1.YOLOV1
第一个版本是所有版本的基础,为监督学习,主要理解Ground truth、Grid cell、Bounding box区别,提出的IOU、NMS、损失函数、训练测试过程
IOU:交并比,计算两个预测框之间交集部分比例
NMS:在IOU基础上,有效删除冗余检测的结果,依次大小顺序计算与最大bbox之间iou大小,超过阈值删除,代表检测物体重复
损失函数:将目标检测问题以归一化处理,包括坐标误差、宽高误差、负责监测物体bbox置性度误差、不负责检测物体bbox置性度误差、grid cell分类误差
训练:
- 人工标注图片导入模型中
- 标注图片框中心所在grid cell为检测窗口
- 模型计算生成(x,y,w,h,c)及对应20个类别坐标,总7*7*(2*5+20)=7*7*30
- 计算对应loss
- 优化(正常网络模型训练)……
测试:
- 图片输入模型生成7*7*(2*5+20),包括bbox置信度、分类概率(条件概率)
- 计算confidence score=置信度c*分类概率
- 计算NMS
- 得出结果
2.YOLOV2
- 第二版本相对于第一版本主要提出了使用锚框anchor,通过聚类分析得出特定形状以及数量(设定每个grid cell生成5个anchor)
- 使用BN(batch normalization):于线性层与非线性层之间进行归一处理并加上相应权重(有点像正态分布),减少数据丢失或过拟合
- 模型输出:tx,ty,tw,th计算得出预测框实际坐标及宽度,即bx,by,bw,bh
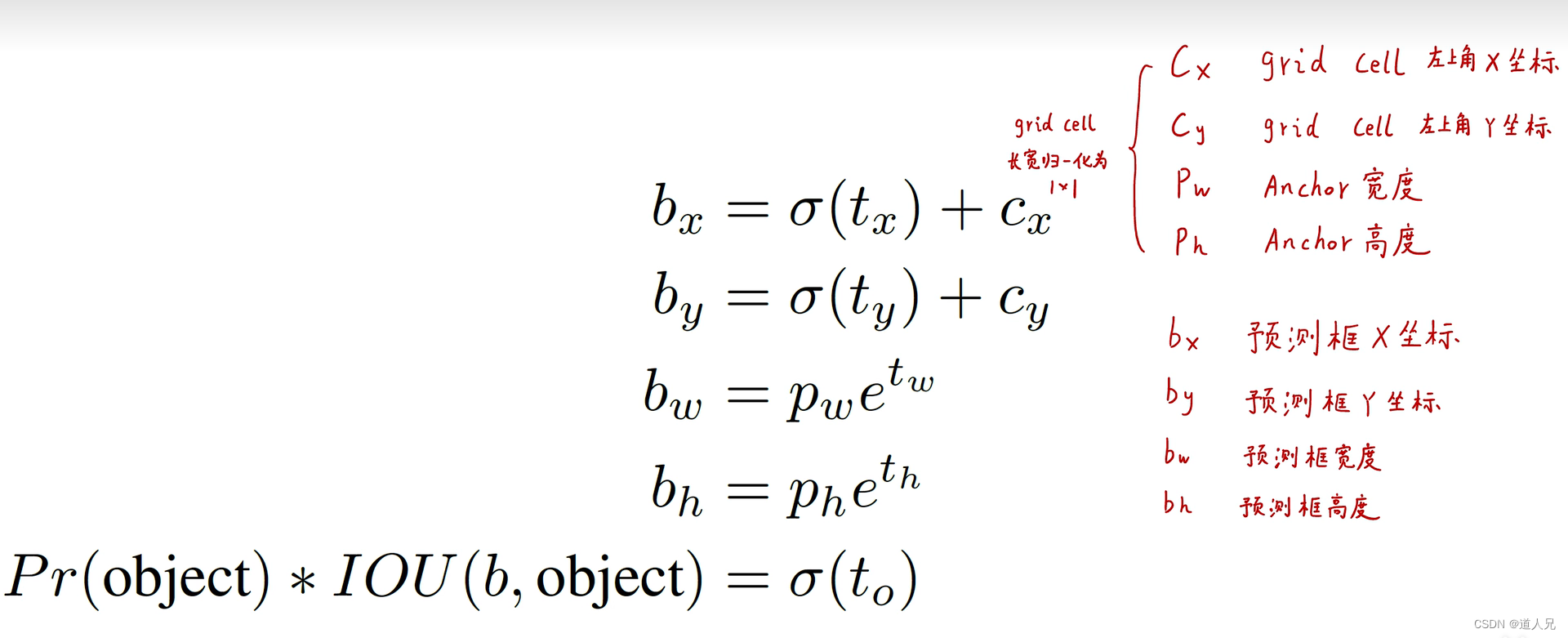
