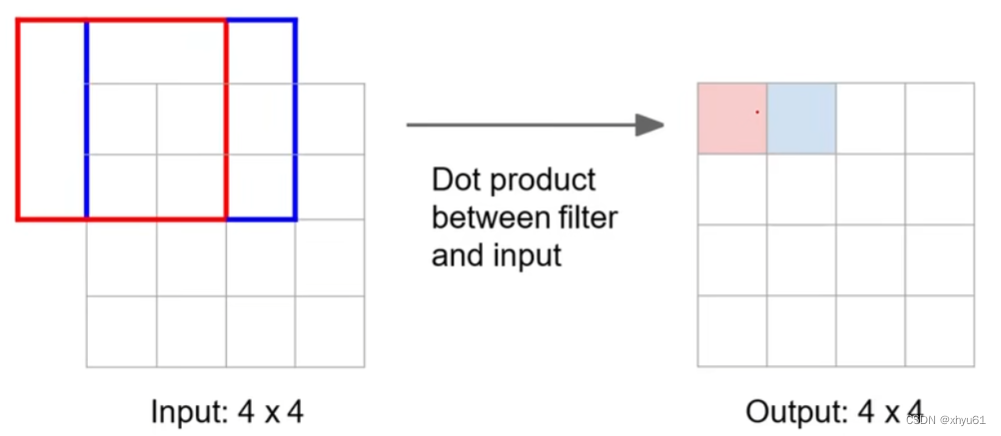
可以发现,红框和蓝框内存在一个共享区域。
回顾: 3 × 3 3\times 3 3×3卷积,步长为2,零填充 p = 1 p=1 p=1。
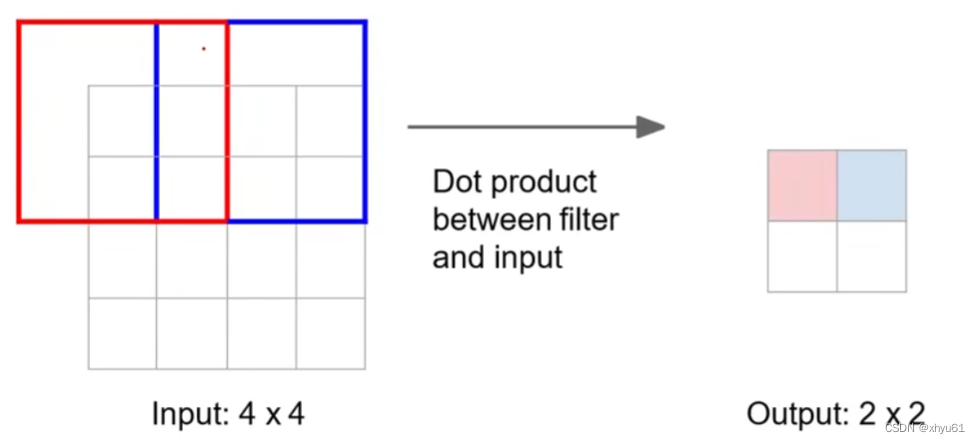
转置卷积,步长为2,零填充 p = 1 p=1 p=1:
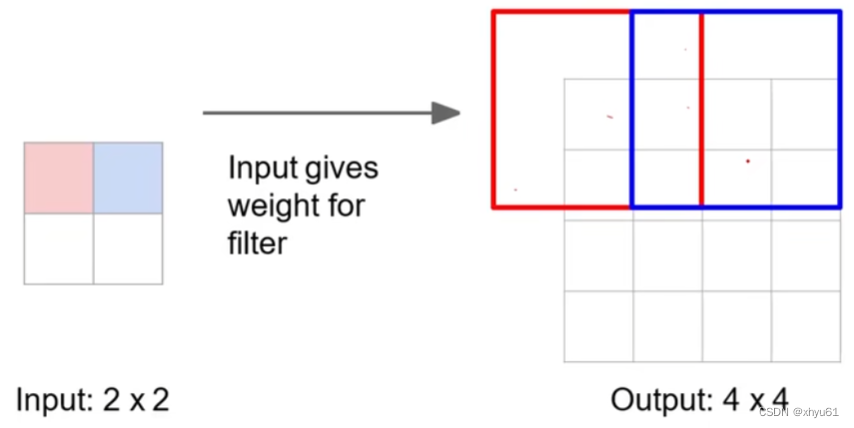
上采样时,输入的红色单元格会给输出的红框内的每一个方格一个值;输入的蓝色单元格会给输出的蓝框内的每一个方格一个值。红框和蓝框有交集单元格,这些位置会被赋予多个值,此时这些值将进行加权求和,而权重,交给机器进行学习。
一个一维的例子:
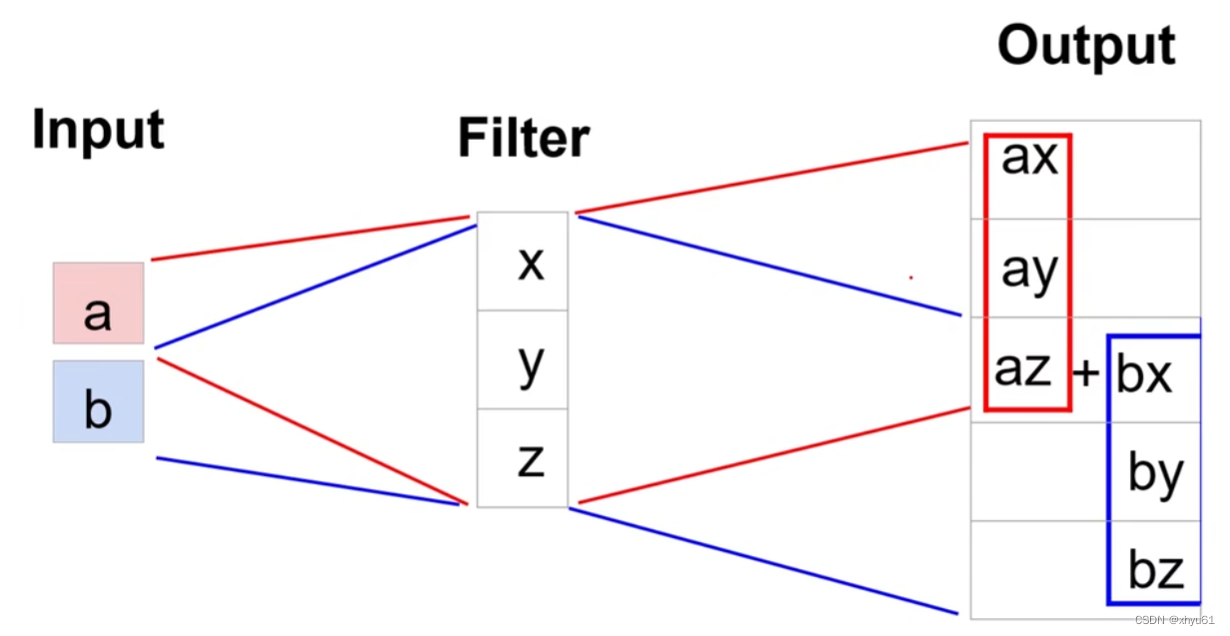
上采样中采取滤波器(Filter),学习时学习滤波器中的参数。
转置卷积的下采样和上采样(一维例子)
将卷积写成矩阵乘法的形式
x ⃗ ∗ a ⃗ = X a ⃗ \vec{x}*\vec{a}=X\vec{a} x∗a=Xa
其中 x ⃗ \vec{x} x是我们要学习的参数, a ⃗ \vec{a} a是我们要处理的一维图像信息。
以卷积核尺寸为 3 3 3,步长为 1 1 1,零填充为 1 1 1,展开来写:
[ x y z 0 0 0 0 x y z 0 0 0 0 x y z 0 0 0 0 x y z ] [ 0 a b c d 0 ] = [ a y + b z a x + b y + c z b x + c y + d z c x + d y ] \begin{bmatrix} x & y & z & 0 & 0 & 0 \\ 0 & x & y & z & 0 & 0 \\ 0 & 0 & x & y & z & 0 \\ 0 & 0 & 0 & x & y & z \\ \end{bmatrix} \begin{bmatrix} 0 \\ a \\ b \\ c \\ d \\ 0 \end{bmatrix}= \begin{bmatrix} ay+bz \\ ax+by+cz \\ bx+cy+dz \\ cx+dy \\ \end{bmatrix}
x000yx00zyx00zyx00zy000z
0abcd0
=
ay+bzax+by+czbx+cy+dzcx+dy
