1 GAN基础介绍
GAN论文:https://arxiv.org/abs/1406.2661(沐神说arxiv版本的related work写的不是很好)
GAN是一个框架,其中包含两个模型:生成模型G(Generator)和判别模型D(Discriminator)。其中,G的作用是抓取数据分布,尽量做到让判别模型犯错;而D的作用在于区分数据是来自于真实训练的数据集还是G生成的fake数据。二者均可为MLP结构。
本篇文章主要是让小白通过代码了解GAN的结构和运作机制,同时还采用MNIST手写数据集(不得不说这个数据集对于新手来说非常好用)来作为我们的训练数据,我们将构建一个简单的GAN来进行手写数字图像的生成。

这可以看做一种零和游戏。拿一个电影来举栗子,《猫鼠游戏》中,小李子饰演的小弗兰克可以视为生成器G,主要进行支票的造假,而擅长冷笑话的卡尔则可以视为判别器D,抛开结局不谈,俩者之间始终是一种相互博弈的状态 ,而在相互博弈的过程中,弗兰克的造假技术不断提高,当然卡尔的业务能力也在提升...
结合整体模型图示,再以生成图片作为例子具体说明下面。我们有两个网络,G(Generator)和D(Discriminator)。Generator是一个生成图片的网络,它接收一个随机的噪声z,通过这个噪声生成图片,记做G(z)。Discriminator是一个判别网络,判别一张图片是不是“真实的”。它的输入是x,x代表一张图片,输出D(x)代表x为真实图片的概率,如果为1,就代表100%是真实的图片,而输出为0,就代表不可能是真实的图片。
注:一直不明白判别算法与生成算法的区别,特意记录一下~
判别算法:给定实例的一些特征,根据这些特征来判断其所属的类别,实质是建模特征与标签之间的关系。我们可以使用后验概率来建模判别算法。假设一个数据的特征为x,标签为y,判别算法即为在给定x的条件下,标签为y的概率:p(y|x)。
生成算法则不关心数据标签是什么,其关注的是能否生成和数据x同一分布的特征。
2 GAN详解
2.1 基础知识
GAN是由两个模型组成的系统(D和G),前边已经介绍过,不再赘述。
GAN论文中,G和D均为MLP。
判别器任务:判别输入的数据来自于真实训练数据集还是生成器生成的数据。一般使用二分类的神经网络来构建,通常是将取自训练数据集的样本视作正样本,G生成的样本标记为负样本。
生成器任务:接收随机噪声,然后使用反卷积网络来创建一个数据(论文中为图像),生成器的随机输入可以看作为一个种子,相同的种子会得到相同的生成数据,因此大量种子的作用是保证生成数据的多样性。
GAN的双系统的目的是让生成器尽量去迷惑判别器,同时让判别器尽可能的对输入数据(文中为图像)进行判别。
两个模型之间是相互对抗的关系,它们都会通过试图击败对方使自己变得更好。
2.2 优化训练
最终结果是G和D之间动态的“博弈过程”达到了纳什均衡。
纳什均衡:指博弈中这样的局面:对于每个参与者来说,只要其他人不改变策略,他就无法改善自己的状况。
对应的,在GAN中,情况就是生成模型G造出了与真实数据一模一样的样本,判别模型D再也判别不出结果,准确率为50%,约等于乱猜。此时双方网络都得到利益最大化,不再改变自己的策略,也就是不再更新自己的权重。
基本流程:
1.初始化参数![]() 与
与![]() ;
;
2.从分布为![]() 数据集中采样m个真实样本{
数据集中采样m个真实样本{
![]() ,...,
,...,![]() },同时从噪声先验分布
},同时从噪声先验分布![]() 中采样m个噪声样本{
中采样m个噪声样本{
![]() ,...,
,...,![]() },并且使用生成器获得m个生成样本:{
},并且使用生成器获得m个生成样本:{
![]() ,...,
,...,![]() };
};
3.固定生成器,使用梯度上升策略训练判别器使其能够更好的判别样本的来源:
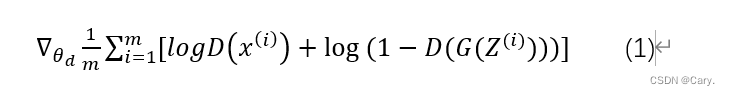
4.循环多次判别器的训练后,我们使用 较小的学习率对生成器进行优化,生成器使用梯度下降策略进行优化:
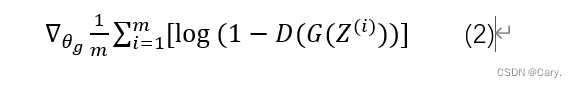
5.多次更新之后,我们的理想状态就是生成器生成一个判别器无法判别的样本,即最终判别器的准确率为0.5。
注:之所以先循环多次优化判别器,再优化生成器,是因为我们想要先拥有一个有一定效果的判别器,它能够比较正确的区分真实样本与生成样本,这样我们才能根据判别器的反馈对生成器进行优化。
2.3 GAN的损失函数
GAN的目标是让生成器生成足以欺骗判别器的样本。
从数学角度来看,我们希望生成的样本与真实样本拥有相同的概率分布,也就是生成样本与真实样本拥有相同的概率密度函数,即:

这个结论是GAN的理论基础。
GAN的损失函数源自于二分类对数似然函数的交叉熵损失函数:
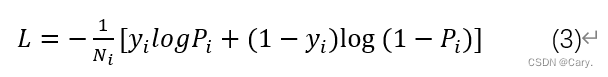
其中,方括号中第一项作用是使正样本的识别结果尽量为1,第二项则是使负样本的识别结果尽量为0.
