Pandas可处理的数据格式
处理CSV 文件
CSV(Comma-Separated Values,逗号分隔值,有时也称为字符分隔值,因为分隔字符也可以不是逗号),其文件以纯文本形式存储表格数据(数字和文本)。
Pandas 可以很方便的处理 CSV 文件,本文以 nba.csv 为例,你可以下载 nba.csv 或打开 nba.csv 查看。
import pandas as pd
df = pd.read_csv('nba.csv')
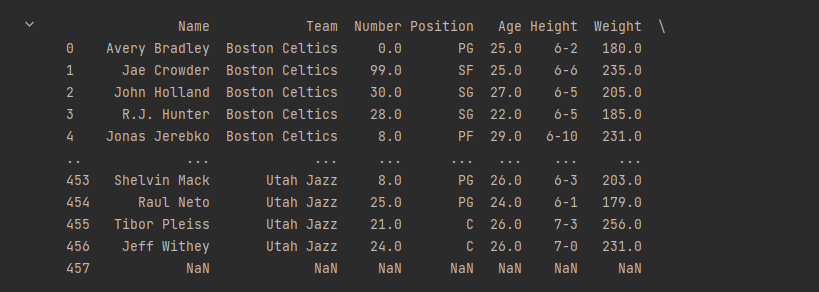
print(df.to_string())
to_string() 用于返回 DataFrame 类型的数据,如果不使用该函数,则输出结果为数据的前面 5 行和末尾 5 行,中间部分以 … 代替。
我们也可以使用 to_csv() 方法将 DataFrame 存储为 csv 文件:
import pandas as pd
# 三个字段 name, site, age
nme = ["Google", "Runoob", "Taobao", "Wiki"]
st = ["www.google.com", "www.runoob.com", "www.taobao.com", "www.wikipedia.org"]
ag = [90, 40, 80, 98]
# 字典
dict = {
'name': nme, 'site': st, 'age': ag}
df = pd.DataFrame(dict)
# 保存 dataframe
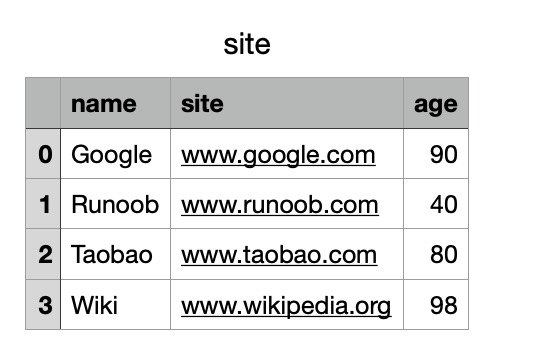
df.to_csv('site.csv')
执行成功后,我们打开 site.csv 文件,显示结果如下:
数据处理
head()
head( n ) 方法用于读取前面的 n 行,如果不填参数 n ,默认返回 5 行。
tail()
tail( n ) 方法用于读取尾部的 n 行,如果不填参数 n ,默认返回 5 行,空行各个字段的值返回 NaN。
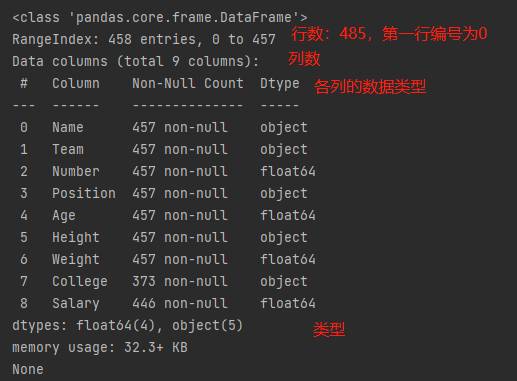
info()
info() 方法返回表格的一些基本信息:(下面为基本信息)
处理JSON格式数据
标准的JSON格式文件
Pandas 可以很方便的处理 JSON 数据,本文以 sites.json 为例,内容如下:
[
{
"id": "A001",
"name": "菜鸟教程",
"url": "www.runoob.com",
"likes": 61
},
{
"id": "A002",
"name": "Google",
"url": "www.google.com",
"likes": 124
},
{
"id": "A003",
"name": "淘宝",
"url": "www.taobao.com",
"likes": 45
}
]
to_string() 用于返回 DataFrame 类型的数据,我们也可以直接处理 JSON 字符串。
import pandas as pd
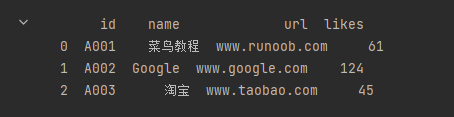
df = pd.read_json('sites.json')
print(df.to_string())
输出结果为:
JSON 对象与 Python 字典具有相同的格式,所以我们可以直接将 Python 字典转化为 DataFrame 数据:
import pandas as pd
# 字典格式的 JSON
s = {
"col1":{
"row1":1,"row2":2,"row3":3},
"col2":{
"row1":"x","row2":"y","row3":"z"}
}
# 读取 JSON 转为 DataFrame
df = pd.DataFrame(s)
print(df)
输出结果为:
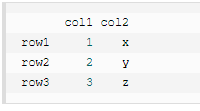
内嵌的 JSON 数据
假设有一组内嵌的 JSON 数据文件 nested_list.json :
{
"school_name": "ABC primary school",
"class": "Year 1",
"students": [
{
"id": "A001",
"name": "Tom",
"math": 60,
"physics": 66,
"chemistry": 61
},
{
"id": "A002",
"name": "James",
"math": 89,
"physics": 76,
"chemistry": 51
},
{
"id": "A003",
"name": "Jenny",
"math": 79,
"physics": 90,
"chemistry": 78
}]
}
使用以下代码格式化完整内容:
import pandas as pd
df = pd.read_json('nested_list.json')
print(df)
输出结果为:
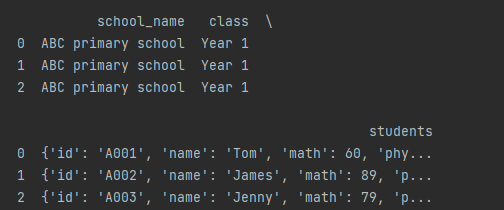
这时我们就需要使用到 json_normalize() 方法将内嵌的数据完整的解析出来:
mport pandas as pd
import json
# 使用 Python JSON 模块载入数据
with open('nested_list.json','r') as f:
data = json.loads(f.read())
# 展平数据
df_nested_list = pd.json_normalize(
data,
record_path =['students'],
meta=['school_name', 'class']
)
print(df_nested_list)
data = json.loads(f.read()) 使用 Python JSON 模块载入数据。
json_normalize() 使用了参数 record_path 并设置为 [‘students’] 用于展开内嵌的 JSON 数据 students。
显示结果还没有包含 school_name 和 class 元素,如果需要展示出来可以使用 meta 参数来显示这些元数据:

更复杂嵌套:点击查看