上采样时:
x ⃗ ∗ T a ⃗ = X T a ⃗ \vec{x}*^T\vec{a}=X^T\vec{a} x∗Ta=XTa
展开则为:
[ x 0 0 0 y x 0 0 z y x 0 0 z y x 0 0 z y 0 0 0 z ] [ a b c d ] = [ a x a y + b x a z + b y + c x b z + c y + d x c z + d y d z ] \begin{bmatrix} x & 0 & 0 & 0 \\ y & x & 0 & 0\\ z & y & x & 0 \\ 0 & z & y & x\\ 0 & 0 & z & y\\ 0 & 0 & 0 & z \\ \end{bmatrix} \begin{bmatrix} a \\ b \\ c \\ d \end{bmatrix}= \begin{bmatrix} ax \\ ay+bx \\ az+by+cx \\ bz+cy+dx \\ cz+dy \\ dz \end{bmatrix}
xyz0000xyz0000xyz0000xyz
abcd
=
axay+bxaz+by+cxbz+cy+dxcz+dydz
(上下两个矩阵乘法中的 x , y , z x,y,z x,y,z不是同一个参数,上采样中的 a , b , c , d a,b,c,d a,b,c,d为下采样后卷积结束后得到的结果,也不是第一个矩阵算式中的 a , b , c , d a,b,c,d a,b,c,d)
如果步长为2?
下采样:
[ x y z 0 0 0 0 0 x y z 0 ] [ 0 a b c d 0 ] = [ a y + b z b x + c y + d z ] \begin{bmatrix} x & y & z & 0 & 0 & 0 \\ 0 & 0 & x & y & z & 0 \\ \end{bmatrix} \begin{bmatrix} 0 \\ a \\ b \\ c \\ d \\ 0 \end{bmatrix}= \begin{bmatrix} ay+bz \\ bx+cy+dz \\ \end{bmatrix} [x0y0zx0y0z00]
0abcd0
=[ay+bzbx+cy+dz]
上采样:
