CAPAO:一种高效的单阶段人体姿态估计模型
- 重新思考关键点表示:将关键点和姿态建模作为
多人姿态估计的对象(Rethinking Keypoint Representations: Modeling Keypoints and Poses as Objects for Multi-Person Human Pose Estimation)
1. 摘要
- 在人体姿态估计等关键估计任务中,基于热图的回归是主要的方法,尽管存在明显的缺点:热图本质上存在量化误差,需要过多的计算来生成和后处理。
- 为了找到一个更有效的解决方案,我们提出在一个密集基于锚的单阶段检测框架,其将单个关键点和空间相关的关键点(即姿态)建模为对象。因此,我们将我们的方法称为KAPAO(发音为“Ka-Pow”),用于表示关键点并伪装成对象。
- 将KAPAO应用于单阶段多人姿态估计问题,同时检测人姿态和关键点对象,利用两种人姿态表示的优势。在实验中,我们观察到KAPAO比以前的方法更快、更准确,受热图后处理的影响。在实际设置中,当不使用测试时间增强时,精度-速度的权衡特别有利。
论文:https://arxiv.org/pdf/2111.08557.pdf
代码:https://github.com/wmcnally/kapao
效果如下所示,如果想要查看更多视频,可以去源代码仓库查看:

2. 简介
-
估计关键点位置最常用的方法是生成热图(
heat-maps),即在目标关键点坐标上的中心二维高斯分布。然后利用深度卷积神经网络对输入图像上的目标热图进行回归,并通过预测的热图的最大值参数进行关键点预测。 -
上述方法存在的弊端:1.受到输出热图的空间分辨率的限制,热图越大越有利,但是即使使用了大型热图,也需要特殊的后处理步骤来改进关键点预测,从而减缓推理;2.当同一类型(即类)的两个关键点彼此靠近时,重叠的热图信号可能会被误认为是单个关键点。
-
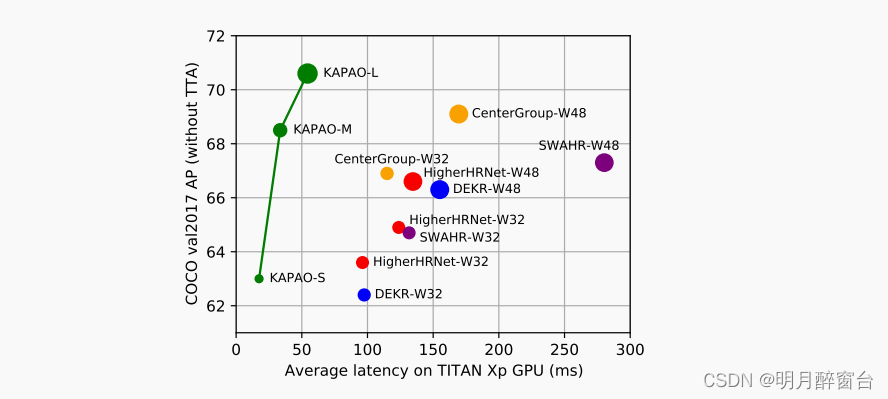
我们引入了一种新的姿态对象表示,以帮助检测空间相关的关键点集。此外,我们同时检测关键点对象和姿态对象,并使用一个简单的匹配算法来融合结果,以利用这两种对象表示的好处。通过对姿态对象的检测,统一了人的检测和关键点估计,提供了一种高效的单阶段多人姿态估计方法,其精度和速度如下图所示:
其中,圆的大小与模型参数的数量成正比
-
由于没有使用热图,KAPAO在准确性和推断速度方面比最近的单阶段人体姿态估计模型要更好,特别是在不使用测试时间增强(TTA)时,这代表了这些模型在实践中是如何部署的。如上所示,KAPAO在没有
TTA的情况下,在微软COCO关键点验证集上实现了70.6的AP,而平均延迟为54.4 ms(转发通过+后处理时间)。与最先进的单级模型HigherHRNet + SWAHR相比,KAPAO在不使用TTA时更快5.1×,更精确3.3 AP。与中心组(The center of attention: Center-keypoint grouping via attention for multi-person pose estimation. In: ICCV (2021))相比,KAPAO更快3.1×,更准确1.5 AP。这项工作的贡献总结如下:-
- 提出了一种新的姿态对象表示方法,它通过包含一组与该对象相关联的关键点来扩展传统的对象表示方法。
-
- 通过同时检测关键点对象和姿态对象,并融合检测结果,提出了一种新的单阶段人体姿态估计方法。在不使用TTA的情况下,所提出的无热图的方法明显比最先进的基于热图的方法更快、更准确。
-
3. 相关工作
3.1 Heatmap-free keypoint detection