我们要求判别器D能够将满足![]() 分布的样本识别为正样本,故有:
分布的样本识别为正样本,故有:
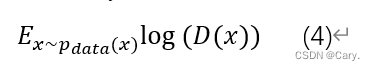
我们最大化此项使D将真实样本预测为1。
loss function的另一项与生成器有关,来自于对数似然函数的“负类”:
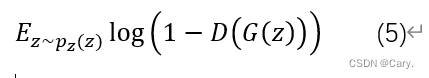
我们通过最大化此项,也就是使D(G(z))的值趋近于0,即希望判别器能够将生成器产生的样本判别为负样本。
结合以上两式,得到:
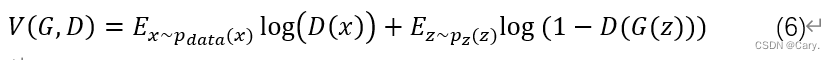
在给定G的前提下,我们假设此时得到的最优判别器表示为![]() ,即:
,即:

然鹅在实际场景中,我们室无法得到 ![]() 的。
的。
生成器的优化目标和判别器相反,它的目的是让判别器的分类效果尽可能的差。换句话说,当判别器优化到其全局最优值之后,即D=![]() 。我们要对生成器进行优化,目的是最小化式(7)。
。我们要对生成器进行优化,目的是最小化式(7)。
最终便得到最优生成器G*:

综上,我们可以得到论文中使用的G和D的极大极小博弈的loss function:
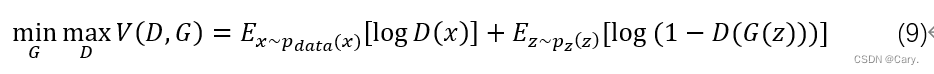
理论证明下篇再写(脑阔疼)
3 代码
核心代码:判别器与生成器网络的搭建:
判别器:
class discriminator(nn.Module):
def __init__(self):
super(discriminator, self).__init__()
self.dis = nn.Sequential(
nn.Linear(784, 256), # 输入特征数为784,输出为256,(28*28)
nn.LeakyReLU(0.2), # 进行非线性映射
nn.Linear(256, 256), # 进行一个线性映射
nn.LeakyReLU(0.2),
nn.Linear(256, 1),
nn.Sigmoid() # 也是一个激活函数,二分类问题中,
# sigmoid可以班实数映射到【0,1】,作为概率值,
# 多分类用softmax函数
)
def forward(self, x):
x = self.dis(x)
return x生成器:
class generator(nn.Module):
def __init__(self):
super(generator, self).__init__()
self.gen = nn.Sequential(
nn.Linear(100, 256), # 用线性变换将输入映射到256维
nn.ReLU(True), # relu激活
nn.Linear(256, 256), # 线性变换
nn.ReLU(True), # relu激活
nn.Linear(256, 784), # 线性变换
nn.Tanh() # Tanh激活使得生成数据分布在【-1,1】之间,因为输入的真实数据的经过transforms之后也是这个分布
)
def forward(self, x):
x = self.gen(x)
return x全部代码:
import matplotlib.pyplot as plt
import torch.autograd
import torch.nn as nn
from torch.autograd import Variable
from torchvision import transforms
from torchvision import datasets
from torchvision.utils import save_image
import os
# 创建文件夹
if not os.path.exists('./img'):
os.mkdir('./img')
def to_img(x):
out = 0.5 * (x + 1)
out = out.clamp(0, 1) # Clamp函数可以将随机变化的数值限制在一个给定的区间[min, max]内:
out = out.view(-1, 1, 28, 28) # view()函数作用是将一个多行的Tensor,拼接成一行
return out
batch_size = 128
num_epoch = 100
z_dimension = 100
# 图像预处理
img_transform = transforms.Compose([
transforms.ToTensor(),
transforms.Normalize((0.5,), (0.5,)) # (x-mean) / std
])
# mnist数据集下载
mnist = datasets.MNIST(
root='./data/', train=True, transform=img_transform, download=True
)
# data loader 数据载入
dataloader = torch.utils.data.DataLoader(
dataset=mnist, batch_size=batch_size, shuffle=True
)
# 定义判别器 #####Discriminator######使用多层网络来作为判别器
# 将图片28x28展开成784,然后通过多层感知器,中间经过斜率设置为0.2的LeakyReLU激活函数,
# 最后接sigmoid激活函数得到一个0到1之间的概率进行二分类。
class discriminator(nn.Module):
def __init__(self):
super(discriminator, self).__init__()
self.dis = nn.Sequential(
nn.Linear(784, 256), # 输入特征数为784,输出为256,(28*28)
nn.LeakyReLU(0.2), # 进行非线性映射
nn.Linear(256, 256), # 进行一个线性映射
nn.LeakyReLU(0.2),
nn.Linear(256, 1),
nn.Sigmoid() # 也是一个激活函数,二分类问题中,
# sigmoid可以班实数映射到【0,1】,作为概率值,
# 多分类用softmax函数
)
def forward(self, x):
x = self.dis(x)
return x
# ###### 定义生成器 Generator #####
# 输入一个100维的0~1之间的高斯分布,然后通过第一层线性变换将其映射到256维,
# 然后通过LeakyReLU激活函数,接着进行一个线性变换,再经过一个LeakyReLU激活函数,
# 然后经过线性变换将其变成784维,最后经过Tanh激活函数是希望生成的假的图片数据分布能够在-1~1之间。
class generator(nn.Module):
def __init__(self):
super(generator, self).__init__()
self.gen = nn.Sequential(
nn.Linear(100, 256), # 用线性变换将输入映射到256维
nn.ReLU(True), # relu激活
nn.Linear(256, 256), # 线性变换
nn.ReLU(True), # relu激活
nn.Linear(256, 784), # 线性变换
nn.Tanh() # Tanh激活使得生成数据分布在【-1,1】之间,因为输入的真实数据的经过transforms之后也是这个分布
)
def forward(self, x):
x = self.gen(x)
return x
# 创建对象
D = discriminator()
G = generator()
if torch.cuda.is_available():
D = D.cuda()
G = G.cuda()
# 首先需要定义loss的度量方式 (二分类的交叉熵)
# 其次定义 优化函数,优化函数的学习率为0.0003
criterion = nn.BCELoss() # 是单目标二分类交叉熵函数
d_optimizer = torch.optim.Adam(D.parameters(), lr=0.0003)
g_optimizer = torch.optim.Adam(G.parameters(), lr=0.0003)
# ##########################进入训练##判别器的判断过程#####################
dloss_real_list = []
dloss_fake_list = []
d_loss_list = []
g_loss_list = []
real_scores_list = []
for epoch in range(num_epoch): # 进行多个epoch的训练
for i, (img, _) in enumerate(dataloader):
num_img = img.size(0)
# view()函数作用是将一个多行的Tensor,拼接成一行
# 第一个参数是要拼接的tensor,第二个参数是-1
# =============================训练判别器=================================================
img = img.view(num_img, -1) # 将图片展开为28*28=784
real_img = Variable(img).cuda() # 将tensor变成Variable放入计算图中
real_label = Variable(torch.ones(num_img)).cuda() # 定义真实的图片label为1
fake_label = Variable(torch.zeros(num_img)).cuda() # 定义假的图片的label为0
# ########判别器训练train#####################
# 分为两部分:1、真的图像判别为真;2、假的图像判别为假
# 计算真实图片的损失
real_out = D(real_img) # 将真实图片放入判别器中
# real_scores_list.append(real_out.cpu().detach().numpy())
# real_scores_list.append(real_out.data.item())
real_out = real_out.squeeze() # (128,1) -> (128,)
d_loss_real = criterion(real_out, real_label) # 得到真实图片的loss
dloss_real_list.append(d_loss_real.data.item())
real_scores = real_out # 得到真实图片的判别值,输出的值越接近1越好
# print(real_scores)
real_scores_list.append(real_scores.cpu().detach().numpy())
