Redis中的数据结构(四):字典
字典即哈希表,这是计算机领域非常常见的一种数据结构,对于哈希表本身的介绍这里就不多做赘述,直接看Redis中是如何实现字典这一数据结构的。
一. 哈希函数和哈希冲突
Redis中用一个数组来作为哈希表,哈希函数将字符串类型的健映射为一个整数,这个整数与数组的大小取模,作为哈希表中的数组下标,当发生哈希冲突时,采用链地址法解决哈希冲突,每次插入Entry时会插在链表的头部。在4.0版本前采用的是murmurhash2作为哈希函数,4.0后改用siphash,关于siphash的细节可以看这篇文章:【密码学】一文读懂SipHash
siphash函数将字符串类型的健映射为一个整数,但Redis却可以还接收整数、浮点数类型的键值,这是因为在Redis内部整数、浮点数类型都会被视为字符串类型,例如浮点数110.2会转换为字符串“110.2”
二. 数据结构
1. dictht
Redis中,hash表的数据结构如下
typedef struct dictht {
dictEntry **table;
unsigned long size;
unsigned long sizemask;
unsigned long used;
} dictht;
- dictEntry **table:指向存储键值对数组的指针
- unsigned long size:table数组的大小
- unsigned long sizemask:掩码,用来进行取模计算,始终等于size-1
- unsigned long used:table数组已经存储的元素的个数
2. dictEntry
表节点dictEntry的数据结构如下
typedef struct dictEntry {
void *key;
union {
void *val;
uint64_t u64;
int64_t s64;
double d;
} v;
struct dictEntry *next;
} dictEntry;
void *key:键
void *val, uint64_t u64, int64_t s64, double d:组成一个联合体,共同用来保存值的信息,在不同的场景下会使用不同的字段,一般来说,值会保存在val字段中
struct dictEntry *next:采用链地址法解决哈希冲突,next指向冲突的元素,形成链表
3. dict
Redis在 dictht上做了更高一层的封装,也就是dict,这才是真正对外展示出的字典数据结构。dict结构如下:
typedef struct dict {
dictType *type;
void *privdata;
dictht ht[2];
long rehashidx; /* rehashing not in progress if rehashidx == -1 */
unsigned long iterators; /* number of iterators currently running */
} dict;
dictType *type:type里面保存了一些函数指针,这些函数是用来对dict进行一些特定的操作,后面会讲
void *privdata:用来保存一些私有的数据,一般不会用到
dictht ht[2]:dict里面有两个dictht,在对字典进行扩容和缩容时要用到两个dictht
long rehashidx:rehash标识,在扩容和缩容对哈希表rehash时会用到,如果为-1,表示现在没进行rehash操作
unsigned long iterators:dict的迭代标识,对dict进行迭代时会用到
4. dictType
dictType里面保存了对字典的一些特定操作的函数指针:
typedef struct dictType {
uint64_t (*hashFunction)(const void *key);
void *(*keyDup)(void *privdata, const void *key);
void *(*valDup)(void *privdata, const void *obj);
int (*keyCompare)(void *privdata, const void *key1, const void *key2);
void (*keyDestructor)(void *privdata, void *key);
void (*valDestructor)(void *privdata, void *obj);
} dictType;
uint64_t (*hashFunction)(const void *key):哈希函数
void *(*keyDup)(void *privdata, const void *key):健的复制函数
void *(*valDup)(void *privdata, const void *obj):值的复制函数
int (*keyCompare)(void *privdata, const void *key1, const void *key2):健的比较函数
void (*keyDestructor)(void *privdata, void *key):健的销毁函数
void (*valDestructor)(void *privdata, void *obj):值的销毁函数