[ x 0 y 0 z x 0 y 0 z 0 0 ] [ a b c d ] = [ a x a y a z + b x b y b z 0 ] \begin{bmatrix} x & 0 \\ y & 0\\ z & x\\ 0 & y\\ 0 & z\\ 0 & 0\\ \end{bmatrix} \begin{bmatrix} a \\ b \\ c \\ d \end{bmatrix}= \begin{bmatrix} ax \\ ay \\ az+bx \\ by \\ bz \\ 0 \end{bmatrix}
xyz00000xyz0
abcd
=
axayaz+bxbybz0
语义分割后记
现在在做语义分割时有一种更好的网络UNet,为了降低信息损失,传统UNet将左右镜像对称的部分连起来,让后面的卷积层也包含原始的数据,或将左侧部分进行卷积与右侧部分进行相加操作。这样镜像的信息流可以传递。
3 目标检测
深度学习带来的飞跃
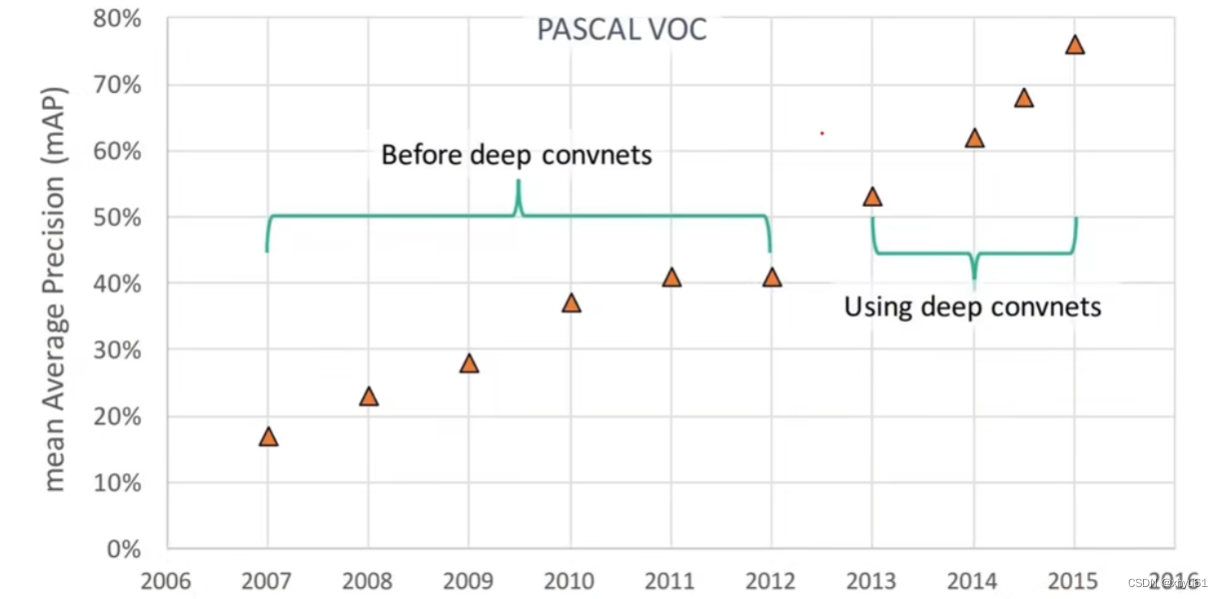
单目标(分类+定位)
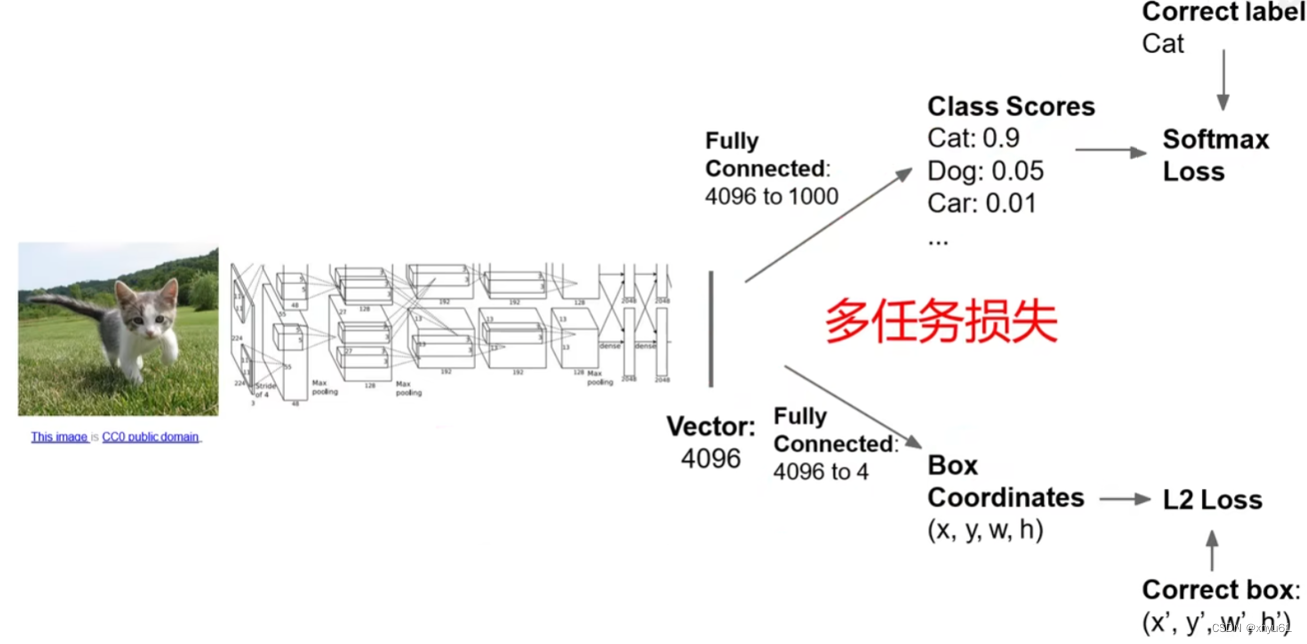
Class Scores是指分类的概率结果,Box Coordinates是指目标位置的坐标与长宽。
前面的模型通常使用在ImageNet上预训练的模型(迁移学习)。
第一阶段,我们训练分类任务部分的参数。
第二阶段,我们锁定第一阶段训练的参数,训练目标定位相关的参数。
第三阶段,我们打开第一阶段的参数,同时训练分类与定位的参数,将多任务的总损失降低至最小。
多目标
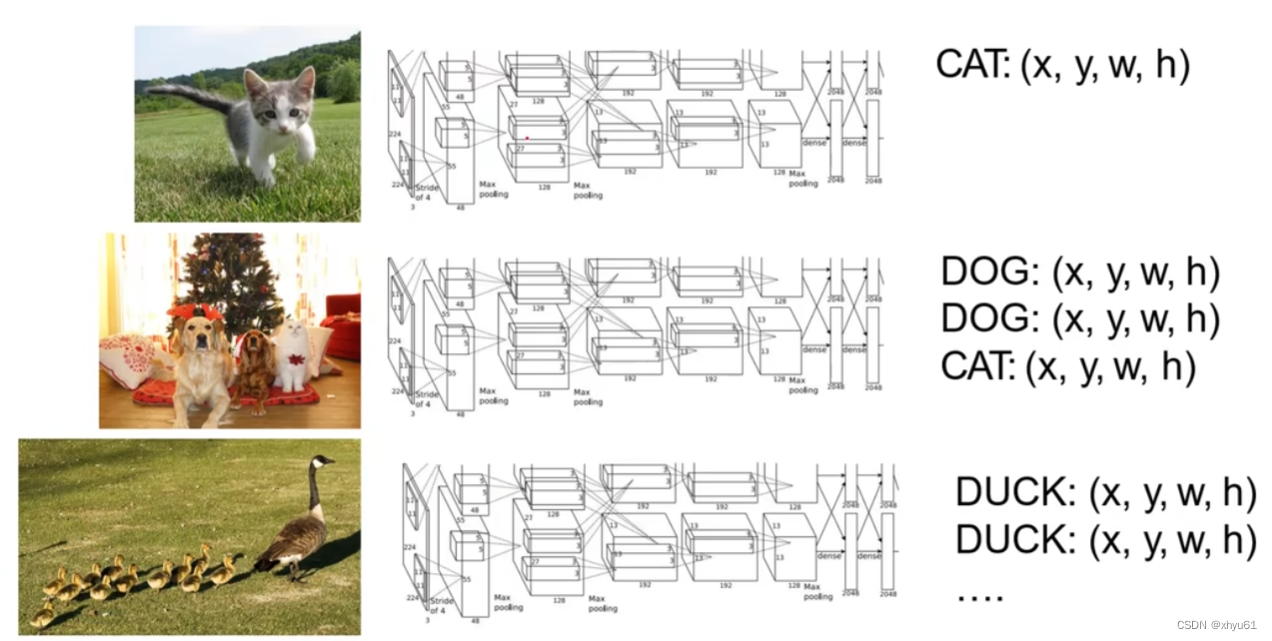
多目标的任务中如果使用单目标的方法则存在问题:
多目标时,我们不能预先知道图片中目标的个数,而目标的个数决定了我们网络输出结果的维数,这个维数是我们开始学习前就要预设好的,此时变成了一个不定量,变得无法实现。
此时我们转换思路。
利用CNN对图像中的区域进行多分类,以确定当前区域是背景还是哪个类别的目标。
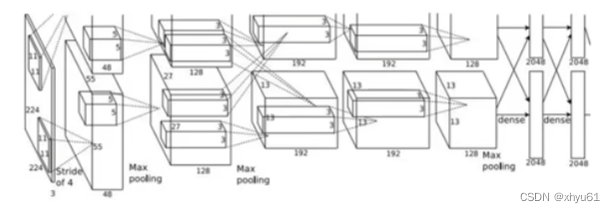

狗:不是;猫:不是;背景:是。

狗:是;猫:不是;背景:不是。

狗:是;猫:不是;背景:不是。

狗:不是;猫:是;背景:不是。

困境 CNN需要对图像中所有可能的区域(不同位置、尺寸、长宽比)进行分类,计算量巨大!