- DeepPose [58]使用深度神经网络的级联,直接从图像中回归关键点坐标,迭代地细化关键点预测。此后不久,Tompson等人[57]引入了关键点热图的概念,这在人类姿态估计和其他关键点检测应用中仍然普遍存在。
- 注意到与生成热图相关的计算低效,Li[30]等人解开了水平和垂直关键点坐标,这样每个坐标都使用一个热编码向量表示。这节省了计算量,并允许扩展输出分辨率,从而减少了量化误差的影响,并消除了细化后处理的需要。Li等人[27]引入了残余对数似然(RLE),这是一种基于归一化流[53]的直接关键点回归的新的损失函数。直接关键点回归也已尝试使用
Transformers。
3.2 Single-stage human pose estimation
单阶段人体姿态估计方法使用单个前向通道来预测图像中每个人的姿态。相比之下,两阶段的方法首先使用现成的人检测器(例如,更快的R-CNN [52],YOLOv3 [51]等)来检测图像中的人。然后估计每个检测的姿态。单阶段方法通常不太准确,但通常在拥挤的场景[28]中表现更好,通常因为它们的简单和效率而被首选,随着图像中人数的增加,这变得特别有利。与两阶段方法相比,单阶段方法在设计上的差异更大。例如,它们可以:(i)检测图像中的所有关键点并执行自下而上的分组到人体姿态;(ii)扩展对象检测器以统一人检测和关键点估计;或(iii)使用替代的关键点/姿态表示(例如,预测根关键点和相对位移)。下面,我们将简要总结一下最新的最先进的单阶段方法:
- Cheng等人[7]将
HRNet [54]重新用于自底向上的人体姿态估计,通过添加一个转置卷积来加倍输出热图分辨率(HigherHRNet),并使用关联嵌入[42]进行关键点分组。他们还实施了多分辨率训练来解决尺度变化问题。 - Geng等人的[12]使用
HRNet骨干预测了人中心热图和2K个偏移图,分别表示以每个像素为中心的候选姿态的K个关键点的偏移向量。他们还使用单独的回归头和自适应卷积来解开关键点回归(DEKR)。 - Luo等人[35]以
HigherHRNet为基础,提出了尺度和权重自适应热图回归(SWAHR),该回归基于人尺度对地面-真实热图高斯方差进行缩放,并平衡前景/背景损失加权。他们的修改提供了比HigherHRNet的显著精度改进,以及与许多两阶段方法相当的性能。再次使用HigherHRNet作为基础, - Bras‘o等人[3]提出中心小组使用一个完全可区分的自我注意模块,端到端训练与关键点检测器。
- 值得注意的是,上述所有方法都遭受了昂贵的热图后处理,因此,它们的推理速度还有很多不足之处
3.3 Extending object detectors for human pose estimation
目标检测任务与人体姿态估计任务之间存在显著的重叠。例如:
- He等人[14]使用
Mask R-CNN实例分割模型,通过使用一个热掩模预测关键点来进行人体姿态估计。 - Wei等人[64]提出了点集锚,它采用了视网膜网[32]目标探测器。
- Zhou等人。[70]使用基于热图的中心点和中心网建模对象,并将姿态表示为中心点的2k维属性。
- Mao等人[36]使用动态滤波器[21]使用
FCPose调整了FCOS [56]对象检测器。虽然这些基于目标探测器的方法提供了良好的效率,但它们的精度并没有与最先进的基于热图的方法竞争。 - 我们的工作最类似于点集锚点[64];然而,我们的方法不需要定义依赖于数据的姿态锚点。此外,我们同时检测单个关键点和姿态,并融合检测,以提高我们最终姿态预测的准确性。
4. KAPAO: Keypoints and Poses as Objects
- KAPAO使用一个密集的检测网络来同时预测一组关键点对象和一组姿态对象.