# real_scores_list.append(real_scores.data.item())
# 计算假的图片的损失
z = Variable(torch.randn(num_img, z_dimension)).cuda() # 随机生成一些噪声
fake_img = G(z).detach() # 随机噪声放入生成网络中,生成一张假的图片。 # 避免梯度传到G,因为G不用更新, detach分离
fake_out = D(fake_img) # 判别器判断假的图片,
fake_out = fake_out.squeeze() # (128,1) -> (128,)
d_loss_fake = criterion(fake_out, fake_label) # 得到假的图片的loss
dloss_fake_list.append(d_loss_fake.data.item())
fake_scores = fake_out # 得到假图片的判别值,对于判别器来说,假图片的损失越接近0越好
# 损失函数和优化
d_loss = (d_loss_real + d_loss_fake)/2 # 损失包括判真损失和判假损失
d_loss_list.append(d_loss.data.item())
d_optimizer.zero_grad() # 在反向传播之前,先将梯度归0
d_loss.backward() # 将误差反向传播
d_optimizer.step() # 更新参数
# ==================训练生成器============================
# ###############################生成网络的训练###############################
# 原理:目的是希望生成的假的图片被判别器判断为真的图片,
# 在此过程中,将判别器固定,将假的图片传入判别器的结果与真实的label对应,
# 反向传播更新的参数是生成网络里面的参数,
# 这样可以通过更新生成网络里面的参数,来训练网络,使得生成的图片让判别器以为是真的
# 这样就达到了对抗的目的
# 计算假的图片的损失
z = Variable(torch.randn(num_img, z_dimension)).cuda() # 得到随机噪声
fake_img = G(z) # 随机噪声输入到生成器中,得到一副假的图片
output = D(fake_img) # 经过判别器得到的结果
output = output.squeeze()
g_loss = criterion(output, real_label) # 得到的假的图片与真实的图片的label的loss
g_loss_list.append(g_loss.data.item())
# bp and optimize
g_optimizer.zero_grad() # 梯度归0
g_loss.backward() # 进行反向传播
g_optimizer.step() # .step()一般用在反向传播后面,用于更新生成网络的参数
# 打印中间的损失
if (i + 1) % 100 == 0:
print('Epoch[{}/{}],d_loss:{:.6f},g_loss:{:.6f} '
'D real: {:.6f},D fake: {:.6f}'.format(
epoch, num_epoch, d_loss.data.item(), g_loss.data.item(),
real_scores.data.mean(), fake_scores.data.mean() # 打印的是真实图片的损失均值
))
if epoch == 0:
real_images = to_img(real_img.cpu().data)
save_image(real_images, './img/real_images.png')
fake_images = to_img(fake_img.cpu().data)
save_image(fake_images, './img/fake_images-{}.png'.format(epoch + 1))
# 保存模型
torch.save(G.state_dict(), './generator.pth')
torch.save(D.state_dict(), './discriminator.pth')
plt.figure(1)
plt.plot(real_scores_list[-1])
plt.ylabel("real_scores")
plt.savefig('./loss_image/scores.jpg')
plt.show()
plt.figure(2)
plt.subplot(2,2,1)
plt.plot(dloss_real_list)
plt.ylabel("dloss_real")
plt.subplot(2,2,2)
plt.plot(dloss_fake_list)
plt.ylabel("dloss_fake")
plt.subplot(2,2,3)
plt.plot(d_loss_list)
plt.ylabel("dloss(real+fake)/2")
plt.subplot(2,2,4)
plt.plot(g_loss_list)
plt.ylabel("gloss")
plt.savefig('./loss_image/loss.jpg')
plt.show()
迭代200轮结果:

生成的MNIST数据:


左为real_image,右为fake_image(200轮迭代后的结果)。效果一般,主要噪音有点多。