神经网络方法通过穷举所有的可能区域是不现实的,因为一次神经网络的运算花费的时间很长,而穷举区域会穷举出数以百万计的图片数量,运算时间不能接受。
事实上,人脸识别技术使用的Adaboost正是穷举所有可能区域,但不同于神经网络,在人脸识别中,Adaboost非常高效。
区域建议:Selective Search
找出所有潜在可能包含目标的区域;
运行速度需要相对较快,比如Selective Search在CPU上仅需要运行几秒钟就可以产生2000个候选区域。

R-CNN
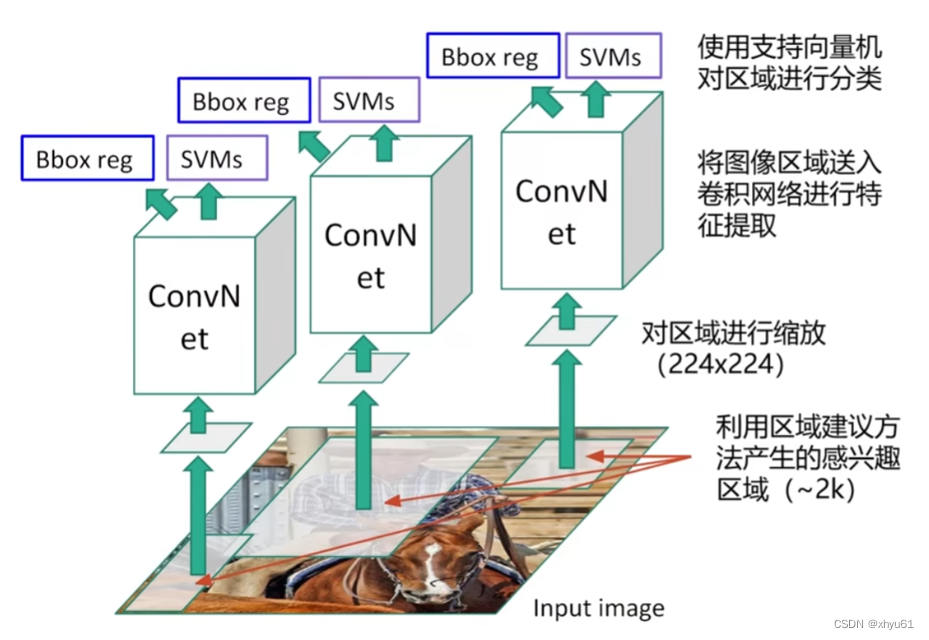
Bbox reg:边框回归,Bounding Box Regression,用于修正Selective Search选择的不佳的边框
R-CNN证明:卷积神经网络用在图像检测上是非常优秀的。
问题:计算效率低下,每一张图像大约有2k个区域需要卷积网络进行特征提取,重复区域反复计算。
想法:在特征图上进行区域扣取。
Fast R-CNN
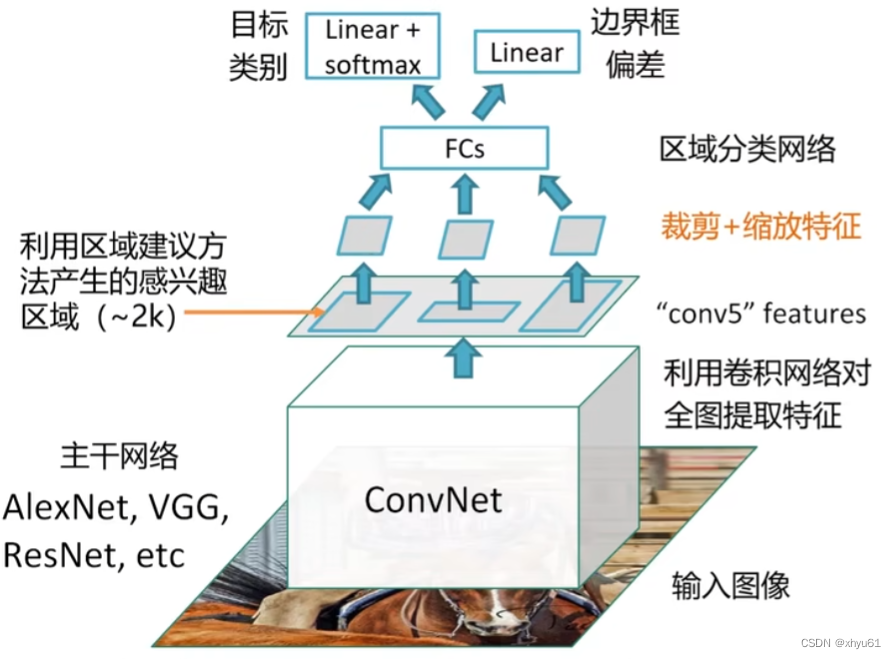
和原先的慢速R-CNN不同的是,Fast R-CNN先进行卷积神经网络的特征提取,然后再进行Selective Search。同时,Fast R-CNN有一步对特征采取裁剪、缩放。整体实现了**端对端(End-to-End)**的网络(中间不需要复杂的流程,一个神经网络全部可以完成),目标分类与边界框偏差是一起通过学习优化的。
