作者 | 尹炜 编辑 | 极市平台
点击下方卡片,关注“自动驾驶之心”公众号
ADAS巨卷干货,即可获取
点击进入→自动驾驶之心【深度估计】技术交流群
本文只做学术分享,如有侵权,联系删文
导读
本文提出了一个统一相机空间(canonical camera space)变换模块,明确解决了尺度模糊性问题,并且可以轻松地嵌入到现有的单目模型中。配备了论文的模块,单目模型可以在800万张图像和数千个相机模型上稳定地训练,从而实现了对室外图像的零样本泛化,其中包含未见过的相机设置。该论文所提方法也是第二届单目深度估计挑战中的冠军方案,在比赛的各个场景上都排第一。

Arxiv: https://arxiv.org/abs/2307.10984
Github: https://github.com/YvanYin/Metric3D
大家好,在这里给大家分享一下我们最近被 ICCV2023 接受的工作《Metric3D: Towards Zero-shot Metric 3D Prediction from A Single Image》。如何从单张图像恢复出绝对尺度的深度,并且重建出带有绝对尺度的3D场景是一个长期待解决的问题。当前最先进的单目深度估计具体分为两类:
第一类方法的目标是恢复准确的绝对深度,但是这一类的方法泛化性比较差,只能处理单个相机模型,并且由于不同相机存在尺度模糊性,导致无法执行混合数据训练来提升域泛化性。第二类方法针对性解决深度模型的零样本泛化问题,如LeReS/MiDaS/DPT/HDN等文章的方法,经过大规模混合数据集训练,并约束模型只学习相对深度。因此,该类方法都没法恢复绝对尺度。
在这项工作中,论文表明零样本单目度量深度估计的关键在于大规模数据训练以及解决来自各种相机模型的尺度模糊性。论文提出了一个统一相机空间(canonical camera space)变换模块, 明确解决了尺度模糊性问题,并且可以轻松地嵌入到现有的单目模型中。配备了论文的模块,单目模型可以在800万张图像和数千个相机模型上稳定地训练,从而实现了对室外图像的零样本泛化,其中包含未见过的相机设置。