- 这两种对象表示法都具有独特的优势。关键点对象专门用于检测具有强局部特征的单个关键点。在人类姿态估计中常见的这些关键点的例子包括眼睛、耳朵和鼻子。然而,关键点对象不携带关于人或姿势概念的信息。如果单独用于多人的人体姿态估计,将需要一种自下而上的分组方法来将检测到的关键点解析为人体姿态。相比之下,姿态对象更适合于定位具有弱局部特征的关键点,因为它们使网络能够学习一组关键点内的空间关系。此外,它们可以直接用于多人的人体姿态估计,而不需要自下而上的关键点分组。
- 认识到关键点对象存在于姿态对象的子空间中,KAPAO网络被设计为使用单个共享网络头以最小的计算开销同时检测两种对象类型。在推理过程中,使用一种简单的基于公差的匹配算法,将更精确的关键点对象检测与人体姿态检测进行融合,该算法在不牺牲任何大量推理速度的情况下,提高了人体姿态预测的准确性。下面的部分详细介绍了网络架构、用于训练网络的损失函数和推理。
4.1 Architectural Details
- 下图提供了模型的算法结构,它使用一个深度卷积神经网络N映射
RGB输入图像I(hxwx3)到一组特征金字塔(分别按照8、16、32、64进行采样),其中N为多任务损失L训练的密集检测网络,然后利用非极大值一直(NMS)获得候选检测结果:姿态和关键点,并利用匹配算法将其融合在一起,获取最终的人体姿态预测结果P。
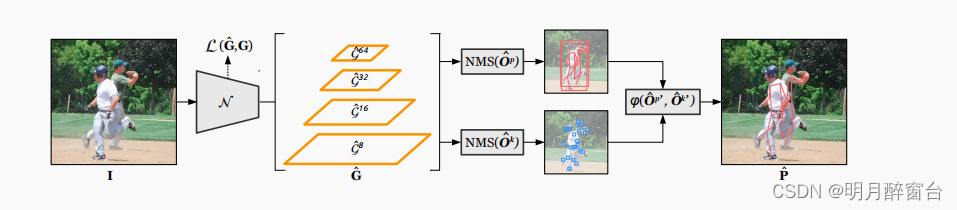
- N是一个YOLO风格的特征提取器,在特性金字塔[31]宏体系结构中广泛使用跨阶段-部分(CSP)瓶颈。为了为不同的速度要求提供灵活性,通过缩放N中的层数和通道数,我们训练了三种尺寸的KAPAO模型(即KAPAO-S/M/L)。
- 此处翻译时公式比较难打,直接附上原图:



4.2 Loss Function


4.3 Inference

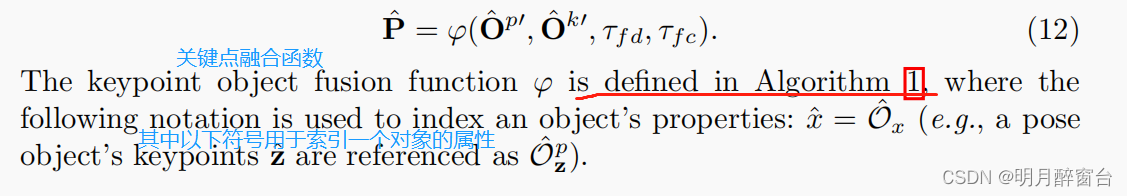

4.4 Limitations

5. Experiments
5.1 Microsoft COCO Keypoints
训练时:
- KAPAO-S/M/L都在2017年COCO列车上训练了500个周期,使用内斯特罗夫动量的随机梯度下降,权重衰减,学习速率在单余弦周期上衰减.
- 输入的图像被调整大小并填充到1280×1280,保持原来的长宽比。在训练过程中使用的数据增强包括马赛克[2]、HSV颜色空间扰动、水平翻转、平移和缩放。
- 许多训练超参数都继承自[23,61],包括锚盒A和减重量w、λobj、λbox和λcls。其他的,包括关键点边界框大小bs和关键点损失权重λkps,都是使用小网格搜索手动调整的。
- 这些模型在4个v100gpu上进行训练,每个gpu有32 GB内存,批处理大小分别为128、72和48分别是KAPAO-S、M和L。在每个历元之后进行验证,保存提供最高验证AP的模型权重。
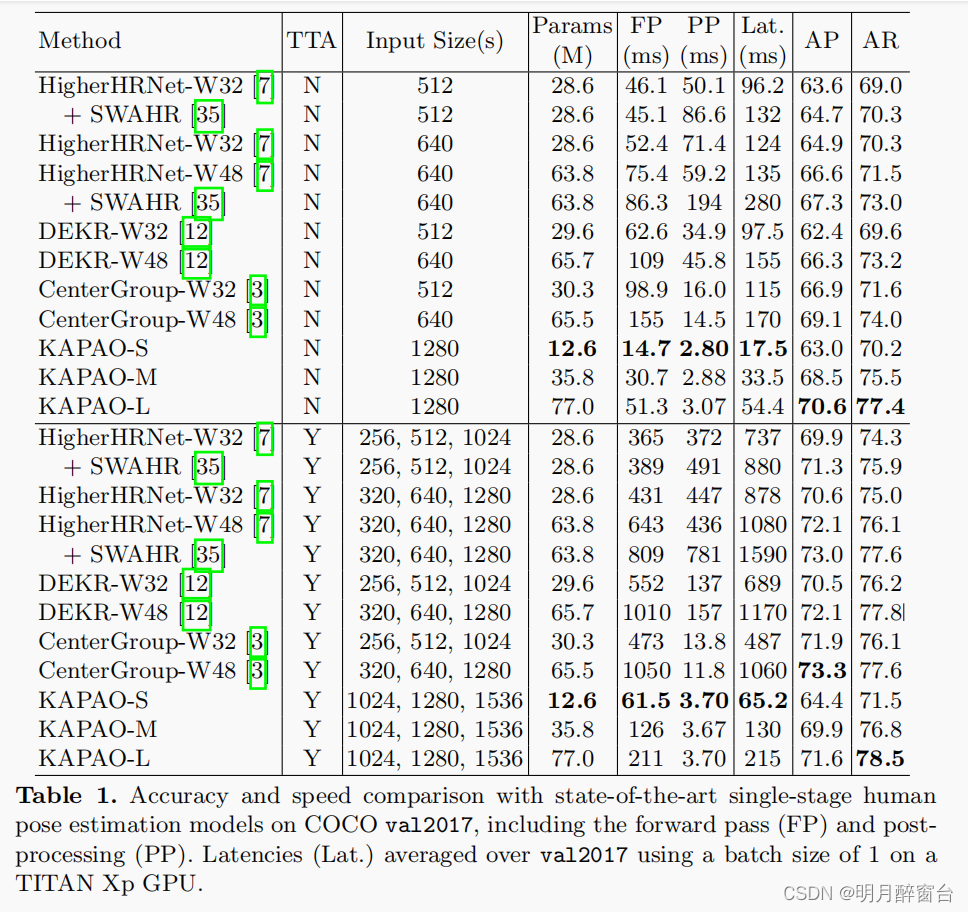
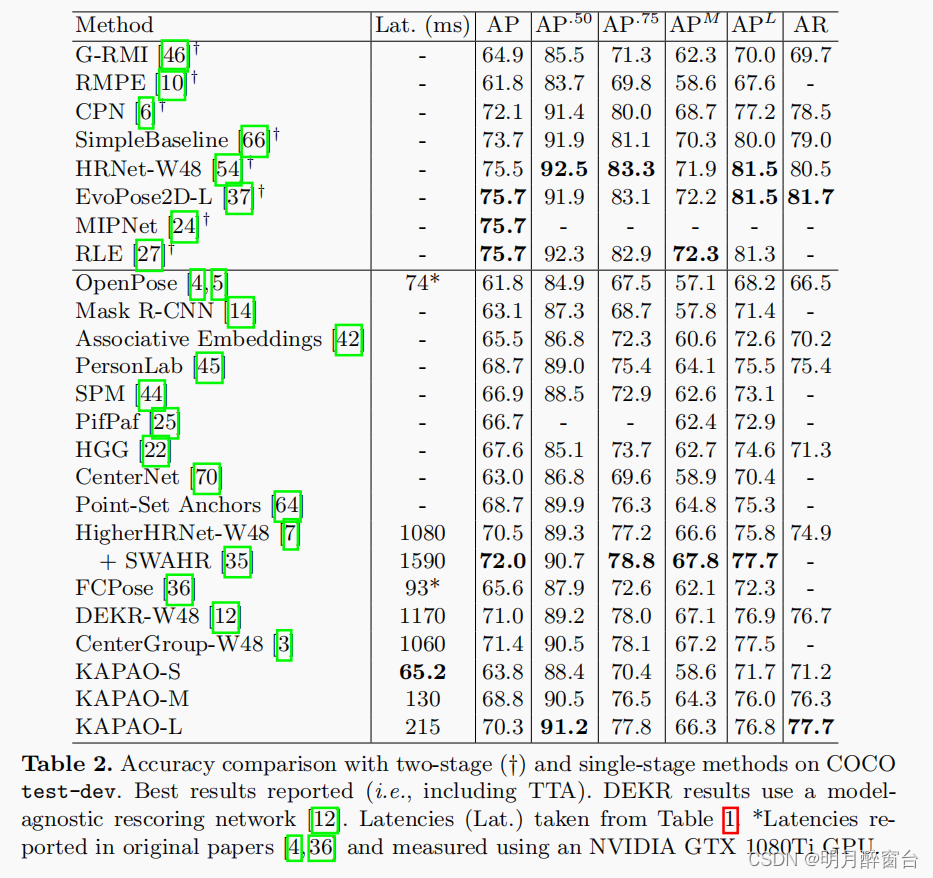
测试结果直接放表格吧:
5.1 CrowdPose
人群中的姿势:
- 研究发现,在之前的单阶段方法相比,KAPAO在存在遮挡方面表现突出,在所有指标上都取得了竞争性的结果,以及AP的最先进的准确性。
- 在拥挤场景中的熟练程度是明显的,更多遮挡情况下准确度更高。
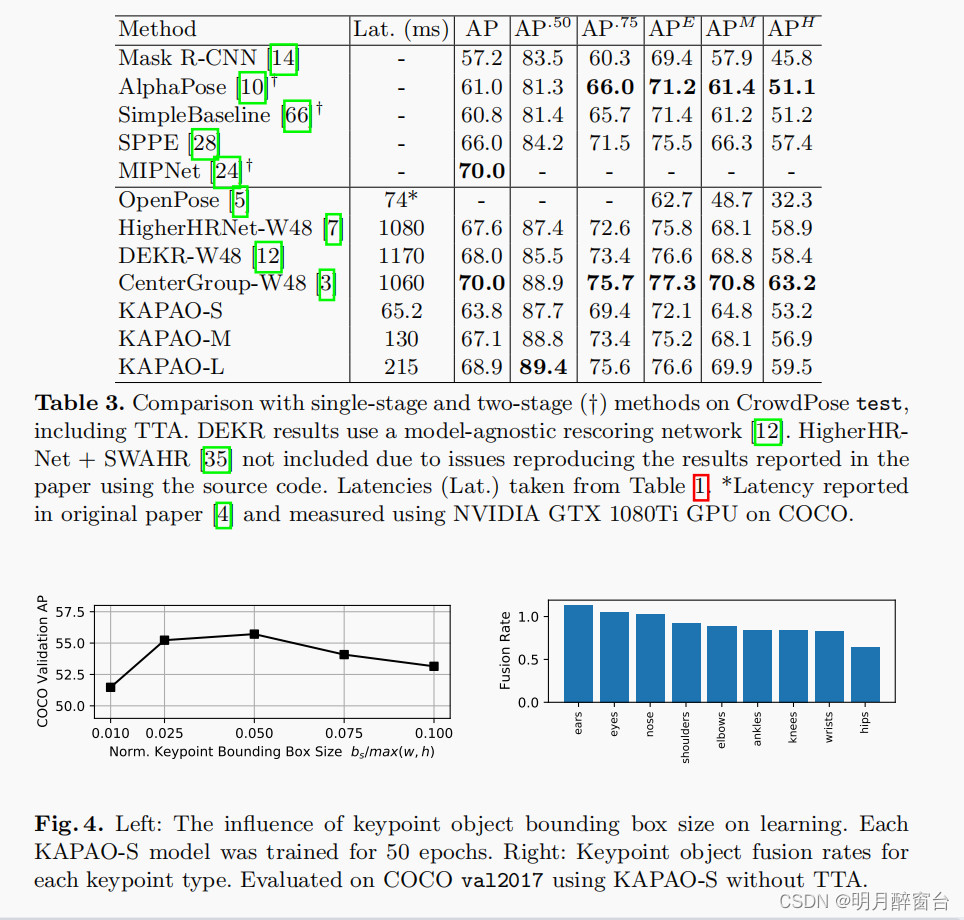
5.2 消融研究(Ablation Studies)


6. 结论
- 本文提出了一种基于关键点和对象建模的无热图关键点估计方法
KAPAO。KAPAO通过检测人体姿态对象,有效地应用于单阶段多人人体姿态估计问题。此外,融合联合检测到的关键点对象可以以最小的计算开销提高预测的人体姿态的精度。当不使用测试时间增强时,KAPAO明显比以前的单阶段方法更快、更准确,这将受到热图后处理和自下而上的关键点分组的极大阻碍。此外,KAPAO在严重遮挡下表现良好,这可以由CrowdPose的竞争结果证明。
conda info --envs