在新创建一个dict时,可以自定义这些函数,这样对dict进行相应的操作时,可以进行一些扩展性的操作。同时Redis也提供了这些函数的默认实现,例如,对value的赋值操作:
//entry是需要被赋值的元素,_val_是赋给entry的value值
#define dictSetVal(d, entry, _val_) do {
\
if ((d)->type->valDup) \
(entry)->v.val = (d)->type->valDup((d)->privdata, _val_); \
else \
(entry)->v.val = (_val_); \
} while(0)
如果自定义了valDup函数,则调用valDup对_val_进行一份复制,然后赋值给entry->v.val,如果未定义,则直接赋值。
这里有个细节,赋值函数dictSetVal是宏定义的,在Redis中,有大量的地方采用宏来定义那些经常被调用的函数,采用宏的方式代替正常的函数调用,省去了参数压栈,返回参数,执行return等操作,提升程序执行的速率。
这样,一个完整的dict的数据结构如下所示:
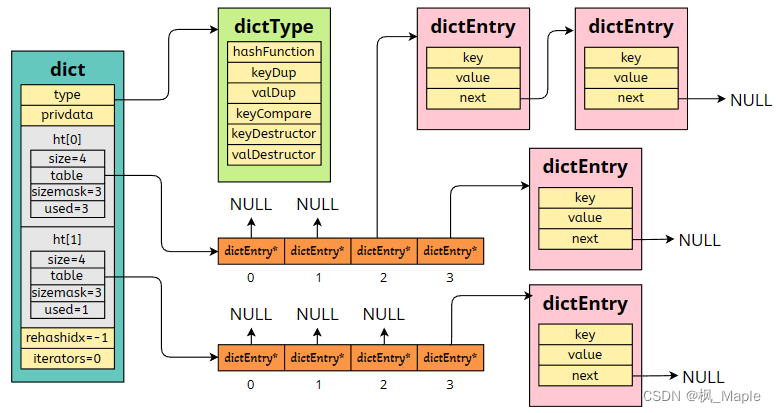
三. 字典的操作
对dict的操作可以归结为增删改查,但实际上只要弄清楚了其中一种操作的原理,另外的基本也差不多,这里介绍一下对dict的增加元素和扩容的原理。
1. 字典添加元素
dictAdd函数用来向一个dict中添加一个dictEntry。dictAdd会调用dictAddRaw函数,该函数会向dict中插入一个dictEntry,并返回这个dictEntry,注意这个dictEntry并没有设置val,如果插入成功,则会调用dictSetVal函数为这个dictEntry设置val,否则返回DICT_ERR。
/* Add an element to the target hash table */
int dictAdd(dict *d, void *key, void *val)
{
dictEntry *entry = dictAddRaw(d,key,NULL);
if (!entry) return DICT_ERR;
dictSetVal(d, entry, val);
return DICT_OK;
}
再来看一下dictAddRaw这个函数,这个函数会在dict中插入一个dictEntry,但不会设置val,然后返回这个dictEntry,让调用者按照自已的意愿来为这个dictEntry设置值。
如果dict中,该key已经存在了,则返回NULL,并且如果用户传入的existing参数不为NULL,则会将*existing指向已经存在的那个dictEntry。
dictEntry *dictAddRaw(dict *d, void *key, dictEntry **existing)
{
long index;
dictEntry *entry;
dictht *ht;
if (dictIsRehashing(d)) _dictRehashStep(d);
/* Get the index of the new element, or -1 if
* the element already exists. */
if ((index = _dictKeyIndex(d, key, dictHashKey(d,key), existing)) == -1)
return NULL;
/* Allocate the memory and store the new entry.
* Insert the element in top, with the assumption that in a database
* system it is more likely that recently added entries are accessed
* more frequently. */
ht = dictIsRehashing(d) ? &d->ht[1] : &d->ht[0];
entry = zmalloc(sizeof(*entry));
entry->next = ht->table[index];
ht->table[index] = entry;
ht->used++;
/* Set the hash entry fields. */
dictSetKey(d, entry, key);
return entry;
}
总结一下添加元素的步骤:
- 判断dict是否在进行rehash,如果是,则执行一次rehash(dict的rehash操作会在后面讲)
- 判断key在dict中是否已经存在,是则直接结束添加元素操作
- 利用哈希函数以及掩码(sizemask)得到该元素需要插入的数组下标
- new一个dictEntry,插入到对应数组下标的位置,如果发生哈希冲突,则插入到链表的头部
- 为dictEntry设置key
- 为dictEntry设置val
2. 哈希表的扩容、缩容、rehash操作
当哈希表的容量超过一定数量的时候,就会对哈希表进行扩容操作,也就是将哈希表的table的大小增加到原来的两倍,还记得之间讲dict的数据结构的时候说到dict里面有两个哈希表吗?
dictht ht[2];
进行扩容的时候,会在ht[1]上new一个dictht,新创建的dictht的大小比ht[0]更大,扩容完成后,再将ht[0]和ht[1]交换位置。
扩容只会在对dict进行添加元素操作的时候才会触发,因此每次向dict插入元素时,都会去检查是否达到触发扩容的条件,如果达到了,就会进行扩容,然后将老表(ht[0])上的元素全部转移到新表(ht[1])上,最后将ht[0]和ht[1]交换位置,这样扩容操作就算全部完成了。
将老表上的元素全部转移到新表的这个过程叫做rehash,如果一次将老表上的元素全部转移到新表上,当元素数量很多时,这个操作耗时巨大,且由于Redis是单线程工作,在rehash的过程中,整个Redis将处于不可用的状态,因此Redis中采用了一种叫做渐进式rehash的操作,即:
每次执行增删改查操作前,都会判断当前dict是否正在进行rehash,如果是,则调用_dictRehashStep函数进行一次rehash操作,一次rehash操作指的是只对哈希表的一个数组下标的元素进行rehash,这样在经历N次操作后(N为旧表中slot不为NULL的个数),ht[0]的所有元素都会迁移到ht[1]中,这样就把本应花费很长一段时间的rehash操作分散到了N次操作中,每次操作的时间的操作都会很短,这样对Redis对外提供服务的影响可以忽略不计。
具体的细节,我们可以通过代码来一步一步研究。我们先回到前面讲添加元素的dictAddRaw函数和_dictKeyIndex函数,在dictAddRaw函数中会判断dict现在是否在进行rehash,如果是则触发一次rehash操作:
if (dictIsRehashing(d)) _dictRehashStep(d);
在_dictKeyIndex函数中,会判断哈希表是否需要扩容:
static long _dictKeyIndex(dict *d, const void *key, uint64_t hash, dictEntry **existing)
{
unsigned long idx, table;
dictEntry *he;
if (existing) *existing = NULL;
/* Expand the hash table if needed */
if (_dictExpandIfNeeded(d) == DICT_ERR)
return -1;
for (table = 0; table <= 1; table++) {
idx = hash & d->ht[table].sizemask;
/* Search if this slot does not already contain the given key */
he = d->ht[table].table[idx];
while(he) {
if (key==he->key || dictCompareKeys(d, key, he->key)) {
if (existing) *existing = he;
return -1;
}
he = he->next;
}
//如果没有在进行rehash,则只会搜寻ht[0]
if (!dictIsRehashing(d)) break;
}
return idx;
}
_dictKeyIndex函数是在dictAddRaw函数中被调用的,他的作用是计算将要被添加的元素应该被插入的数组下标并且判断哈希表中是否已经存在了相同的key,因为这个函数是可能在rehash过程中被调用的,因此如果dict正在进行rehash,它会搜寻ht[0]和ht[1],并且返回的是ht[1]数组下标,如果没有进行rehash,则只需要搜寻ht[0]。
我们先来看一下_dictExpandIfNeeded函数,他的作用是判断字典是否需要扩容,如果需要则会调用dictExpand函数触发扩容。
static int _dictExpandIfNeeded(dict *d)
{
//如果正在进行rehash,显然不需要再扩容了
if (dictIsRehashing(d)) return DICT_OK;
//dict刚初始化后哈希表是空的,此时肯定需要扩容,并且扩容后的size为DICT_HT_INITIAL_SIZE
if (d->ht[0].size == 0) return dictExpand(d, DICT_HT_INITIAL_SIZE);
/* If we reached the 1:1 ratio, and we are allowed to resize the hash
* table (global setting) or we should avoid it but the ratio between
* elements/buckets is over the "safe" threshold, we resize doubling
* the number of buckets. */
//判断扩容的条件是used和size的数量关系,简单来说,只有当哈希表装填因子达到一定大小,才会触发扩容
if (d->ht[0].used >= d->ht[0].size &&
(dict_can_resize ||
d->ht[0].used/d->ht[0].size > dict_force_resize_ratio))
{
return dictExpand(d, d->ht[0].used*2);
}
return DICT_OK;
}
再来看一下dictExpand函数,该函数接收两个参数dict *d, unsigned long size,d为要扩容的dict,size为扩容后的大小,注意这个size不是ht[0].size,而是扩容后应该达到的size,即ht[1]的size。该函数的过程总结如下:
- 如果正在进行rehash,肯定不能扩容;或者size的大小比used还小,那么这个传进来的size的大小是非法的,也不能扩容。直接返回。
- 对传进来的size的大小进行修正,保证扩容后的大小一定是2的n次方。例如,如果传进来的size为10,实际上会修正为2^4=16。
- 如果修正后的大小还是等于ht[0].size,等于没有扩容,直接返回DICT_ERR。
- 为扩容后的新dictht分配空间,设置相应的属性。
- 如果dict是刚被初始化的,直接将ht[0]赋为新创建的dictht。
- 如果不是,则将ht[1]赋值为新创建的dictht,并设置dict的rehashidx属性为0。
/* Expand or create the hash table */
int dictExpand(dict *d, unsigned long size)
{
/* the size is invalid if it is smaller than the number of
* elements already inside the hash table */
//1.如果正在进行rehash,肯定不能扩容;
//或者size的大小比used还小,那么这个传进来的size的大小是非法的,也不能扩容。直接返回
if (dictIsRehashing(d) || d->ht[0].used > size)
return DICT_ERR;
//2.对传进来的size的大小进行修正,保证扩容后的大小一定是2的n次方
//例如,如果传进来的size为10,实际上会修正为2^4=16
dictht n; /* the new hash table */