图来自b站同济子豪兄 【精读AI论文】YOLO V2目标检测算法_哔哩哔哩_bilibili
3.YOLOV3
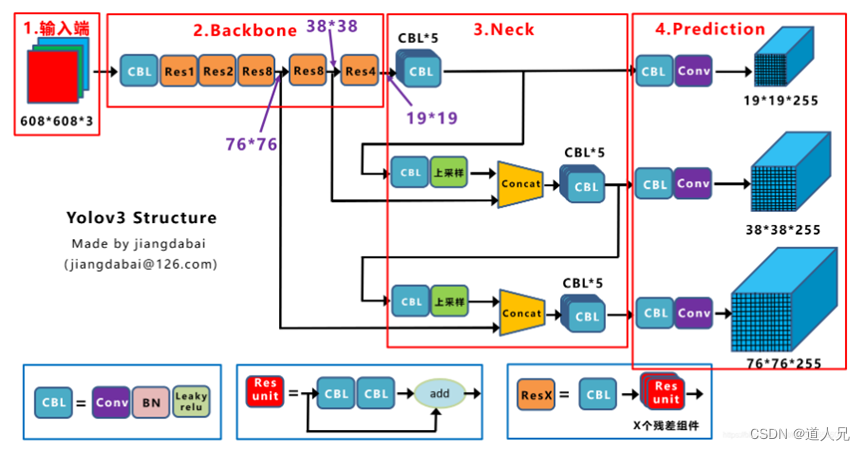
- 采用多尺度融合,输入416*416*3,输出13*13*255, 26*26*255, 52*52*255其中255包括3个anchor坐标信息置信度及80种分类概率, 即3*5*80=255
- 借鉴resnet网络中残差结构,构建更深的网络
- 采用下采样后上采样传递语义信息,增强目标信息
- 激活函数使用leaky-relu
4.YOLOV4&V5
V4是在v3的多尺度融合上更进一步的优化及堆料,而V5可以说是对V4的网络优化、轻量化,两者合并分析:
共同点:
- 使用Mosic数据增强结构:4张图片随机缩放、随机裁剪、随机排布,更有利于小目标检测
- 增加了spp多层池化增强主干特征、cspx下采样(V5包括csp1_x、csp2_x)
- 使用FPN+PAN上下采样结构传递语义信息
- 训练时采用CIOU_loss计算方式,考虑边框宽高比(ciou)、边框中心距离(diou)、边界重合(giou)、重叠面积(iou)
- Nms计算采用DIOU_NMS,测试时没有gt,所以用不了Ciou
- 激活函数采用mish
不同点:
- V3v4单独使用程度进行图片转换,V5进行自适应图片缩放计算
- V5采用自适应锚框计算,每次训练自适应计算不同训练集中最佳锚框值
- 模型不同深度与宽度,V5分为yolov5s、yolov5m、yolov5l、yolov5x
yolov4网路框图:
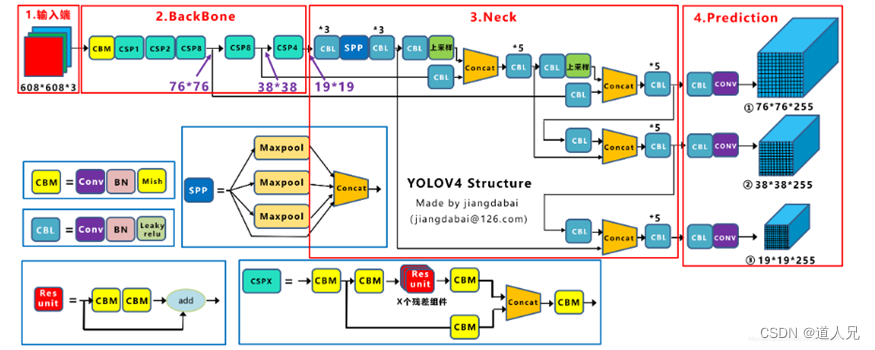
yolov5网络框图: