本文首先介绍基于会话的推荐的提出动机和背景,
然后说明其与序列推荐的区别,
并给出会话推荐的子领域
和目前使用的各种方法的分类框架,
最后提出当前领域下的未来展望。
—— 五行诗
一般的推荐(RS) vs 基于会话的推荐(SBRS)
一般的推荐
推荐系统可以帮助用户找到感兴趣的相关项目。在一般的推荐系统里,通常利用用户和物品的所有历史交互(interaction)来学习用户对物品的长期的、静态的偏好。这样的操作其实隐含了一种假设:所有历史的交互信息对预测用户当前偏好而言都是同等重要的。
但是这种假设在实际场景中不太正确,因为:
- 用户不仅有长期的过去的偏好,还存在短期偏好。这些短期偏好可以被最近的交互信息来刻画。(eg:虽然我一直都听古典音乐,但是最近有一两首流行音乐非常火,我也去听听看)
- 用户偏好还会随时间而改变,是动态的而非静态的。(eg:虽然我之前很喜欢听古典,但是现在我不喜欢了,我已经投入了流行音乐的怀抱)
基于会话的推荐
因此为了弥补这些差距,基于会话的推荐(Session-based Recommender Systems, SBRS)在近年被提出。SBRS以每个会话(session)做为基本的输入单元,能够捕捉到用户的短期的偏好和会话间的兴趣转移反映出的动态的偏好,从而提高推荐的准确性和及时性。
广义的SBRS可能有以下子领域:
- 预测下一个交互 (next-interaction) eg:预测下一个商品,歌曲/电影,POI,网页,新闻等
- 预测当前会话的剩余部分的交互 (next partitial-session recommendation) eg:预测下一个商品,会话/basket补全
- 预测下一个会话 *(next-session)*eg:Next basket 推荐,Next bundle 推荐
而狭义的SBRS就是指第一种。(基于当前session, 预测 next interaction)
序列推荐(SRS) vs 基于会话的推荐(SBRS)
(歧义:session间:是指一个session内部,还是会话与会话间?是后者,但要说明)
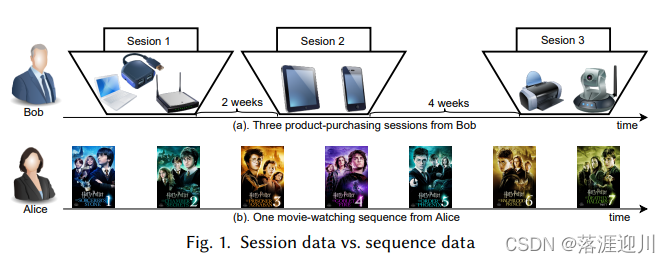
序列推荐(Sequential Recommendation Systems)是基于序列数据(sequence data)做出的推荐,而会话推荐是基于会话数据(session data)。二者非常相关,在表面上也很相似,因此会造成许多混淆。
首先给出会话数据和序列数据的定义:
- session:一个会话是一个有明显的开始和结束边界(boundary)的用户物品交互序列。一个会话内的这些交互可能是有序的(ordered)或者是无序的(unordered)。会话数据就是由许多发生在不同时间的,被许多边界分割开的会话们所组成的。会话与会话之间有不同的时间间隔(time interval)。
- sequence:一个序列就是一个有序的交互合集。一个用户的所有交互行为构成一条序列,因此只有一个边界。
有边界,就暗示了物品间有在某一段时间内共同出现的依赖(co-occurrence-based dependencies。这种共同出现的依赖就构成了SBRS的基础。(特别是当会话内的物品是无序时。)(eg: next-bastket推荐?对,可以视为是SBRS子领域)
在各个SBRS模型的实验部分,就有把用户-物品交互序列分割成各会话的操作描述。通常是通过指定一个time interval thredhold(eg:30分钟/ 8小时)。如果超过这个阈值,用户仍没有新的活动,则将之前的交互划分成一个session。
现在,我们可以区分基于会话的推荐和序列推荐:
- 基于会话的推荐:预测下一个交互/会话的剩余交互/下一个会话,且利用了co-occurrence-based 依赖。SBRS原则上并不要求用户-物品交互是有序的,所以并不利用sequential dependencies,当然若会话是有序的话,我们自然也可以利用。
- 序列推荐:基于序列数据,预测接下来的物品。利用序列依赖。
我们容易对会话推荐和序列推荐感到混淆,是因为现在SBRS研究很多都是基于有序会话,预测下一个交互(比较下面表格的第二行和第三行)。
区分的本质就是:是否利用了co-occurrence-based 依赖

基于会话的推荐的子领域

Session-based Recommendation System(SBRM)基于会话的推荐算法可分为三大类:
- Conventional SBRS approaches (传统方法)
- Latent representation based approaches (潜在表示模型)
- Deep neural network based approaches (基于深度神经网络的方法)
本文先详细介绍第一类Conventional SBRS approaches。 在推荐里,早期传统的方法通常采用数据挖掘,机器学习等技巧来捕捉序列数据中的相关依赖,其中包括知名的的Item-KNN, FPMC等常用于比较的baselines模型。理解这部分内容对入门有很大的帮助。下面将详细介绍四类传统的推荐算法
Patten/Rule Mining-based SBRSs(基于模式/规则的挖掘)
包括两种算法:
关联规则挖掘( Frequent Pattern/Association Rule Mining-based Approaches):
分为三步: ——评价:应该主要先介绍思想,而非介绍算法步骤。从整体上进行概括。
(1)找出频繁项集和关联规则
在所有的session(认为是user-item的交互序列)里,首先发现满足最小值尺度阈值的所有项集,这些项集称作频繁项集FP //计算P(AB)
频繁项集中满足最小置信度要求的,称为关联规则(Association Rule)//计算P(B|A)
(2)生成候选物品: 对物品集里的item ,若和当前session里的item,一起构成FP,则前者就可以放入
candidate item里
(3)生成推荐物品:对于candidate item,若其FP满足置信度的要求(是assostion rule),则可将其添加至recommendation list
评论:可以看到这种方法对session没有必须是有序的要求,但也没有考虑到序列性。说白了,只能计算共现概率。得到的关联规则,只能解释为这两个物品一起买的概率高。
序列模式挖掘( Sequential pattern mining-based approaches)
序列模式挖掘考虑到了序列性。根据最后一个购买行为(session),推荐出现在序列模式里的以这个session为起始的后一个session的物品(作为候选物品)。
序列模式挖掘和上述频繁项集挖掘的输入有所不同:序列集合VS物品集合
序列模式挖掘的输入是这样的数据:一行的数据是一个用户的所有session

频繁项集挖掘是输入的数据是这样:一行就是一个session。可能第1,2,3行都是来自同一用户的(不考虑用户)。虽然输入有序,但推荐时未考虑项之间的顺序,只考虑共现。

可见,若用户的每个session的长度都是1的话,序列模式挖掘可视为频繁项集挖掘。
序列挖掘步骤:和关联规则挖掘差不多,相当于把元素从一个物体变成了一个序列。仅此而已
(1)序列模式挖掘
(2)序列匹配
(3)生成推荐:候选物品:在挖掘到的序列规则里,与最末序列匹配的后一个序列里的物品。再为每个物品计算置信度。