Buffer Pool在数据库里的地位
1、回顾一下Buffer Pool是个什么东西?
数据库中的Buffer Pool是个什么东西?其实他是一个非常关键的组件,数据库中的数据实际上最终都是要存放在磁盘文件上的,如下图所示。
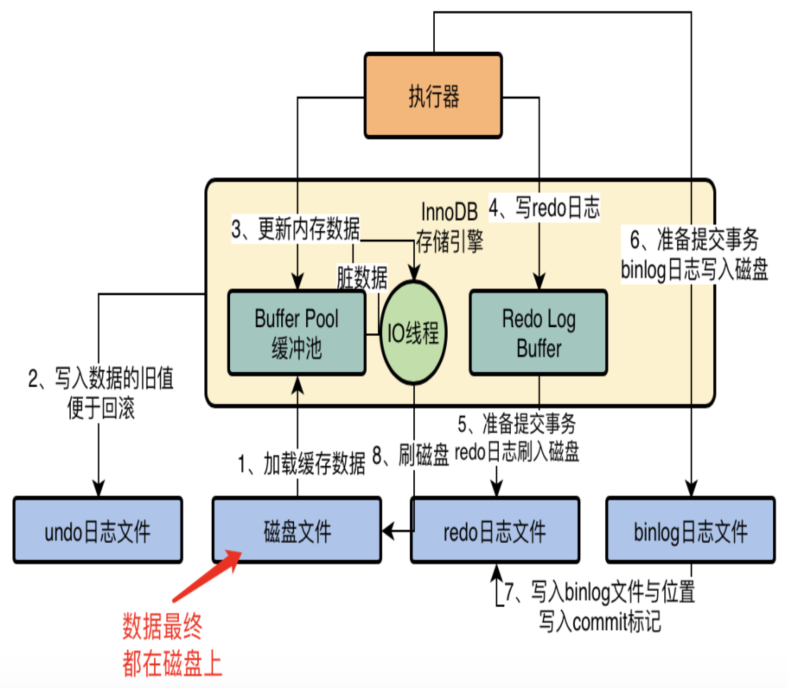
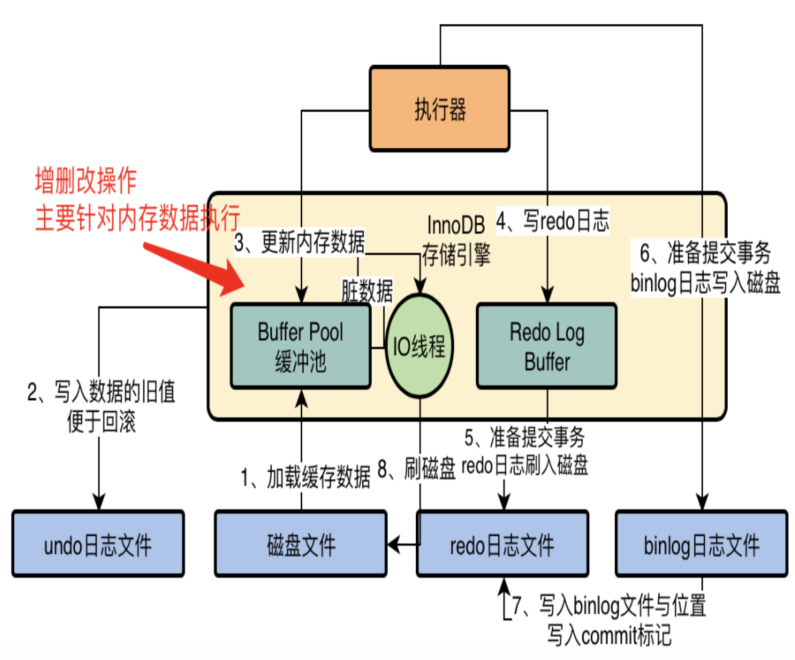
但是我们在对数据库执行增删改操作的时候,不可能直接更新磁盘上的数据的,因为如果你对磁盘进行随机读写操作,那速度是相当的慢,随便一个大磁盘文件的随机读写操作,可能都要几百毫秒。如果要是那么搞的话,可能你的数据库每秒也就只能处理几百个请求了! 在对数据库执行增删改操作的时候,实际上主要都是针对内存里的Buffer Pool中的数据进行的,也就是实际上主要是对数据库的内存里的数据结构进行了增删改,如下图所示。
其实每个人都担心一个事,就是你在数据库的内存里执行了一堆增删改的操作,内存数据是更新了,但是这个时候如果数据库突然崩溃了,那么内存里更新好的数据不是都没了吗? MySQL就怕这个问题,所以引入了一个redo log机制,你在对内存里的数据进行增删改的时候,他同时会把增删改对应的日志写入redo log中,如下图。
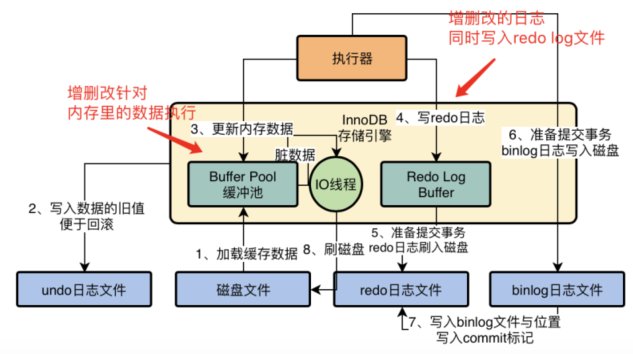
万一你的数据库突然崩溃了,没关系,只要从redo log日志文件里读取出来你之前做过哪些增删改操作,瞬间就可以重新把这些增删改操作在你的内存里执行一遍,这就可以恢复出来你之前做过哪些增删改操作了。 当然对于数据更新的过程,他是有一套严密的步骤的,还涉及到undo log、binlog、提交事务、buffer pool脏数据刷回磁盘,等等。