unsigned long realsize = _dictNextPower(size);
//3.如果修正后的大小还是等于ht[0].size,等于没有扩容,直接返回DICT_ERR
/* Rehashing to the same table size is not useful. */
if (realsize == d->ht[0].size) return DICT_ERR;
//4.为扩容后的新dictht分配空间,设置属性
/* Allocate the new hash table and initialize all pointers to NULL */
n.size = realsize;
n.sizemask = realsize-1;
n.table = zcalloc(realsize*sizeof(dictEntry*));
n.used = 0;
/* Is this the first initialization? If so it's not really a rehashing
* we just set the first hash table so that it can accept keys. */
//5.如果dict是刚被初始化的,直接将ht[0]赋为新创建的dictht
if (d->ht[0].table == NULL) {
d->ht[0] = n;
return DICT_OK;
}
//6.如果不是,则将ht[1]赋值为新创建的dictht,并设置dict的rehashidx属性为0
/* Prepare a second hash table for incremental rehashing */
d->ht[1] = n;
d->rehashidx = 0;
return DICT_OK;
}
接下来看一下rehash操作,_dictRehashStep函数实际上调用了dictRehash,该函数会对哈希表进行n次rehash操作。每次rehash操作,都会将ht[0].table[rehashidx]上的所有元素rehash到ht[1].table上,并将rehashidx+1。此外,如果这个过程中ht[0]上为NULL的slot超过了n*10,dictRehash函数会直接返回,防止ht[0]上有太多为NULL的slot导致dictRehash执行时间过长。
/* This function performs just a step of rehashing, and only if there are
* no safe iterators bound to our hash table. When we have iterators in the
* middle of a rehashing we can't mess with the two hash tables otherwise
* some element can be missed or duplicated.
*
* This function is called by common lookup or update operations in the
* dictionary so that the hash table automatically migrates from H1 to H2
* while it is actively used. */
static void _dictRehashStep(dict *d) {
if (d->iterators == 0) dictRehash(d,1);
}
/* Performs N steps of incremental rehashing. Returns 1 if there are still
* keys to move from the old to the new hash table, otherwise 0 is returned.
*
* Note that a rehashing step consists in moving a bucket (that may have more
* than one key as we use chaining) from the old to the new hash table, however
* since part of the hash table may be composed of empty spaces, it is not
* guaranteed that this function will rehash even a single bucket, since it
* will visit at max N*10 empty buckets in total, otherwise the amount of
* work it does would be unbound and the function may block for a long time. */
int dictRehash(dict *d, int n) {
int empty_visits = n*10; /* Max number of empty buckets to visit. */
if (!dictIsRehashing(d)) return 0;
while(n-- && d->ht[0].used != 0) {
dictEntry *de, *nextde;
/* Note that rehashidx can't overflow as we are sure there are more
* elements because ht[0].used != 0 */
assert(d->ht[0].size > (unsigned long)d->rehashidx);
while(d->ht[0].table[d->rehashidx] == NULL) {
d->rehashidx++;
if (--empty_visits == 0) return 1;
}
de = d->ht[0].table[d->rehashidx];
/* Move all the keys in this bucket from the old to the new hash HT */
while(de) {
uint64_t h;
nextde = de->next;
/* Get the index in the new hash table */
h = dictHashKey(d, de->key) & d->ht[1].sizemask;
de->next = d->ht[1].table[h];
d->ht[1].table[h] = de;
d->ht[0].used--;
d->ht[1].used++;
de = nextde;
}
d->ht[0].table[d->rehashidx] = NULL;
d->rehashidx++;
}
/* Check if we already rehashed the whole table... */
if (d->ht[0].used == 0) {
zfree(d->ht[0].table);
d->ht[0] = d->ht[1];
_dictReset(&d->ht[1]);
d->rehashidx = -1;
return 0;
}
/* More to rehash... */
return 1;
}