下图(论文首页图)通过两个下游的应用,即SLAM和物体测量,来展示了针对零样本的泛化性以及尺度恢复的准确性。可以看出测量的结构尺寸和GT非常接近。值得注意的是,mono-slam系统通过引入预测的深度,能够消除scale drift的问题,并且slam系统能够实现metric mapping.

主要贡献:
提出了一种标准空间相机变换(canonical camera space transformation)和对应的逆变换(de-canonical camera space transformation)方法来解决来自不同相机设置的深度尺度模糊性问题。这使得论文方法可以从大规模数据集中学习强大的零样本(zero-shot)单目度量深度模型;
在模型训练过程中,论文还提出了一种随机提议正则化损失函数,有效提高了深度准确性;
论文方法在第二届单目深度估计挑战中获得了冠军,在比赛的各个场景上都排第一。
论文的模型在7个零样本基准测试上达到了最先进的性能。它能够在户外进行高质量的3D度量结构恢复,并且在几个下游任务中受益,如单目SLAM、3D场景重构和测量学。
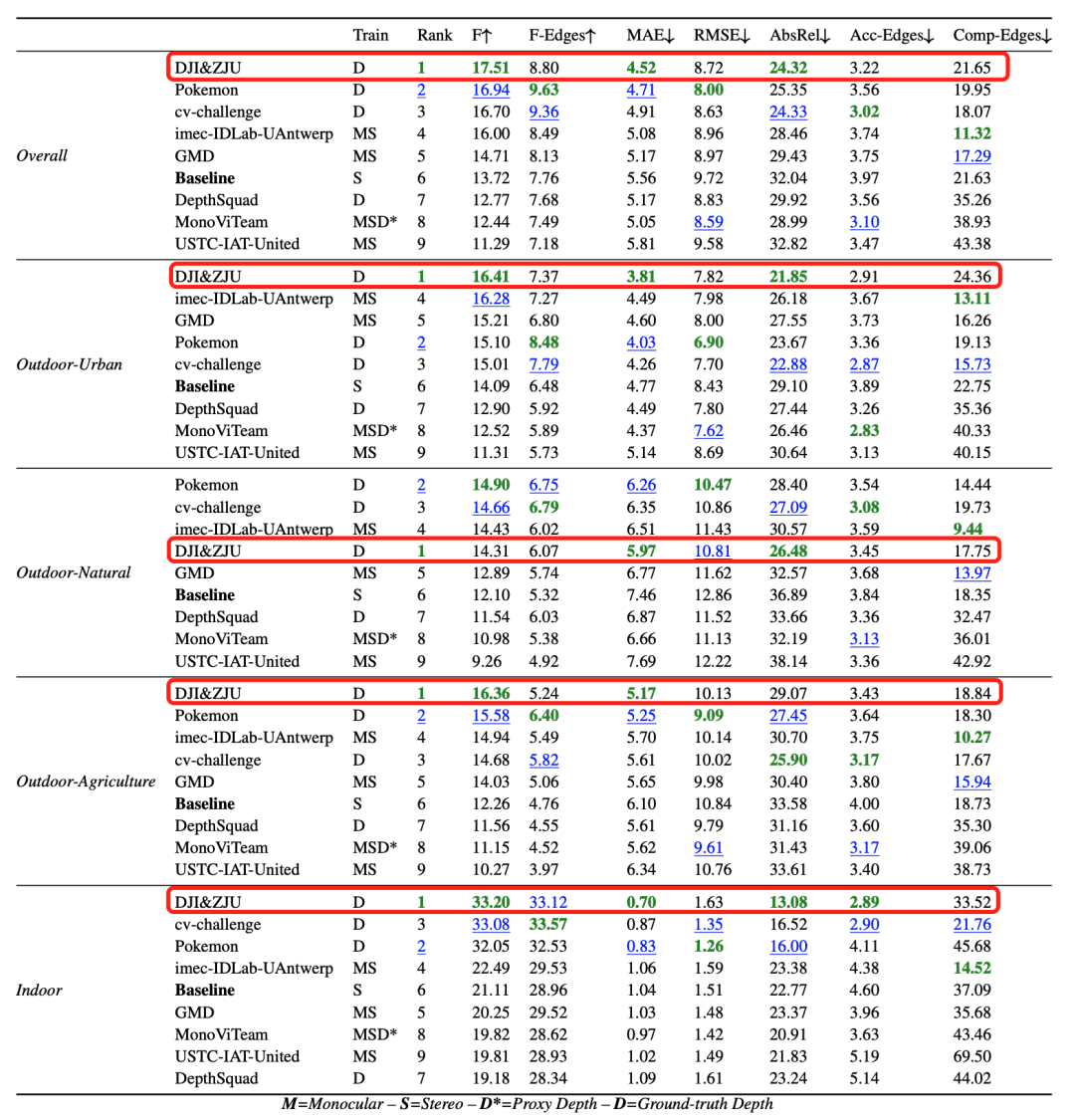
CVPR2023挑战赛结果:
方法:
1.什么是尺度模糊性?
论文针对混合数据中的尺度模糊性做了详细的讲解。如下图所示:

上图通过一个简单的例子来说明什么是尺度的模糊性。不同相机在不同距离下拍摄的照片示例。仅从图像内容来看,人们可能会认为最后两张照片是由同一个相机在相似的位置拍摄的。但实际上,由于拍摄图片采用了不同焦距的相机,这些照片是在不同的位置拍摄的。因此,相机的内部参数的变化导致了尺度的不确定性。对于从单张图像估计度量是至关重要的,否则问题就是不适定的。
2.什么影响深度的预测?
针对相机的传感器尺寸、像素的大小、还有相机的焦距,论文有如下观察。
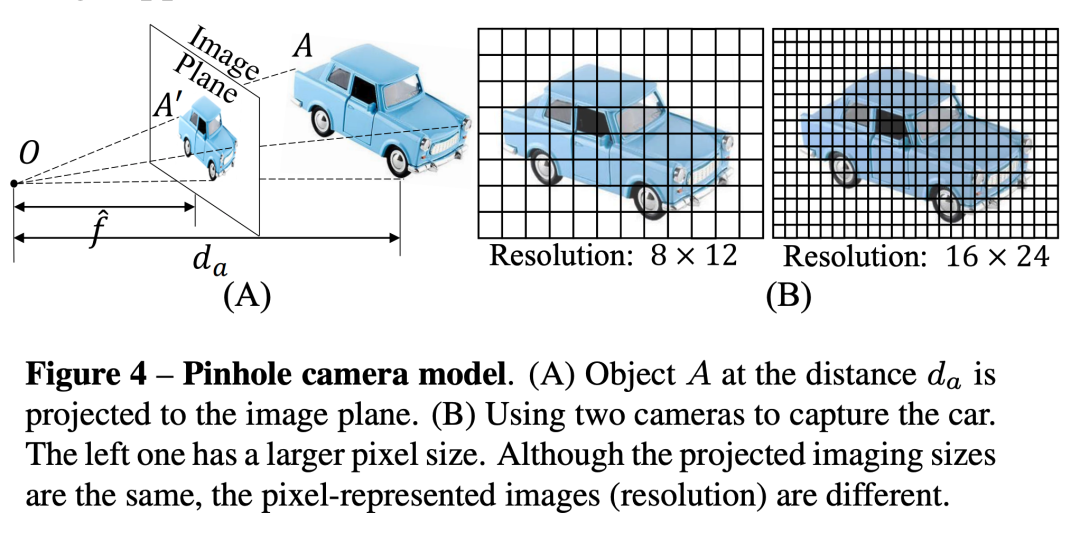
2.1 传感器尺寸和像素大小不会影响度量深度估计
如下图所示,当用不同像素大小的相机拍摄同一个物体时候,虽然像元大小不同,物体在图像的分辨率不同,但是距离是一致的。因此,不同的摄像机传感器不会影响度量深度的估计。此外,传感器的尺寸只是影响了图像拍摄的视野,因此也不会影响深度的估计。
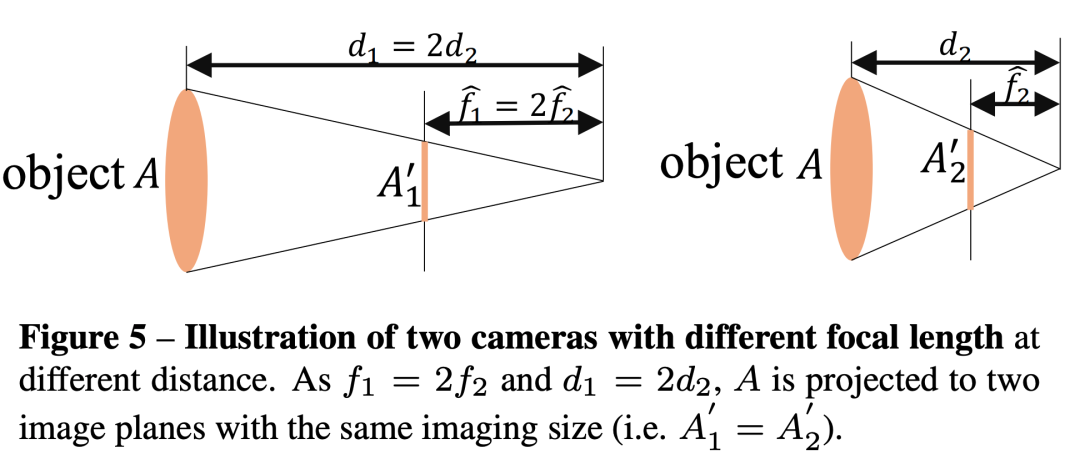
2.2 焦距对于深度估计的准确性非常重要
如下图所示,由于焦距不同,不同距离的物体在相机上的成像大小相同,在网络训练的时候,相似的图像,但是标签却不一致,就导致了一对多的标签映射,因此会导致网络混淆,影响训练。
3.方法的pipeline
方法的pipeline如下图所示。
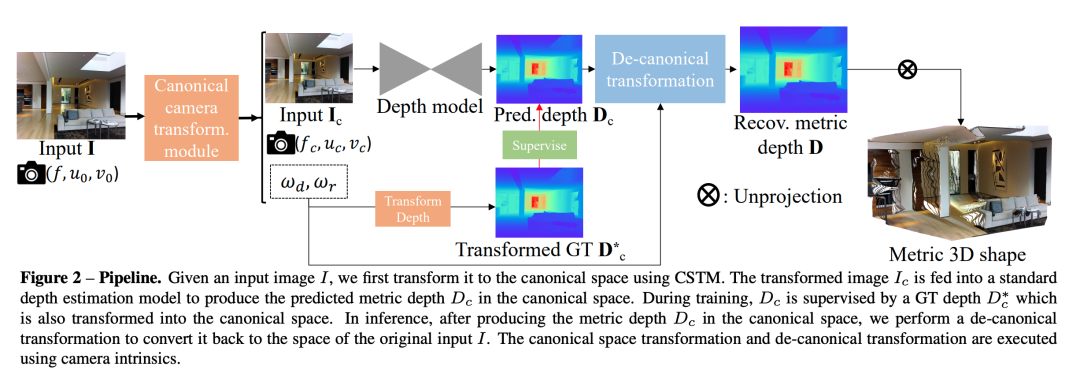
本文提出了2种训练方法。两种方法都可以很容易的嵌入到当前任意的单目深度估计的框架中。整个方法的核心思想就是建立一个标准相机空间, 然后将所有的训练数据都映射到这个空间,那么,所有的训练数据都可以被看做是同一个相机拍摄的。论文提出了2种方法进行这种变换,一种是通过变换训练图像,另一种是变换变换GT label。详细如下:
方法1:将标签进行转换
深度的模糊性是针对深度的。因此,第一种方法直接通过转换ground truth深度标签来解决这个问题。在训练阶段,通过乘以一个缩放因子来转换深度标签。在推理阶段,预测的深度处于规范化空间,需要进行反规范化转换以恢复度量信息。
方法2:将输入图像转换
第二种方法是将输入图像转换为模拟规范相机成像效果。具体来说,在训练阶段训练图像根据焦距按比例缩放resize,相机光心也进行了调整,然后进行随机裁剪图像用于训练。在推理阶段,反规范化转换将预测深度调整回原始大小而不进行缩放。
4.监督
论文采用了各种约束。包括LeReS论文提出的pair-wise normal regression loss,VirtualNormal论文提出的虚拟法矢的loss,还有Scale-invariant Log loss。除此之外,该论文还提出了一种新的loss,叫随机提议标准化损失(RPNL)。尺度平移不变损失被广泛应用于仿射不变深度估计,但它会压缩细粒度深度差异,特别是在近距离区域。因此,论文从真值深度和预测深度中随机裁剪若干小块,然后采用中位绝对偏差标准化对它们进行处理。这样,可以增强局部对比度。整体loss如下。
实验
1.零样本泛化测试
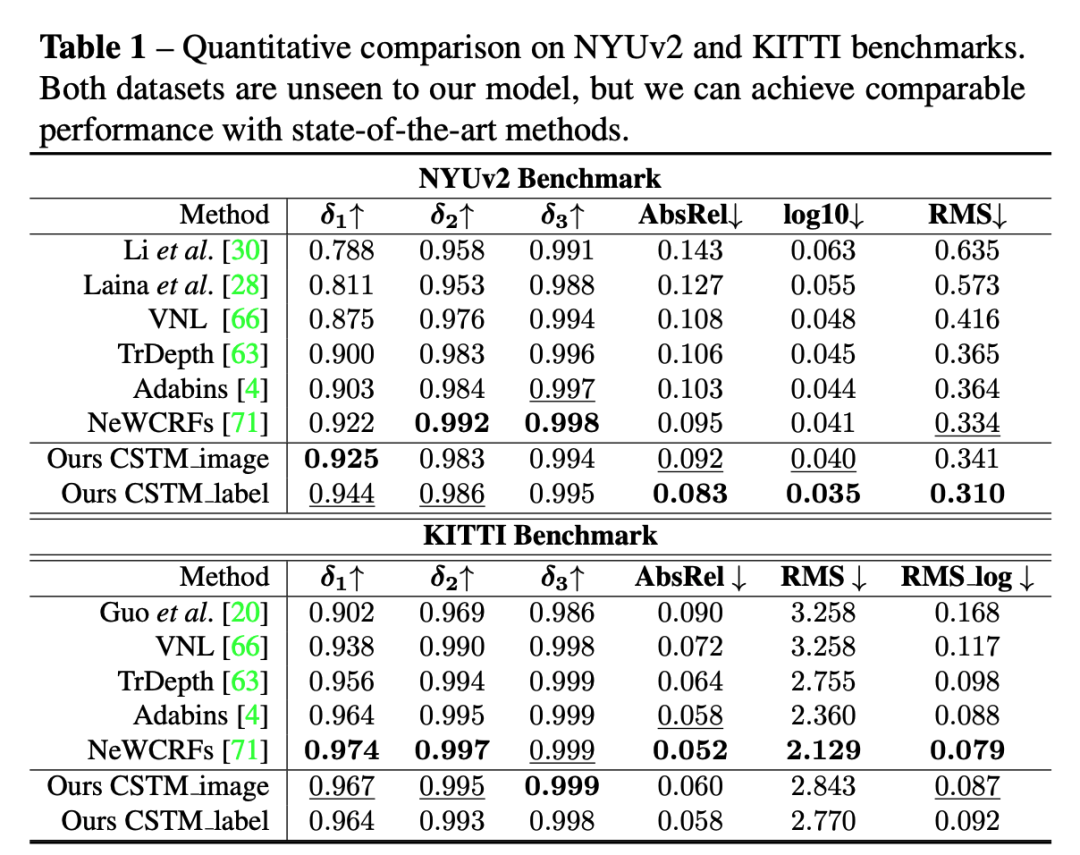
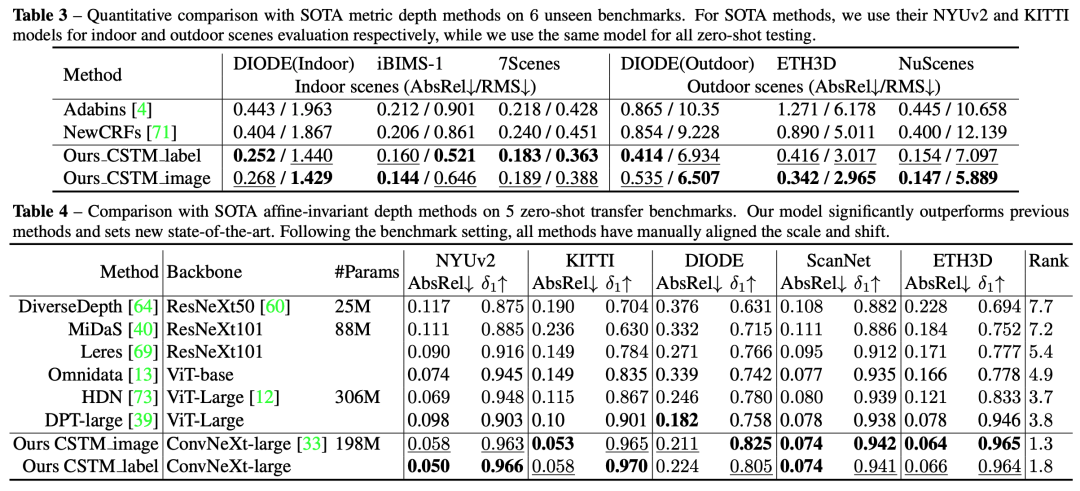
以下的几个表格都是做的零样本泛化实验。其中表格1中,在NYU和KITTI上和当前在他们上fitting的SOTA方法做了对比,发现在不引入该数据做训练,模型就能够恢复出精确的尺度。表格3,论文做了更多的这种零样本泛化的对比,比较了6个数据集。
另外,论文与SOTA仿射不变深度估计方法在5个zero-shot基准上的比较。论文的模型明显优于以前的方法
2.下游应用实验
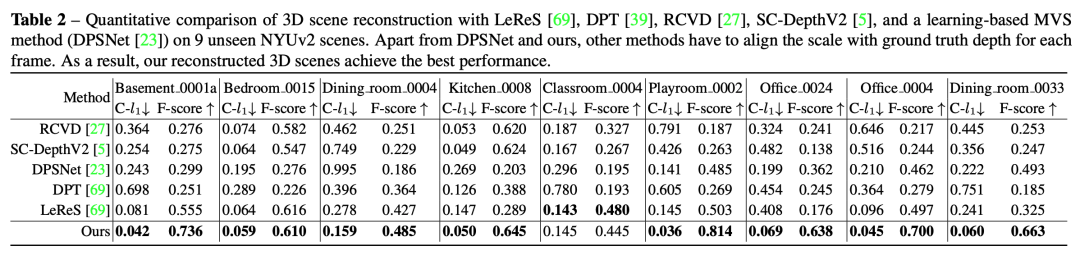
三维重建实验: 论文展示出,直接将预测的连续帧深度重建成点云,并与各类的方法做了对比,包括MVS的方法,放射不变形深度估计的方法,无监督深度估计的方法,videodepth 深度估计的方法等做了对比,发现整体重建精度上会更好。

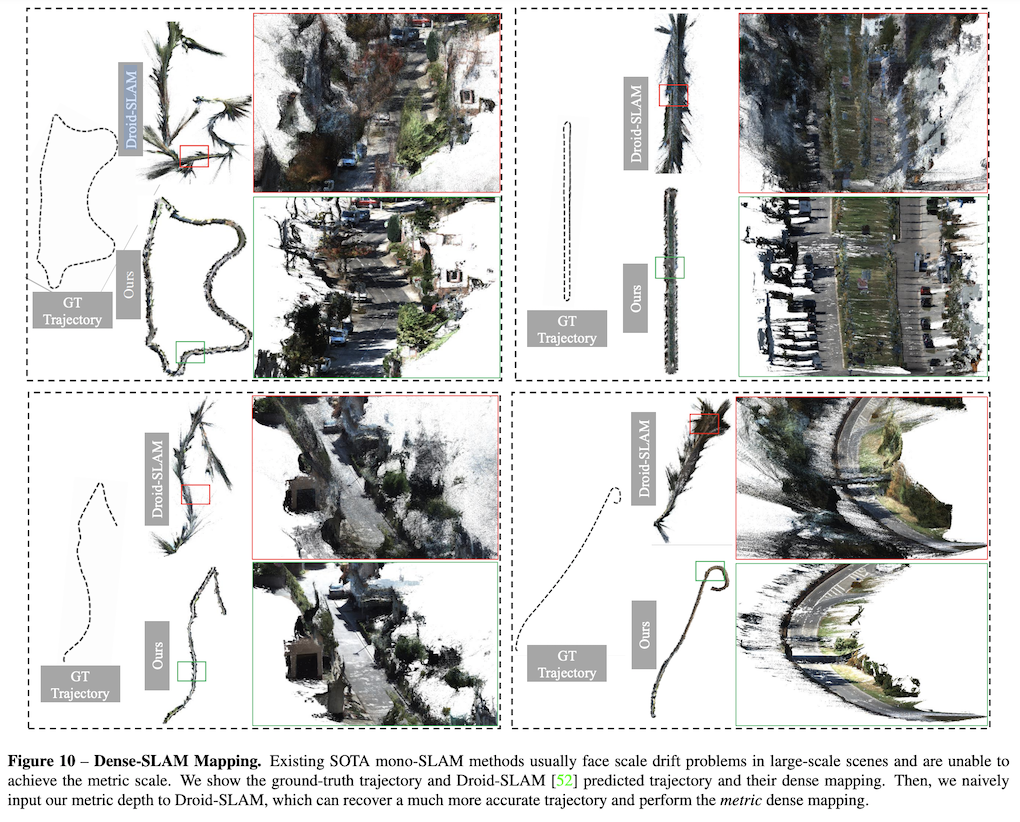
SLAM实验:在如下的表格中,论文的度量深度估计方法可以作为单目SLAM系统的强大深度先验。在KITTI数据集上,将论文的度量深度直接输入到最先进的SLAM系统Droid-SLAM中,结果显示论文的深度使得SLAM系统的性能显著提升。
在ETH3D SLAM数据集上,论文的深度同样带来了更好的SLAM性能,并且能够极大的缓解尺度漂移的问题。
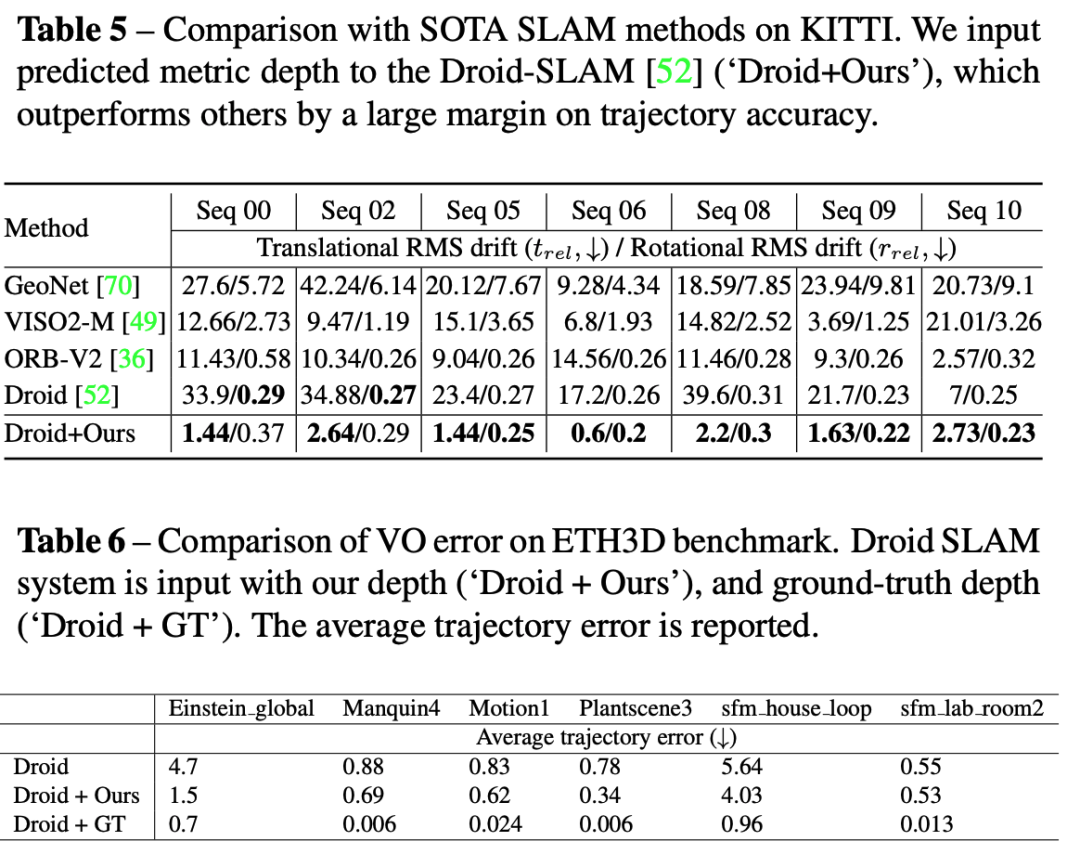
从下图可以看出,droid-slam系统在输入预测的深度后,轨迹和GT更加接近,并且没有尺度漂移的问题,见下面第一个例子。
3.In-the-wild 测量实验
论文从Flickr下载了一些图片,通过从metadata中读取相机的像元大小以及焦距(以mm为单位),粗略估算出相机的焦距(以像素为单位),从而预测出metric depth,然后重建出点云。从点云中可以测量出一些结构的大小,发现和GT相差并不那么大。
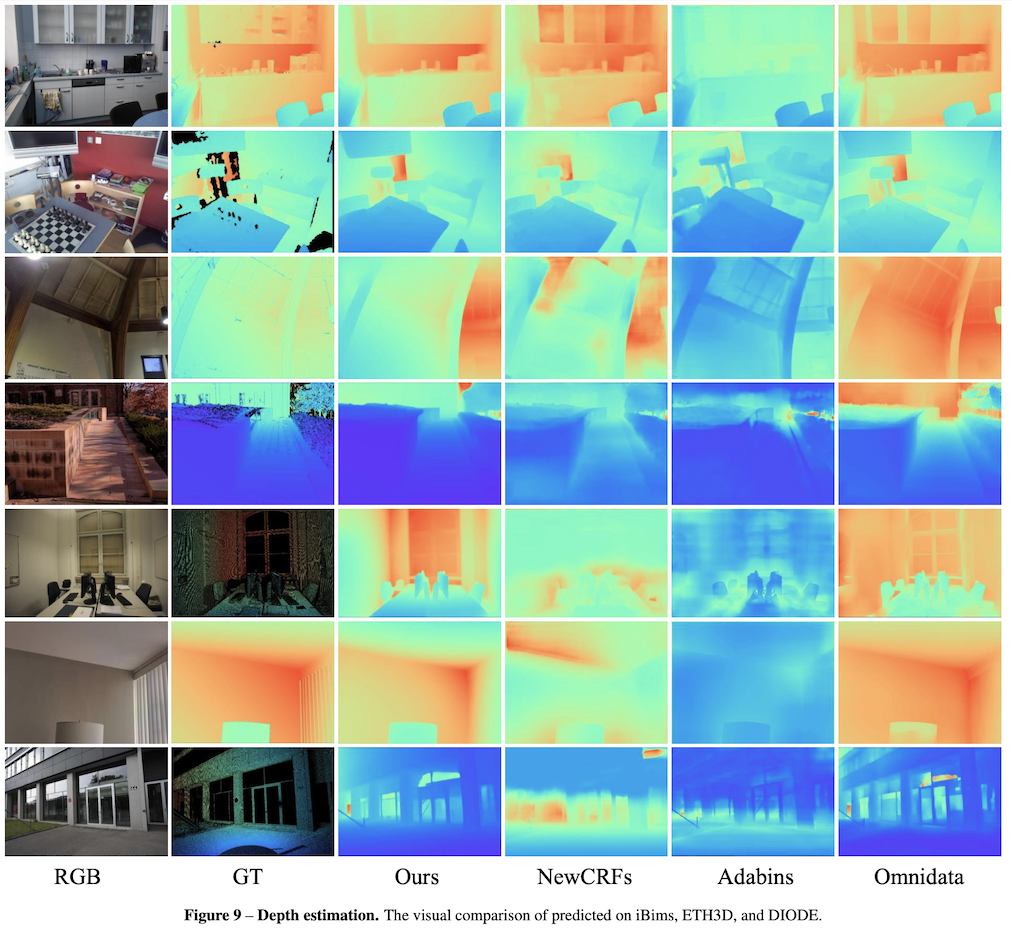
4.更多的深度图展示:
总结
本文解决了从单目图像重构三维度量场景的问题。为了解决由不同焦距引起的图像外观深度不确定性,论文提出了一种规范化相机空间转换方法。使用论文的方法,可以轻松地合并由10,000个相机拍摄的数百万数据,以训练一个度量深度模型。为了提高鲁棒性,论文收集了超过800万数据进行训练。几个零样本评估展示了论文工作的有效性和鲁棒性。论文进一步展示了在随机收集的互联网图像上进行计量学测量以及在大规模场景上进行密集建图的能力。
① 全网独家视频课程
BEV感知、毫米波雷达视觉融合、多传感器标定、多传感器融合、多模态3D目标检测、点云3D目标检测、目标跟踪、Occupancy、cuda与TensorRT模型部署、协同感知、语义分割、自动驾驶仿真、传感器部署、决策规划、轨迹预测等多个方向学习视频(扫码即可学习)
 视频官网:www.zdjszx.com
视频官网:www.zdjszx.com
② 国内首个自动驾驶学习社区
近2000人的交流社区,涉及30+自动驾驶技术栈学习路线,想要了解更多自动驾驶感知(2D检测、分割、2D/3D车道线、BEV感知、3D目标检测、Occupancy、多传感器融合、多传感器标定、目标跟踪、光流估计)、自动驾驶定位建图(SLAM、高精地图、局部在线地图)、自动驾驶规划控制/轨迹预测等领域技术方案、AI模型部署落地实战、行业动态、岗位发布,欢迎扫描下方二维码,加入自动驾驶之心知识星球,这是一个真正有干货的地方,与领域大佬交流入门、学习、工作、跳槽上的各类难题,日常分享论文+代码+视频,期待交流!

③【自动驾驶之心】技术交流群
自动驾驶之心是首个自动驾驶开发者社区,聚焦目标检测、语义分割、全景分割、实例分割、关键点检测、车道线、目标跟踪、3D目标检测、BEV感知、多模态感知、Occupancy、多传感器融合、transformer、大模型、点云处理、端到端自动驾驶、SLAM、光流估计、深度估计、轨迹预测、高精地图、NeRF、规划控制、模型部署落地、自动驾驶仿真测试、产品经理、硬件配置、AI求职交流等方向。扫码添加汽车人助理微信邀请入群,备注:学校/公司+方向+昵称(快速入群方式)

④【自动驾驶之心】平台矩阵,欢迎联系我们!