2、Buffer Pool的一句话总结
Buffer Pool是数据库中我们第一个必须要搞清楚的核心组件,因为增删改操作首先就是针对这个内存中的Buffer Pool里的数据执行的,同时配合了后续的redo log、刷磁盘等机制和操作。
所以Buffer Pool就是数据库的一个内存组件,里面缓存了磁盘上的真实数据,然后我们的系统对数据库执行的增删改操作,其实主要就是对这个内存数据结构中的缓存数据执行的。
Buffer Pool这个内存数据结构到底长个什么样子?
1、如何配置你的Buffer Pool的大小?
我们应该如何配置你的Buffer Pool到底有多大呢? 因为Buffer Pool本质其实就是数据库的一个内存组件,你可以理解为他就是一片内存数据结构,所以这个内存数据结构肯定是有一定的大小的,不可能是无限大的。 这个Buffer Pool默认情况下是128MB,还是有一点偏小了,我们实际生产环境下完全可以对Buffer Pool进行调整。 比如我们的数据库如果是16核32G的机器,那么你就可以给Buffer Pool分配个2GB的内存,使用下面的配置就可以了。 [server] innodb_buffer_pool_size = 2147483648 如果你不知道数据库的配置文件在哪里以及如何修改其中的配置,那建议可以先在网上搜索一些MySQL入门的资料去看看,其实这都是最基础和简单的。 我们先来看一下下面的图,里面就画了数据库中的Buffer Pool内存组件
2、数据页:MySQL中抽象出来的数据单位
假设现在我们的数据库中一定有一片内存区域是Buffer Pool了,那么我们的数据是如何放在Buffer Pool中的?
