这篇文章我将介绍这个主题并概述音频应用的深度学习前景。我们将了解什么是音频以及它是如何以数字方式表示的。我将讨论音频应用程序对我们日常生活的广泛影响,并探索它们使用的架构和模型技术。
什么是声音?
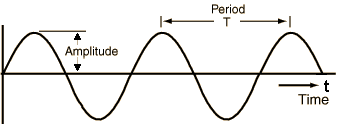
声音信号是由气压变化产生的,我们可以测量压力变化的强度并绘制这些测量值随时间的变化。声音信号通常以固定间隔重复,因此每个波具有相同的形状。高度表示声音的强度,称为振幅。信号完成一个全波所用的时间就是周期。信号在一秒钟内发出的波数称为频率。频率是周期的倒数。频率的单位是赫兹。也就是模拟信号。
我们遇到的大多数声音可能并不遵循如此简单和规律的周期性模式。但是可以将不同频率的信号加在一起以创建具有更复杂重复模式的复合信号。我们听到的所有声音,包括我们自己的人声,都是由这样的波形组成的。
我们如何以数字方式表示声音?
要将声波数字化,我们必须将信号转换为一系列数字,以便我们可以将其输入到模型中。这是通过以固定的时间间隔测量声音的幅度来完成的。
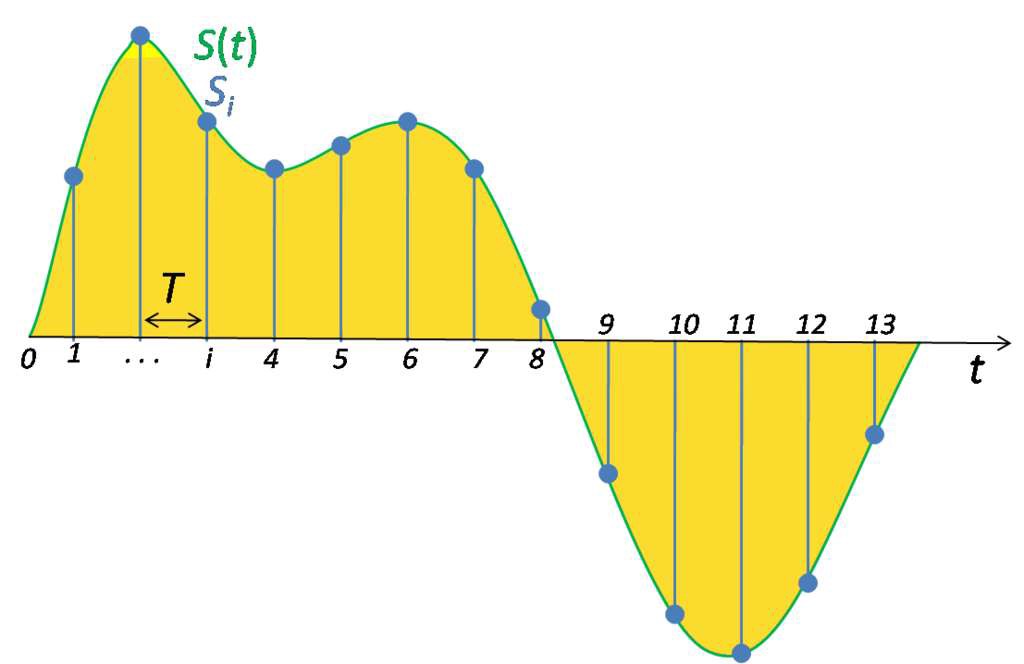
定期采样测量
对模拟信号进行采样,每个这样的测量称为一个样本,采样率是每秒的样本数。例如,常见的采样率约为每秒 44,100 个样本。这意味着一个 10 秒的音乐剪辑将有 441,000 个样本!
为深度学习模型准备音频数据
音频机器学习应用程序过去依赖传统的数字信号处理技术来提取特征。随着深度学习的普遍,不再需要传统的音频处理技术,不用大量手动和自定义特征。依靠准备好的数据。更有趣的是,通过深度学习,我们实际上并没有处理原始形式的音频数据。相反,常用的方法是将音频数据转换为图像,然后使用标准的 CNN 架构来处理这些图像!
这是通过从音频生成频谱图来完成的。所以首先让我们了解什么是频谱,并用它来理解频谱图。
频谱是组合在一起产生信号的一组频率。频谱绘制了信号中存在的所有频率以及每个频率的强度或幅度。
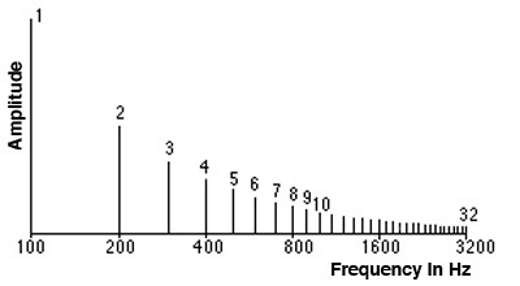
频谱显示构成声音信号的频率
信号中的最低频率称为基频。基频的整数倍的频率称为谐波。例如,如果基频为 200 Hz,则其谐波频率为 400 Hz、600 Hz 等。
时域与频域

由于 x 轴显示了信号的时间值范围,因此我们在时域中查看信号。频谱是表示相同信号的另一种方式。它显示幅度与频率的关系,并且由于 x 轴显示信号的频率值范围,因此在某个时刻,我们正在频域中查看信号。
频谱图
由于信号随时间变化而产生不同的声音,因此其组成频率也随时间变化。换句话说,它的频谱随时间而变化。
信号的频谱图随时间绘制其频谱,就像信号的“照片”。它在 x 轴上绘制时间,在 y 轴上绘制频率。就好像我们在不同的时间点一次又一次地拍摄光谱,然后将它们全部连接到一个情节中。
它使用不同的颜色来表示每个频率的幅度或强度。颜色越亮,信号的能量就越高。频谱图的每个垂直“切片”本质上是该时刻信号的频谱,并显示了信号强度在该时刻信号中每个频率的分布情况。
在下面的示例中,第一张图片显示了时域中的信号,即。幅度与时间。它让我们了解剪辑在任何时间点的响度或安静程度,但它给我们提供的关于存在哪些频率的信息很少。
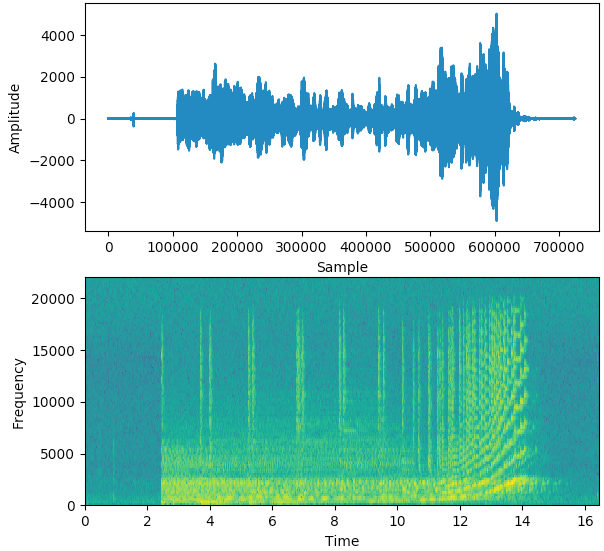
第二张图片是频谱图,显示频域中的信号。
生成频谱图
使用傅里叶变换生成频谱图,将任何信号分解为其组成频率. 我们实际上不需要回忆所有的数学,有非常方便的 Python 库函数可以一步为我们生成频谱图。
音频深度学习模型
现在我们了解了频谱图是什么,我们意识到它是音频信号的等效紧凑表示,有点像信号的“指纹”。这是一种将音频数据的基本特征捕获为图像的优雅方式。
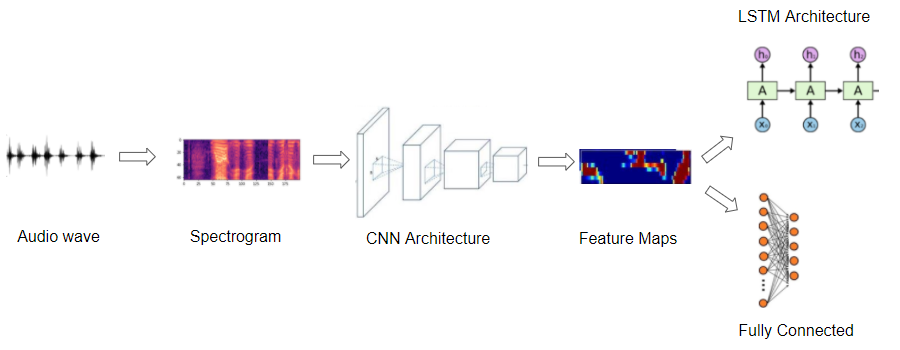
所以大多数深度学习音频应用程序都使用频谱图来表示音频。他们通常遵循这样的程序:
- 从波形文件形式的原始音频数据开始。
- 将音频数据转换为其相应的频谱图。
- 或者,使用简单的音频处理技术来增强频谱图数据。(也可以在频谱图转换之前对原始音频数据进行一些增强或清理)
- 现在我们有了图像数据,我们可以使用标准的 CNN 架构来处理它们并提取特征图,这些特征图是频谱图图像的编码表示。
下一步是根据您要解决的问题,从此编码表示生成输出预测。
- 例如,对于音频分类问题,您可以将其传递给通常由一些完全连接的线性层组成的分类器。
- 对于 Speech-to-Text 问题,您可以将其通过一些 RNN 层以从该编码表示中提取文本句子。
当然,我们跳过了很多细节,做了一些广泛的概括,但在本文中,我们停留在一个相当高的水平。在接下来的文章中,我们将详细介绍所有这些步骤和所使用的架构。
音频深度学习解决了哪些问题?
音频分类
这是最常见的用例之一,涉及获取声音并将其分配给多个类之一。例如,任务可能是识别声音的类型或来源。例如。这是汽车启动,这是锤子,哨子还是狗吠
显然,可能的应用是广泛的。这可以用于根据机器或设备产生的声音检测机器或设备的故障,或者在监视系统中检测安全入侵。
音频分离和分割
音频分离涉及从混合信号中分离出感兴趣的信号,以便随后将其用于进一步处理。例如,您可能希望将个人的声音从大量背景噪音中分离出来,或者将小提琴的声音从音乐表演的其余部分中分离出来。
音频分割用于突出音频流中的相关部分。例如,它可以用于诊断目的,以检测人类心脏的不同声音并检测异常情况。
音乐流派分类和标记
随着音乐流媒体服务的普及,我们大多数人都熟悉的另一个常见应用是根据音频对音乐进行识别和分类。分析音乐的内容以确定其所属的流派。这是一个多标签分类问题,因为给定的一段音乐可能属于多个流派。例如。摇滚、流行、爵士、萨尔萨、器乐以及其他方面,如“老歌”、“女歌手”、“快乐”、“派对音乐”等。
当然,除了音频本身,还有关于音乐的元数据,如歌手、发行日期、作曲家、歌词等,这些元数据将用于为音乐添加一组丰富的标签。
这可用于根据音乐集的音频特征编制索引,根据用户的偏好提供音乐推荐,或用于搜索和检索与您正在收听的歌曲相似的歌曲。
音乐生成和音乐转录
这些天来,我们看到了很多关于深度学习被用于以编程方式生成看起来非常真实的面部和其他场景图片,以及能够编写语法正确和智能的信件或新闻文章的新闻。
同样,我们现在能够生成与特定流派、乐器甚至特定作曲家风格相匹配的合成音乐。
在某种程度上,Music Transcription 反向应用了此功能。它需要一些声学并对其进行注释,以创建包含音乐中存在的音符的乐谱。
语音识别
从技术上讲,这也是一个分类问题,但涉及识别语音。它可以用来识别说话者的性别或他们的名字。我们可以检测人类的情绪并从他们的语气中识别出他们的情绪,我们可以将其应用于动物的声音,以识别发出声音的动物的类型,或者潜在地识别它是温柔深情的咕噜声、威胁性的吠叫声还是惊恐的叫声。
语音转文字和文字转语音
在处理人类语音时,我们可以更进一步,不仅要识别说话者,还要理解他们在说什么。这涉及从音频中提取单词,使用说话的语言并将其转录成文本句子。
这是最具挑战性的应用程序之一,因为它不仅处理音频分析,还处理 NLP,并且需要开发一些基本的语言能力来从发出的声音中破译不同的单词。相反,使用语音合成,人们可以朝另一个方向前进,获取书面文本并从中生成语音,例如,为会话代理使用人工语音。
最广为人知的例子是 Alexa、Siri、Cortana 和 Google Home 等虚拟助手,它们都是围绕此功能构建的消费者友好型产品。
结论
声音由转换为模电信号,经过采样定理处理变为数字信号,经过傅立叶变换成频谱图。此后便使用深度学习CNN框架处理,便和图像处理类似。
参考内容: