目录
Python正则表达式官方文档链接:
https://docs.python.org/zh-cn/3.9/library/re.html
01-re.match函数的使用实例
re.match() 尝试从字符串的起始位置匹配一个模式,如果不是起始位置匹配成功的话,match() 就返回 none。
语法如下:
re.match(pattern, string, flags=0)
参数意义如下:
pattern—匹配的正则表达式
string—要匹配的字符串。
flags—标志位,用于控制正则表达式的匹配方式,如:是否区分大小写,多行匹配等等。其具体可选值见本文第02点。
示例代码如下:
import re
match1 = re.match('blog', 'blog.csdn.net')
match2 = re.match('net', 'blog.csdn.net')
运行结果如下:

结果分析:
在语句
match1 = re.match('blog', 'blog.csdn.net')
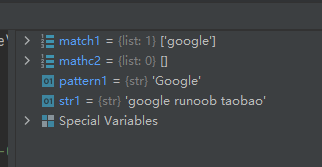
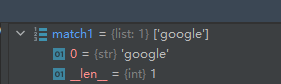
中,看字符串’blog.csdn.net’从开头开始能否匹配模式’blog’。字符串’blog.csdn.net’的前四个字符就匹配到了模式’blog’,所以match1并不为None,而是一个Match对象,其中记录了与匹配相关的信息。关于Match对象的属性和方法见??。
在语句
match2 = re.match('net', 'blog.csdn.net')
中,看字符串’blog.csdn.net’从开头开始能否匹配模式’net’。字符串’blog.csdn.net’的第一个字符为b,显然和模式’net’不匹配,所以mathc2得到的是None对象。
02-参数flags的使用示例
02-01-re.I(使匹配对大小写不敏感-不区分大小写)
示例代码如下:
import re
pattern1 = r'Google'
str1 = 'google runoob taobao'
match1 = re.findall(pattern1, str1, re.I)
mathc2 = re.findall(pattern1, str1)
运行结果如下:
02-02-re.L(做本地化识别(locale-aware)匹配)
查了Python的re模块的官方资料和CSDN上进行搜索,均没有对这个flag值进行说明,全是同一句话,做本地化识别(locale-aware)匹配,可见,这个用的应该不多,所以大家也都没怎么在意吧!
后来我在了解re.U时意识到这个字符串在匹配时是与编码类型有关的,所以所谓本地化识别就是指用本地的编码类型进行匹配。
02-03-re.M和re.S(re.M表示多行匹配-即把换行符当成换行符的效果来匹配,re.S表示单行匹配,即把换行符也看成是一个普通字符来匹配)
上面的标题可能大家看来还是不太明白。还是用实际来例子来看吧。
str1 = 'hello1world\nhello2world\nhello3world'
# re.M 多行模式
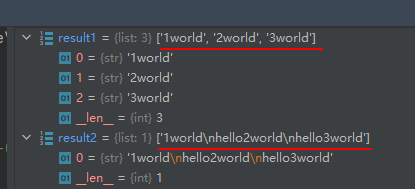
result1 = re.findall(r'\d.*d', str1, re.M)
# re.S 单行模式
result2 = re.findall(r'\d.*d', str1, re.S)
运行结果如下:
结果分析:
正则表达式:'\d.*d’表示第1个为数字,结尾为字母d的字符串。
在多行模式中,由于把字符串按换行符‘\n’分成了三行,所以匹配到了三个符合正则表达式的字符串。
在单行模式中,把整个字符串看成一行(换行符‘\n’不再表示换行的效果),所以匹配到了一个长字符串。有同学要问,不是说‘.’唯一不能匹配的就是换行符‘\n’么,是的,但是在单行模式中,换行符‘\n’只是一个普通字符,不再具有换行的效果,所以结果如上面的截图所示。 我们也可以换个角度来理解这个问题,即可认为单行模式使 . 匹配包括换行在内的所有字符。
02-04-re.U(根据Unicode字符集解析字符)
根据Unicode字符集解析字符,这个标志影响 \w, \W, \b, \B。
为什么影响的是 \w, \W, \b, \B?
关于Unicode字符集的介绍及Unicode字符集与UFT-8的区别可以参见文章 https://www.jianshu.com/p/4f555eb46d2e
为什么说按Unicode字符集解析会影响 \w, \W, \b, \B呢?
因为\w表示字母数字及下划线,那么不同的字符集对于字母数字及下划线的表示是有差别的,所以\w、\W会受到影响。
又因为\b表示匹配一个单词的边界,而单词是由字母组成的,所以\b、\B也会受到影响。
02-05-re.X(增加可读性,忽略空格和#后面的注释)
我们可利用re.X增加正则表达式的可读性,使用它可以忽略空格和#后面的注释。
怎么增加的呢?因为它会把#后面的注释忽略掉,所以就可以在正则表达式中用#写上说明文字,这样就增加了正则表达式的可读性。
示例代码如下:
import re
rc = re.compile(r"""
# start a rule
/d+
# number
|
[a-zA-Z]+
# word
""", re.X)
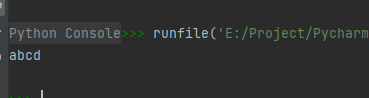
res = rc.match('abcd')
print(res.group())
运行结果如下
03-Match对象的属性(Attribute)
我们根据下面这个例子来看Match对象的属性有哪些。
import re
match1 = re.match('blog', 'blog.csdn.net')
我们可以通过观察match1对象来学习Match对象的属性。
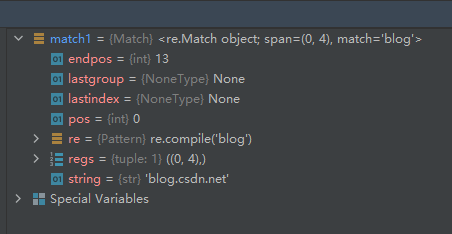
属性endpos—刚好是待匹配字符串的长度,这实际上告诉了re模块在匹配时不能超过这个索引值,即字符的索引应小于这个值。
属性lastgroup—从上面的运行看不出这个值的含义,参考第三方资料,意思为最后匹配的捕获组的名称,如果组没有名称,或者根本没有匹配的组返回None。
属性lastindex—从上面的运行看不出这个值的含义,参考第三方资料,意思为返回最后匹配的组的整数索引,如果根本没有匹配的组,返回None。
属性pos—从待匹配字符串的哪个索引位置开始去匹配。
属性re—这是一个Pattern对象,详见 ??
属性regs—这里面似乎记录了待匹配字符串里是从哪个位置到哪个位置匹配成功的,并且是左闭右开区间
属性string—这里面是待匹配的字符串。
04-Match对象的方法(Method)
04-01-Match.group([group1, …])
功能:返回匹配到的一个或多个子组。
示例代码如下:
import re
match1 = re.match(r"(\w+) (\w+)", "Isaac Newton, physicist")
str1 = match1.group(0)
str2 = match1.group(1)
str3 = match1.group(2)
str4 = match1.group(1, 2)
运行结果如下:
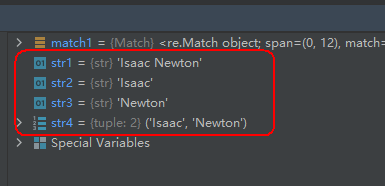
代码分析:
首先看正则表达式语句
r"(\w+) (\w+)"
r是何义?见博文 https://blog.csdn.net/wenhao_ir/article/details/125396412的“09-字符串原始化”。
print(r'i love you \n\r')
print(R'i hate you \n\r')
运行结果如下:
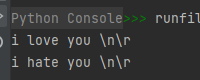
所以我们可以看出,正则表达式中的“\w”等元字符我们希望解释器按本义解释,所以通常我们都要加上r前缀。
正则表达式中的每一个小括号代表一个分组。从正则表达式语句r"(\w+) (\w+)"中我们可以看出我们进行了两个分组。
04-02-Match.expand(template)
将template字符串中指定的利用反斜杠标示的数字或组名替换为相应组中的值。
示例代码及运行结果如下:
m=re.match(r'(?P<first_name>\w+) (?P<last_name>\w+)','Eric Brown')
print(m.group(0))
# Eric Brown
print(m.group(1))
# Eric
print(m.group(2))
# Brown
print(m.expand(r'His name is \1 \2'))
# His name is Eric Brown
print(m.expand(r'His name is \g<1> \g<2>'))
# His name is Eric Brown
print(m.expand(r'His name is \g<first_name> \g<last_name>'))
# His name is Eric Brown
04-03-Match.groups(default=None)
功能:返回包含匹配的所有子组的元组。说白了就是返回所有分组的结果,示例代码如下:
import re
match1 = re.match(r"(\w+) (\w+)", "Isaac Newton, physicist")
str0 = match1.groups()
str1 = match1.groups(0)
str2 = match1.groups(1)
str3 = match1.groups(2)
运行结果如下:
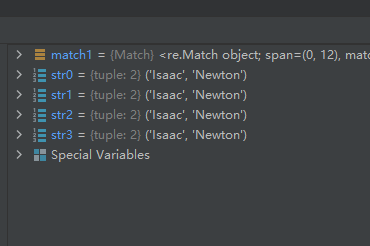
从运行结果可以看出,不管参数填什么,都把两个分组匹配结果返回了,所以可以说它就是把所有的分组匹配结果返回了。要注意区分它与方法group()的区别,方法group()返回的是指定的一个多个子组匹配结果。
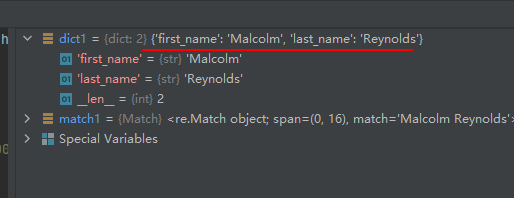
04-04-Match.groupdict(default=None)
返回匹配到的所有已命名子组的字典(dict),由子组名作为键。
示例代码如下:
import re
match1 = re.match(r"(?P<first_name>\w+) (?P<last_name>\w+)", "Malcolm Reynolds")
dict1 = match1.groupdict()
运行结果如下:
05-怎么样给子组命名?
示例代码如下:
import re
match1 = re.match(r"(?P<first_name>\w+) (?P<last_name>\w+)", "Malcolm Reynolds")
dict1 = match1.groupdict()
从上面的示例代码可以看出,给子组命的格式为 ?P<子组名>
06-为什么正则表达式要加上前缀r?
因为在字符串中 \ 表示转义,比如\t 表示制表符,而在正则表达式中 \ 需要取其本义,所以要加前缀r。举个例子来说,如果不加前缀r,则r’\w’需要写成’\w’ ,这样不仅麻烦,还容易写错。
07-正则表达式的元字符
元字符是正则表达式的灵魂,所以要想娴熟书写正则表达式,就需要把元字符搞清楚。
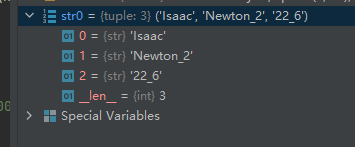
07-01- \w:匹配字母、数字、下划线。
示例代码如下:
import re
match1 = re.match(r"(\w+) (\w+) (\w+)", "Isaac Newton_2 22_6")
str0 = match1.groups()
运行结果如下:
07-02- +:匹配与其紧邻的子表达式一次或多次。
示例代码:
例如,‘zo+’ 能匹配 “zo” 以及 “zoo”,但不能匹配 “z”。