我们都知道数据库的核心数据模型就是 表+字段+行 的概念,所以大家觉得我们的数据是一行一行的放在Buffer Pool里面的吗? 这就明显不是了,实际上MySQL对数据抽象出来了一个数据页的概念,他是把很多行数据放在了一个数据页里,也就是说我们的磁盘文件中就是会有很多的数据页,每一页数据里放了很多行数据,如下图所示。
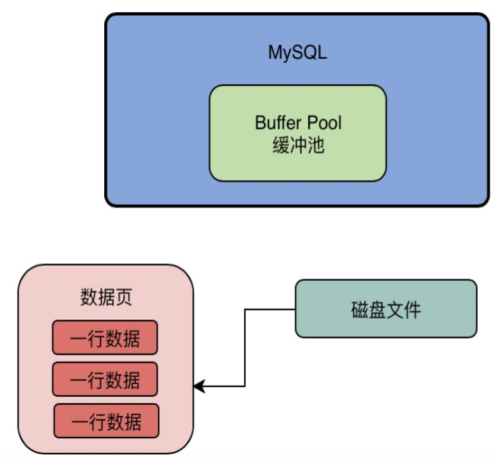
所以实际上假设我们要更新一行数据,此时数据库会找到这行数据所在的数据页,然后从磁盘文件里把这行数据所在的数据页直接给加载到Buffer Pool里去。 也就是说,Buffer Pool中存放的是一个一个的数据页,如下图。
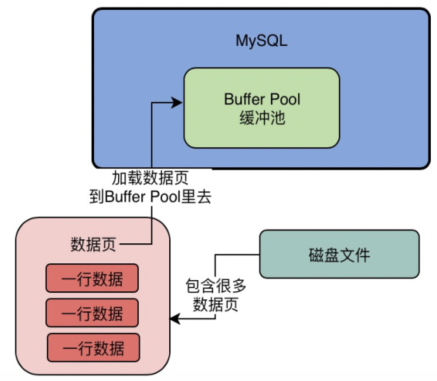
3、磁盘上的数据页和Buffer Pool中的缓存页是如何对应起来的?
实际上默认情况下,磁盘中存放的数据页的大小是16KB,也就是说,一页数据包含了16KB的内容。 而Buffer Pool中存放的一个一个的数据页,我们通常叫做缓存页,因为毕竟Buffer Pool是一个缓冲池,里面的数据都是从磁盘缓存到内存去的。 而Buffer Pool中默认情况下,一个缓存页的大小和磁盘上的一个数据页的大小是一一对应起来的,都是16KB。 我们看下图,我给图中的Buffer Pool标注出来了他的内存大小,假设他是128MB吧,然后数据页的大小是16KB。
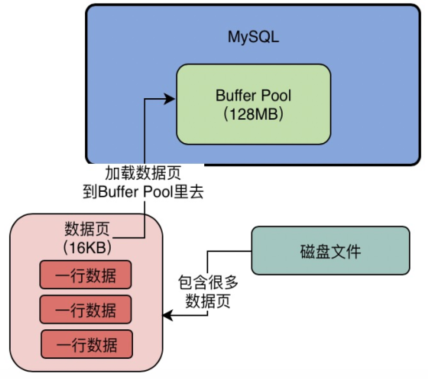
4、缓存页对应的描述信息是什么?
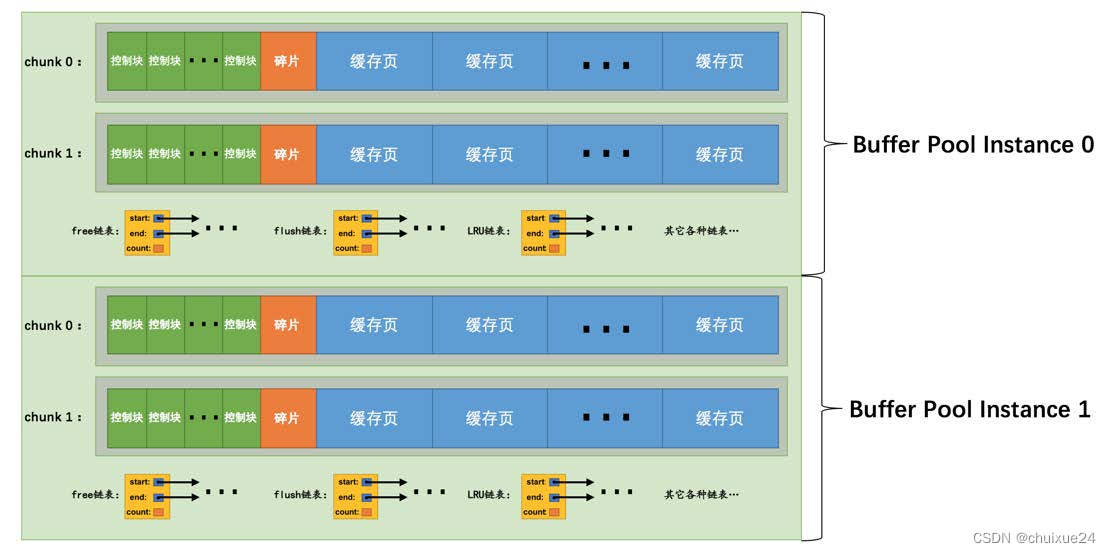
对于每个缓存页,他实际上都会有一个描述信息,这个描述信息大体可以认为是用来描述这个缓存页的。 比如包含如下的一些东西:这个数据页所属的表空间、数据页的编号、这个缓存页在Buffer Pool中的地址以及别的一些杂七杂八的东西。 每个缓存页都会对应一个描述信息,这个描述信息本身也是一块数据,在Buffer Pool中,每个缓存页的描述数据放在最前面,然后各个缓存页放在后面。所以此时我们看下面的图,Buffer Pool实际看起来大概长这个样子 。
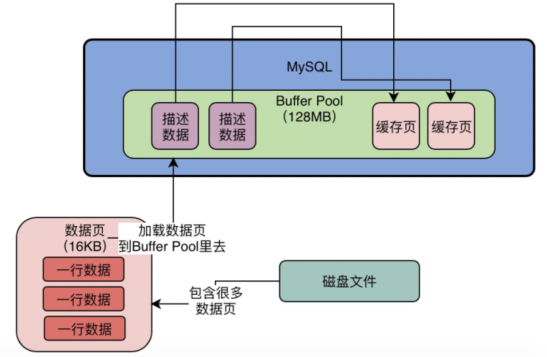
而且这里我们要注意一点,Buffer Pool中的描述数据大概相当于缓存页大小的5%左右,也就是每个描述数据大概是800个字节左右的大小,然后假设你设置的buffer pool大小是128MB,实际上Buffer Pool真正的最终大小会超出一些,可能有个130多MB的样子,因为他里面还要存放每个缓存页的描述数据。
思考
对于Buffer Pool而言,他里面会存放很多的缓存页以及对应的描述数据,那么假设Buffer Pool里的内存都用尽了,已经没有足够的剩余内存来存放缓存页和描述数据了,此时Buffer Pool里就一点内存都没有了吗?还是说Buffer Pool里会残留一些内存碎片呢? 如果你觉得Buffer Pool里会有内存碎片的话,那么你觉得应该怎么做才能尽可能减少Buffer Pool里的内存碎片呢?
在生产环境中,如何基于机器配置来合理设置Buffer Pool?
1、生产环境中应该给buffer pool设置多少内存?
今天这篇文章我们接着上一次讲解的Buffer Pool的一些内存划分的原理,来给大家最后总结一下,在生产环境中到底应该如何设置Buffer Pool的大小呢。 首先考虑第一个问题,我们现在数据库部署在一台机器上,这台机器可能有个8G、16G、32G、64G、128G的内存大小,那么此时buffer pool应该设置多大呢? 有的人可能会想,假设我有32G内存,那么给buffer pool设置个30GB得了,这样的话,MySQL大量的crud操作都是基于内存来执行的,性能那是绝对高! 这么想就大错特错了,虽然你的机器有32GB的内存,但是你的操作系统内核就要用掉起码几个GB的内存!你的机器上可能还有别的东西在运行!你的数据库里除了buffer pool是不是还有别的内存数据结构! 所以上面那种想法是绝对不可取的! 如果你胡乱设置一个特别大的内存给buffer,会导致你的mysql启动失败的,他启动的时候就发现操作系统的内存根本不够用! 所以通常来说,我们建议一个比较合理的、健康的比例,是给buffer pool设置你的机器内存的50%~60%左右 比如你有32GB的机器,那么给buffer设置个20GB的内存,剩下的留给OS和其他人来用,这样比较合理一些。 假设你的机器是128GB的内存,那么buffer pool可以设置个80GB左右,大概就是这样的一个规则。
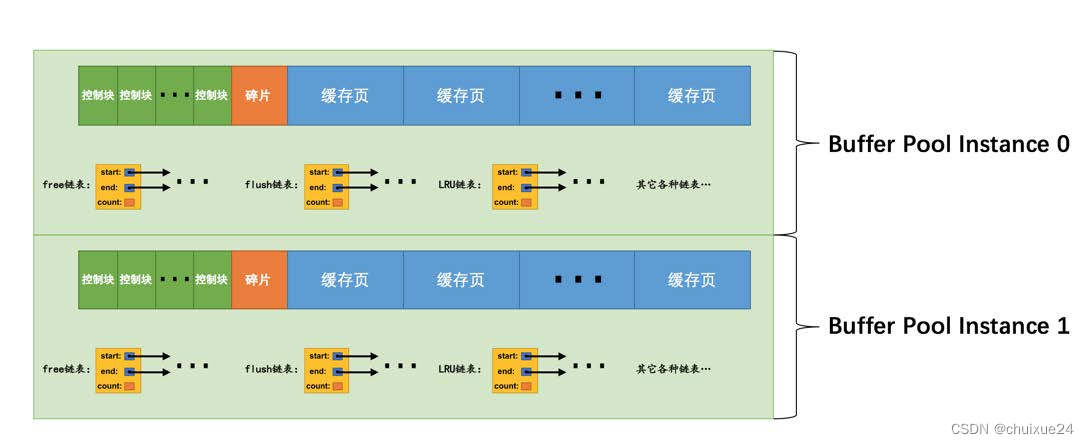
2、buffer pool总大小=(chunk大小 * buffer pool数量)的2倍数
接着确定了buffer pool的总大小之后,就得考虑一下设置多少个buffer pool,以及chunk的大小。 此时有一个很关键的公式:buffer pool总大小 = (chunk大小 * buffer pool数量) 的倍数 比如默认的chunk大小是128MB,那么此时如果你的机器的内存是32GB,你打算给buffer pool总大小在20GB左右,此时你的buffer pool的数量应该是多少个呢?
假设你的buffer pool的数量是16个,这是没问题的,那么此时chunk大小 * buffer pool的数量 = 16 * 128MB = 2048MB,然后buffer pool总大小如果是20GB,此时buffer pool总大小就是2048MB的10倍,这就符合规则了。 当然,此时你可以设置多一些buffer pool数量,比如设置32个buffer pool,那么此时buffer pool总大小(20GB)就是(chunk大小128MB * 32个buffer pool)的5倍,也是可以的。 那么此时你的buffer pool大小就是20GB,然后buffer pool数量是32个,每个buffer pool的大小是640MB,然后每个buffer pool包含5个128MB的chunk,算下来就是这么一个结果了。
3、一点总结
数据库在生产环境运行时,必须根据机器的内存设置合理的buffer pool的大小,然后设置buffer pool的数量,这样可以尽可能的保证你的数据库的高性能和高并发能力。 在线上运行时,buffer pool是有多个的,每个buffer pool里多个chunk但是共用一套链表数据结构,然后执 行crud的时候,就会不停的加载磁盘上的数据页到缓存页里来,然后会查询和更新缓存页里的数据,同时维护一系列的链表结构。 然后后台线程定时根据lru链表和flush链表,去把一批缓存页刷入磁盘释放掉这些缓存页,同时更新free链表。 如果执行crud的时候发现缓存页都满了,没法加载自己需要的数据页进缓存,此时就会把lru链表冷数据区域的缓存页刷入磁盘,然后加载自己需要的数据页进来。 整个buffer pool的结构设计以及工作原理,就是上面我们总结的这套东西了,大家只要理解了这个,首先你对MySQL执行crud的时候,是如何在内存里查询和更新数据的,你就彻底明白了。
接着我们后面继续探索undo log、redo log、事务机制、事务隔离、锁机制,这些东西,一点点就把MySQL他的数据更新、事务、锁这些原理,全部搞清楚了,同时中间再配合穿插一些生产经验、实战案例。
4、SHOW ENGINE INNODB STATUS
当你的数据库启动之后,你随时可以通过上述命令,去查看当前innodb里的一些具体情况,执行SHOW ENGINE INNODB STATUS就可以了。此时你可能会看到如下一系列的东西:
Total memory allocated xxxx; Dictionary memory allocated xxx Buffer pool size xxxx Free buffers xxx Database pages xxx Old database pages xxxx Modified db pages xx Pending reads 0 Pending writes: LRU 0, flush list 0, single page 0 Pages made young xxxx, not young xxx xx youngs/s, xx non-youngs/s Pages read xxxx, created xxx, written xxx xx reads/s, xx creates/s, 1xx writes/s Buffer pool hit rate xxx / 1000, young-making rate xxx / 1000 not xx / 1000 Pages read ahead 0.00/s, evicted without access 0.00/s, Random read ahead 0.00/s LRU len: xxxx, unzip_LRU len: xxx I/O sum[xxx]:cur[xx], unzip sum[16xx:cur[0]
下面解释一下这里的东西,主要讲解这里跟buffer pool相关的一些东西。
-
Total memory allocated,这就是说buffer pool最终的总大小是多少
-
Buffer pool size,这就是说buffer pool一共能容纳多少个缓存页
-
Free buffers,这就是说free链表中一共有多少个空闲的缓存页是可用的
-
Database pages和Old database pages,就是说lru链表中一共有多少个缓存页,以及冷数据区域里的缓存页数量
-
Modified db pages,这就是flush链表中的缓存页数量
-
Pending reads和Pending writes,等待从磁盘上加载进缓存页的数量,还有就是即将从lru链表中刷入磁盘的数量、即将从flush链表中刷入磁盘的数量
-
Pages made young和not young,这就是说已经lru冷数据区域里访问之后转移到热数据区域的缓存页的数 量,以及在lru冷数据区域里1s内被访问了没进入热数据区域的缓存页的数量
-
youngs/s和not youngs/s,这就是说每秒从冷数据区域进入热数据区域的缓存页的数量,以及每秒在冷数据区域里被访问了但是不能进入热数据区域的缓存页的数量
-
Pages read xxxx, created xxx, written xxx,xx reads/s, xx creates/s, 1xx writes/s,这里就是说已经读取、创建和写入了多少个缓存页,以及每秒钟读取、创建和写入的缓存页数量
-
Buffer pool hit rate xxx / 1000,这就是说每1000次访问,有多少次是直接命中了buffer pool里的缓存的
-
young-making rate xxx / 1000 not xx / 1000,每1000次访问,有多少次访问让缓存页从冷数据区域移动到了热数据区域,以及没移动的缓存页数量
-
LRU len:这就是lru链表里的缓存页的数量
-
I/O sum:最近50s读取磁盘页的总数
-
I/O cur:现在正在读取磁盘页的数量
bufferpoll实例个数及chunk个数:
innodb_buffer_pool_instances
innodb_buffer_pool_chunk_size