该算法的核心就是区域裁剪和区域缩放。
区域裁剪 ROI Pool
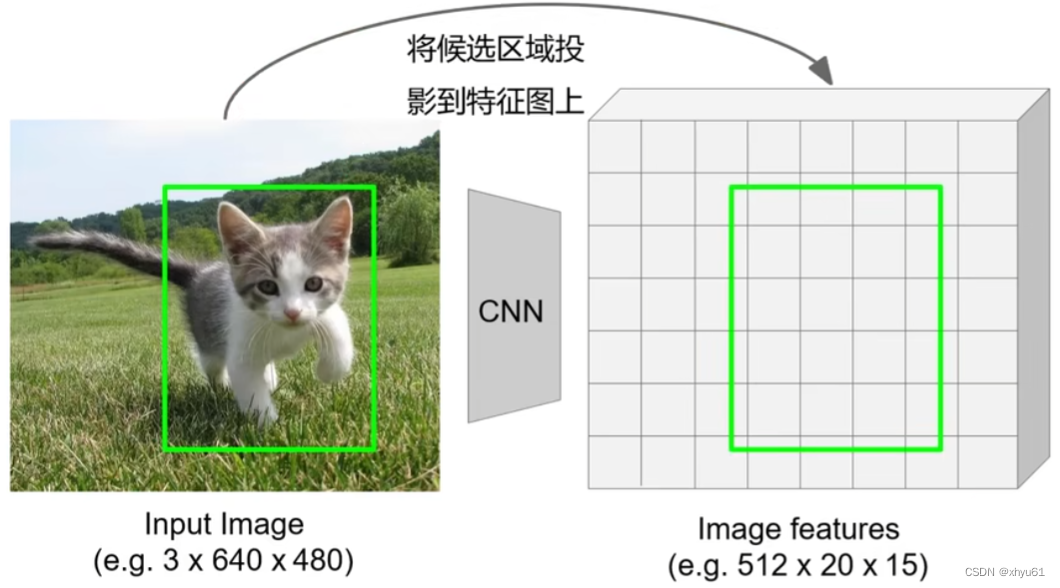
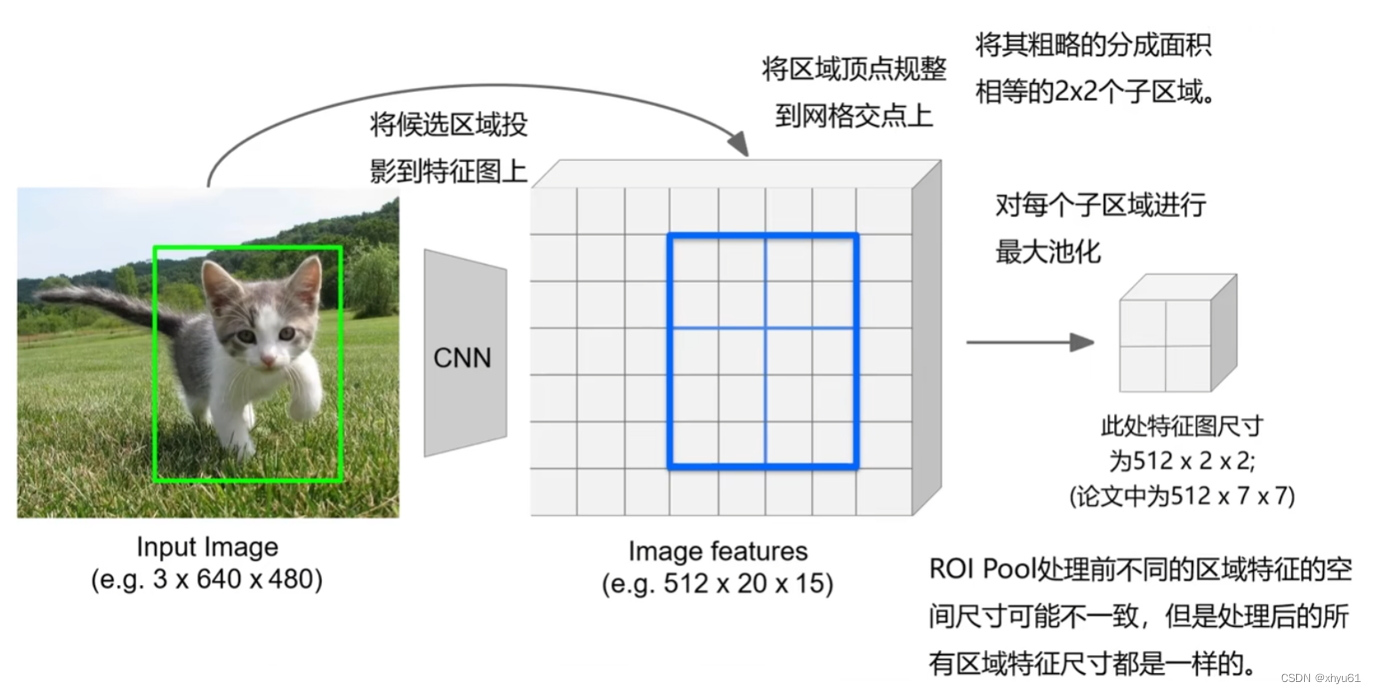
问题:处理后的区域特征会有轻微的对不齐,会影响计算效率和准度。(因为有一步将区域顶点规整到网格交点上)
区域裁剪 ROI Align
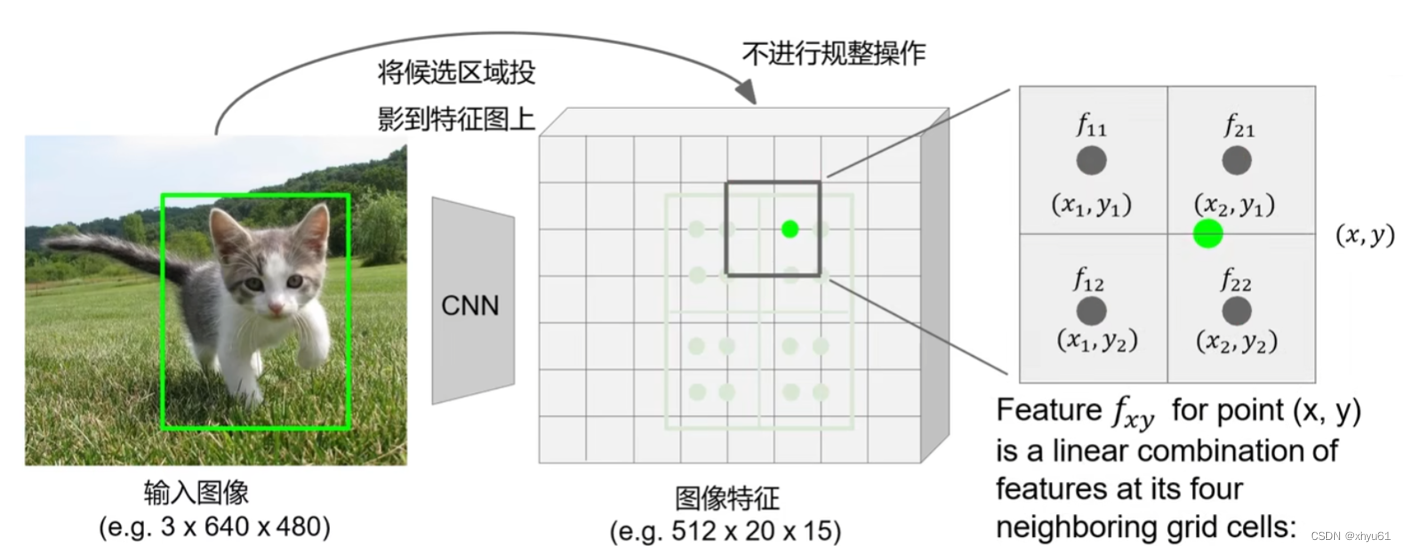
Rol Align不再进行归整操作,而是直接将候选区域平均分为四份,然后在每一份里均匀设计四个点,然后通过双线性插值法计算每个点的值(毕竟不在整数坐标点,通过双线性插值法搞一个近似值)。双线性插值公式如下:
f x y = ∑ i , j = 1 2 f i , j max ( 0 , 1 − ∣ x − x i ∣ ) max ( 0 , 1 − ∣ y − y i ∣ ) f_{xy}=\displaystyle\sum\limits_{i,j=1}^2 f_{i,j} \max(0,1-|x-x_i|)\max(0,1-|y-y_i|) fxy=i,j=1∑2fi,jmax(0,1−∣x−xi∣)max(0,1−∣y−yi∣)

最后依旧是对每一个子区域进行最大池化。
(分4个区域、分4个点都只是例子,这两个也算是一种超参数)
相比于ROI Pooling,不会产生偏移,但是需要进行一步双线性插值才能进行Pooling操作。
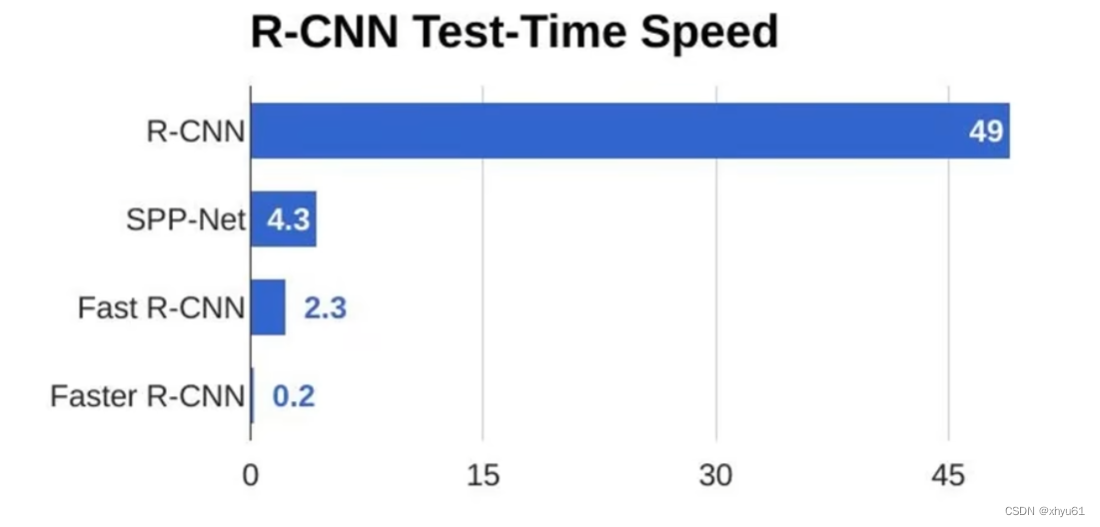
R-CNN vs Fast R-CNN

可以看出,Fast R-CNN仍然需要2.3秒才能处理一张图片,在现实生活中还是不太能够接受。
问题:候选区域产生过程耗时过高,几乎等于单张图片的检测时间。(2.3秒里,近2秒钟都在进行Selective Search)
Faster R-CNN
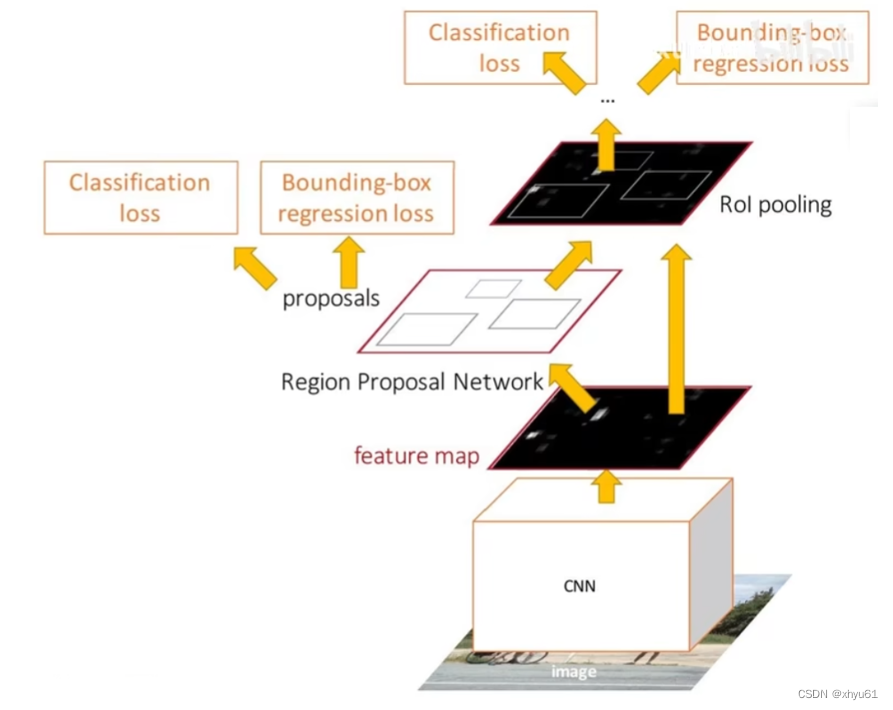
在中间特征层后加入区域建议网络RPN(Region Proposal Network)产生候选区域,其他部分与Fast R-CNN保持一致,然后对其进行分类。
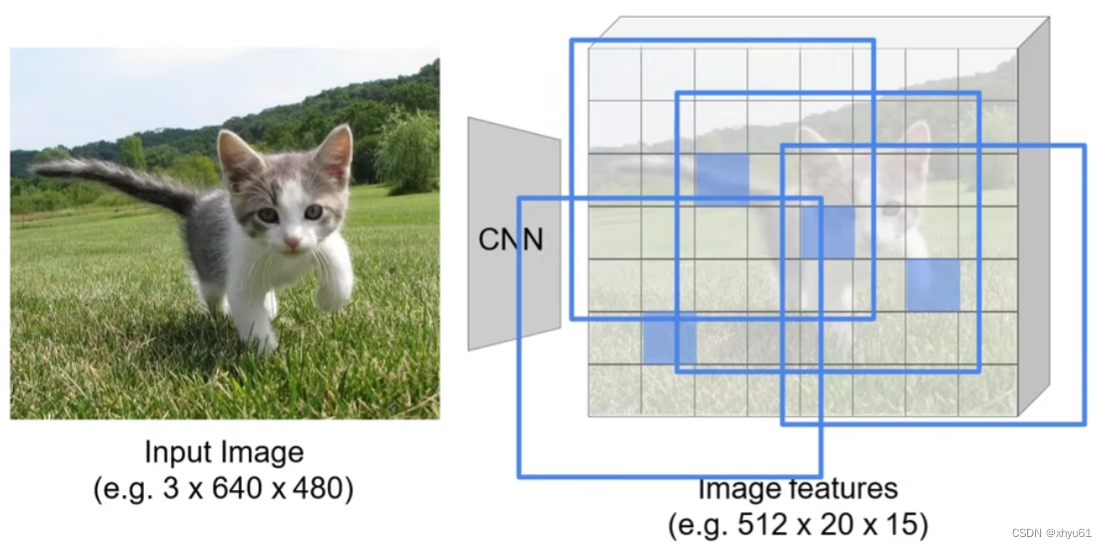
不在原图上进行区域扫描,而是在特征图上进行扫描。通过卷积神经网络变换后,我们会得到尺寸小于原图的特征图组(令步长大于1即可实现),如图所示,特征图上只有300个点,那么我们对300个点进行分类即可。
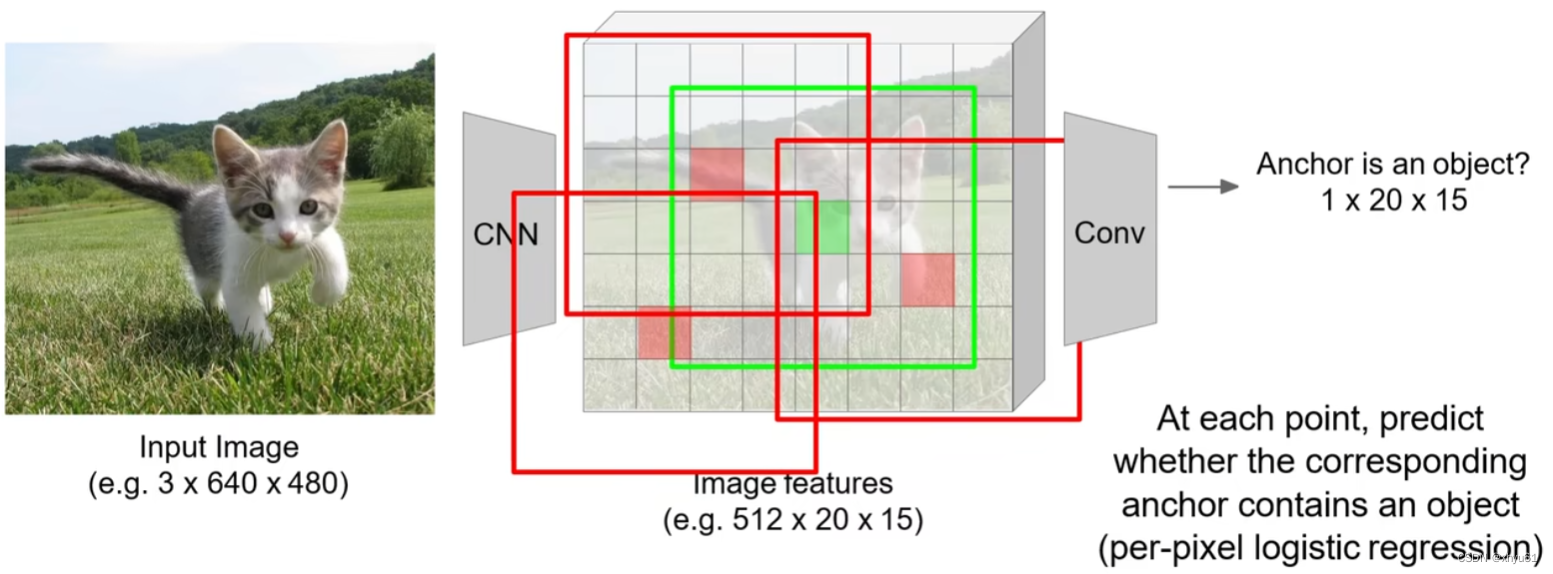
(Anchor为锚点,即图中的框图中心点)
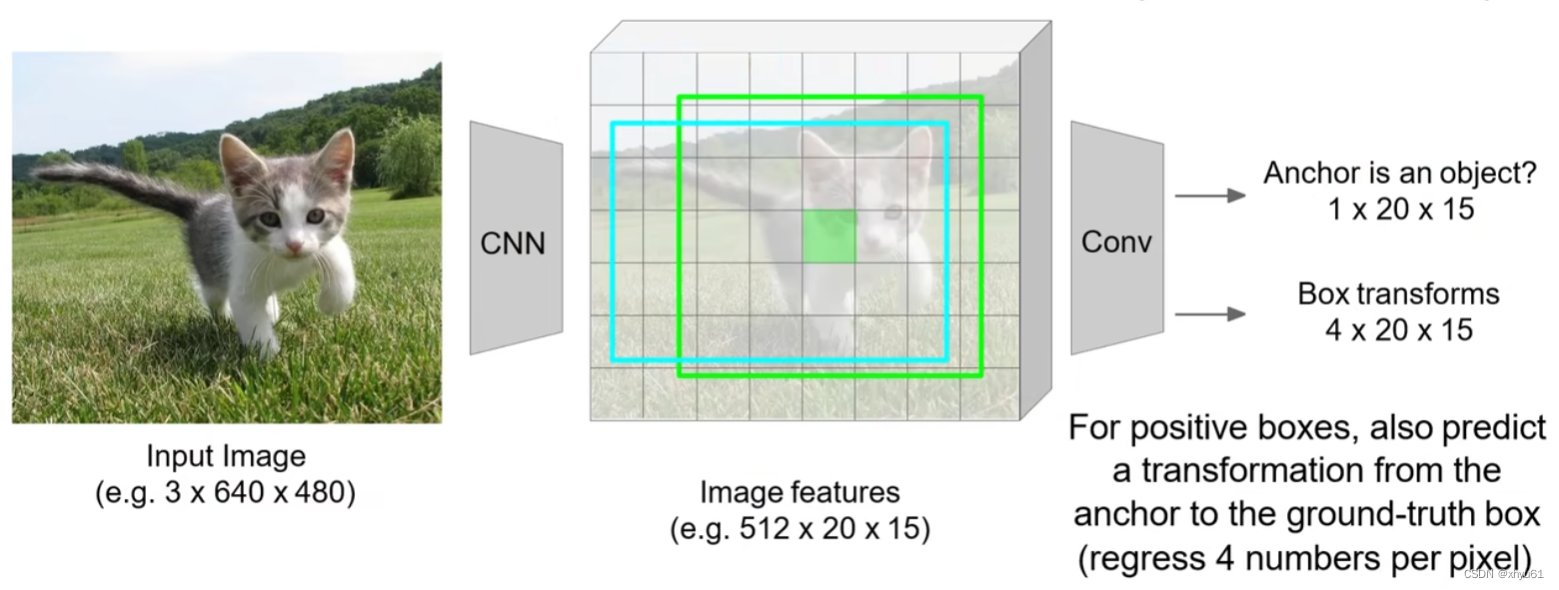
选出边框后,通过边界框回归学习出更优的边框,将这个边框加类别发送至下一层。
问题 框怎么设计?
实际使用中,对于每个特征图上的每个位置,我们通常采用k个不同尺寸和分辨率的锚点区域(anchor boxes)。枚举多种框图(长的、宽的、大的、小的),记录他们的预测结果。
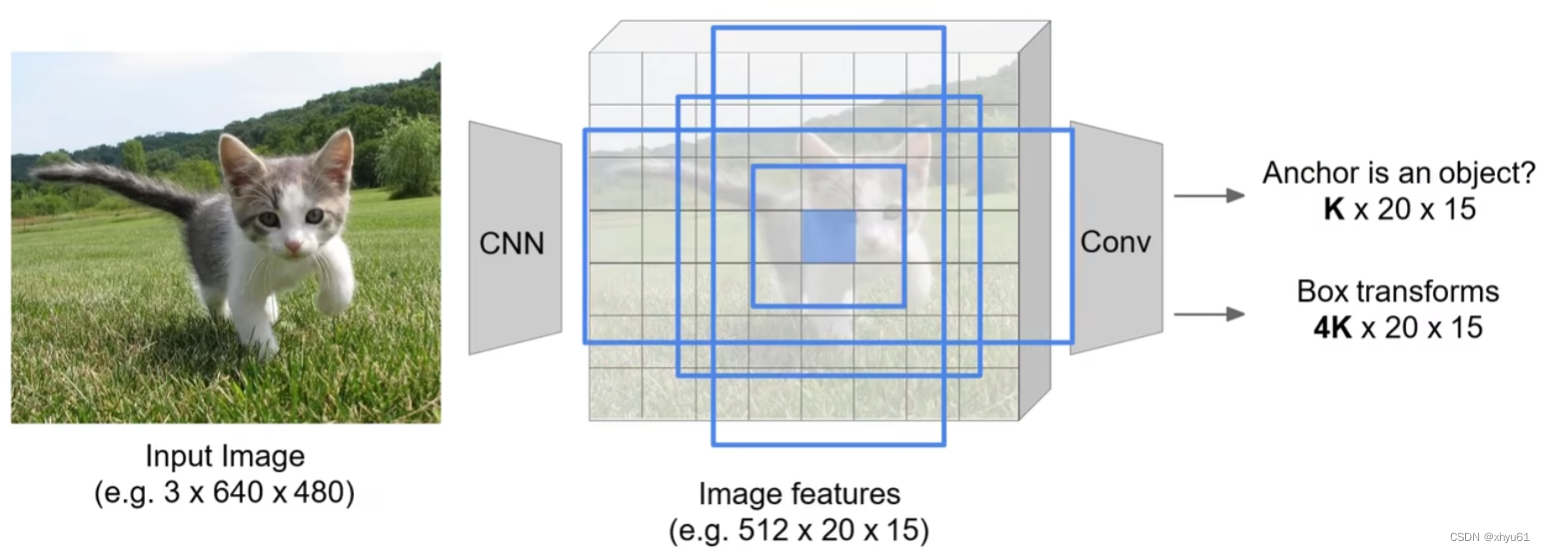
如图所示,特征图尺寸为 20 × 15 20\times 15 20×15,一共会产生 K × 20 × 15 K\times 20\times 15 K×20×15个框图,对每一个框图进行分类,这样每一个框图都会有所有类别的得分,我们会认为框图内的内容是得分最高的类,这个分数暂且称为“最高分”。我们将这 K × 20 × 15 K\times 20\times 15 K×20×15个框图按照其“最高分”进行从大到小排序,选取前 300 300 300个作为建议区域送至下一层。
获得类别得分这件事,是由一个全连接神经网络来做的,而具体的分类方法则和前面所学相同。
可以看出,Faster R-CNN是利用卷积神经网络产生候选区域。其包含4种联合训练:
- RPN分类目标(目标/非目标)
- RPN边界框坐标回归损失
- 候选区域分类损失
- 最终边界框坐标回归损失
总结:
第一阶段:每张图运行一次(主干网络+区域建议网络)
第二阶段:每个区域运行一次(ROI Pooling或ROI Align+预测目标类别+预测边界框偏移量)
问 是否必须采取两个阶段的范式完成目标检测?
一阶段目标检测:YOLO/SSD/RetinaNet
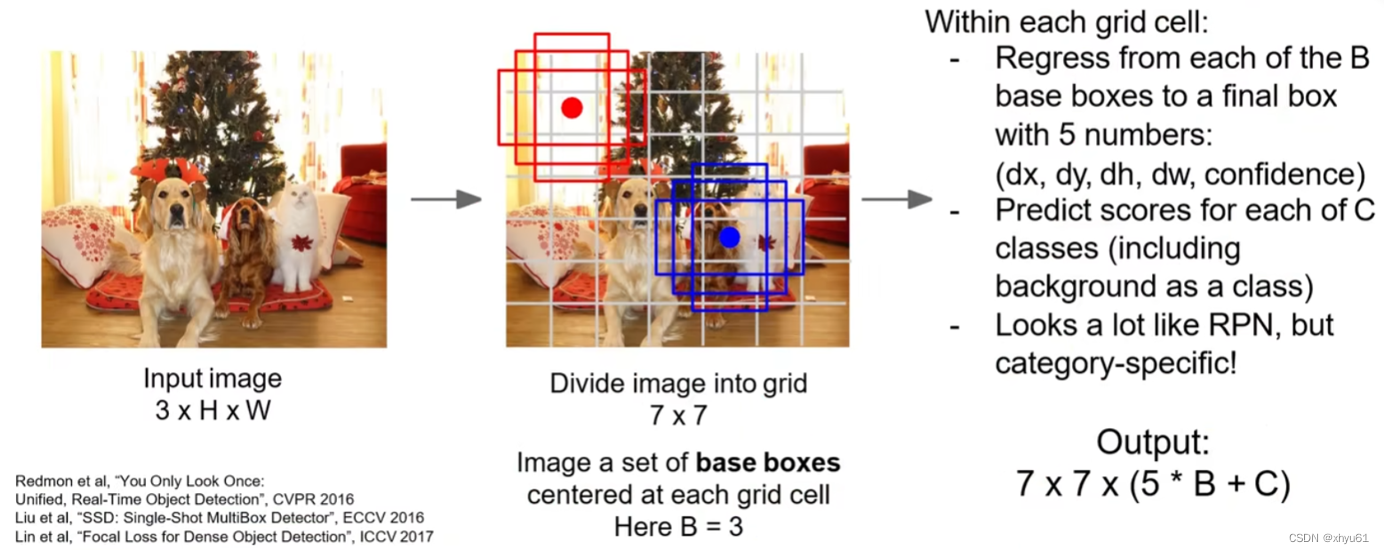
YOLO对图像直接均分成 7 × 7 7\times 7 7×7的网格,对于每一个网格的中心,框出 B B B个边界框,每个边界框有 5 5 5个参数:横坐标、纵坐标、长、宽、置信度。
目标检测:影响精度的因素

主干网络中,MobileNet属于速度较快的网络,在考虑速度时可以选择。
4 实例分割
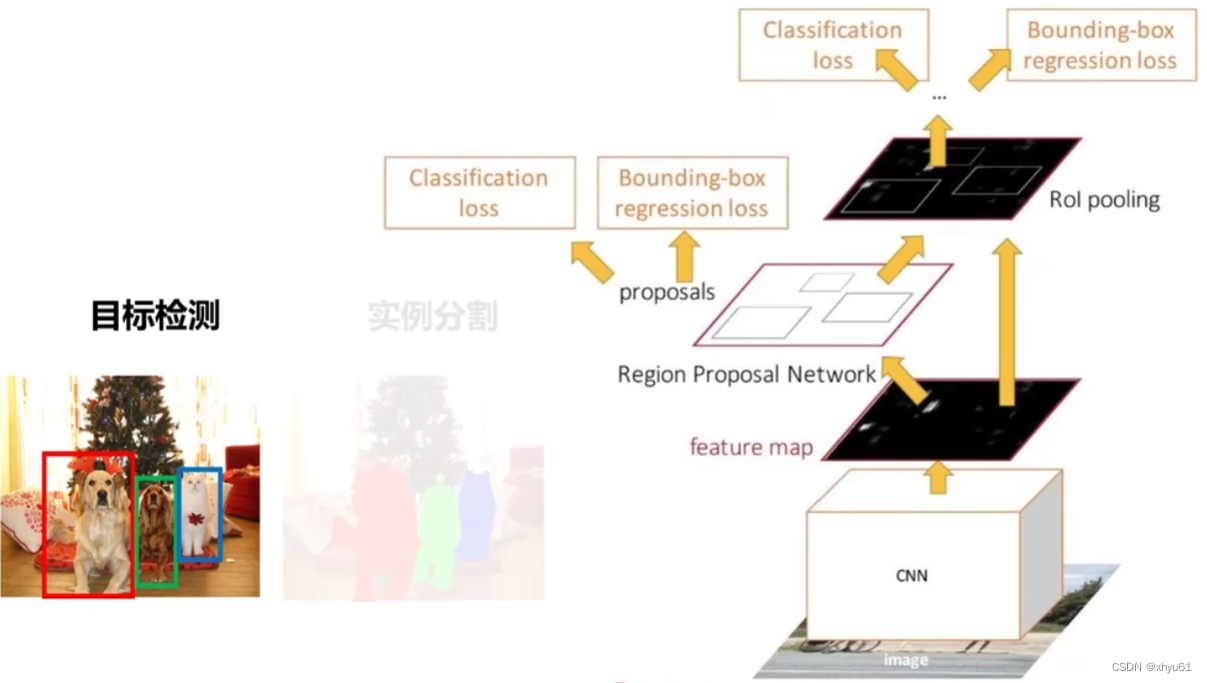
上图为目标检测时所用到的Faster R-CNN。对于实例分割多了一个Mask预测,于是变成了Mask R-CNN。

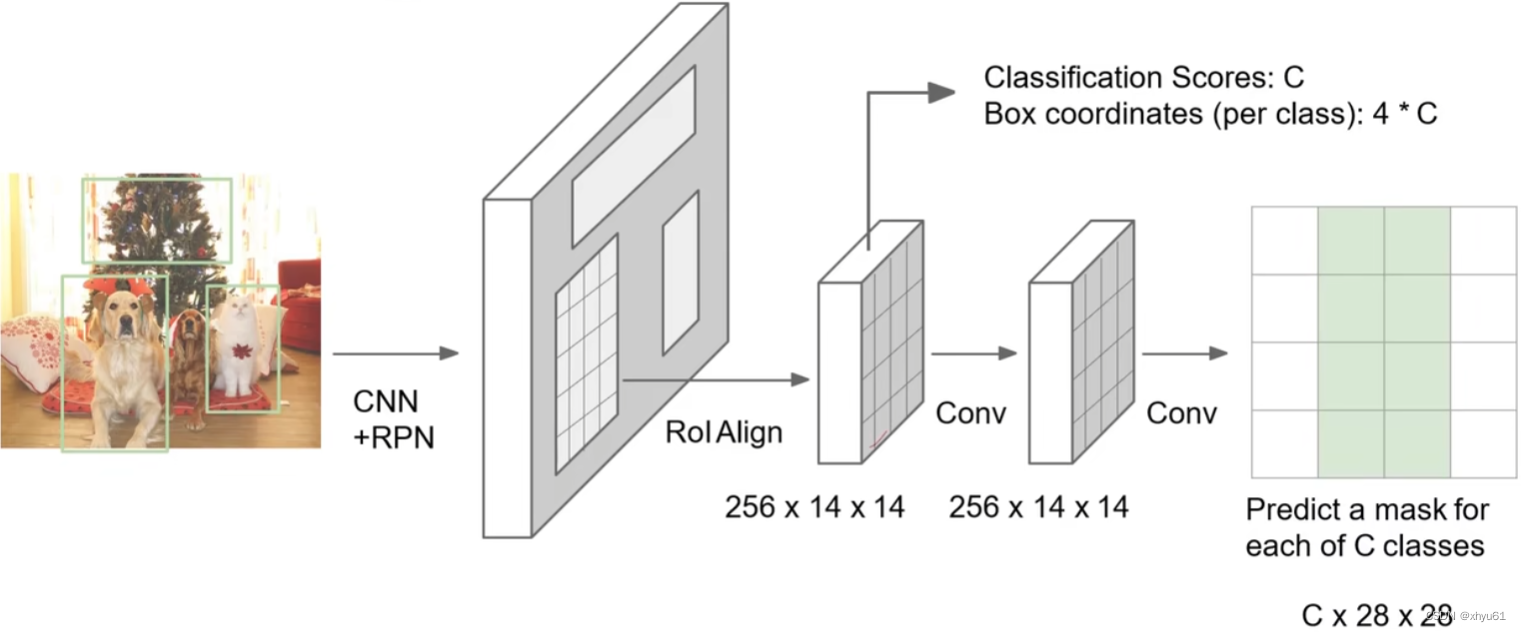
Mask R-CNN训练阶段使用的Mask样例:

Mask R-CNN实例分割结果

Mask R-CNN检测姿态
