介绍
2017年当Transformer模型首次亮相时,是机器学习历史性的一年。它在许多基准测试中表现出色,并且适合解决数据科学中的许多问题。由于其高效的架构,后来开发了许多其他基于 Transformer 的模型,这些模型更专注于特定任务。
BERT 就是此类模型之一。它主要以能够构建可以非常准确地表示文本信息并存储长文本序列的语义的嵌入而闻名。结果,BERT 嵌入在机器学习中得到了广泛的应用。了解 BERT 如何构建文本表示至关重要,因为它为处理 NLP 中的大量任务打开了大门。
在本文中,我们将参考原始 BERT 论文,了解 BERT 架构并了解其背后的核心机制。在第一部分中,我们将对 BERT 进行高级概述。之后,我们将逐步深入了解其内部工作流程以及信息如何在整个模型中传递。最后,我们将了解如何微调 BERT 以解决 NLP 中的特定问题。
高级概述
Transformer的架构由两个主要部分组成:编码器和解码器。堆叠编码器的目标是为输入构建有意义的嵌入,以保留其主要上下文。最后一个编码器的输出被传递到所有尝试生成新信息的解码器的输入。
BERT是 Transformer 的继承者,继承了其堆叠式双向编码器。BERT 中的大部分架构原理与原始 Transformer 中的相同。
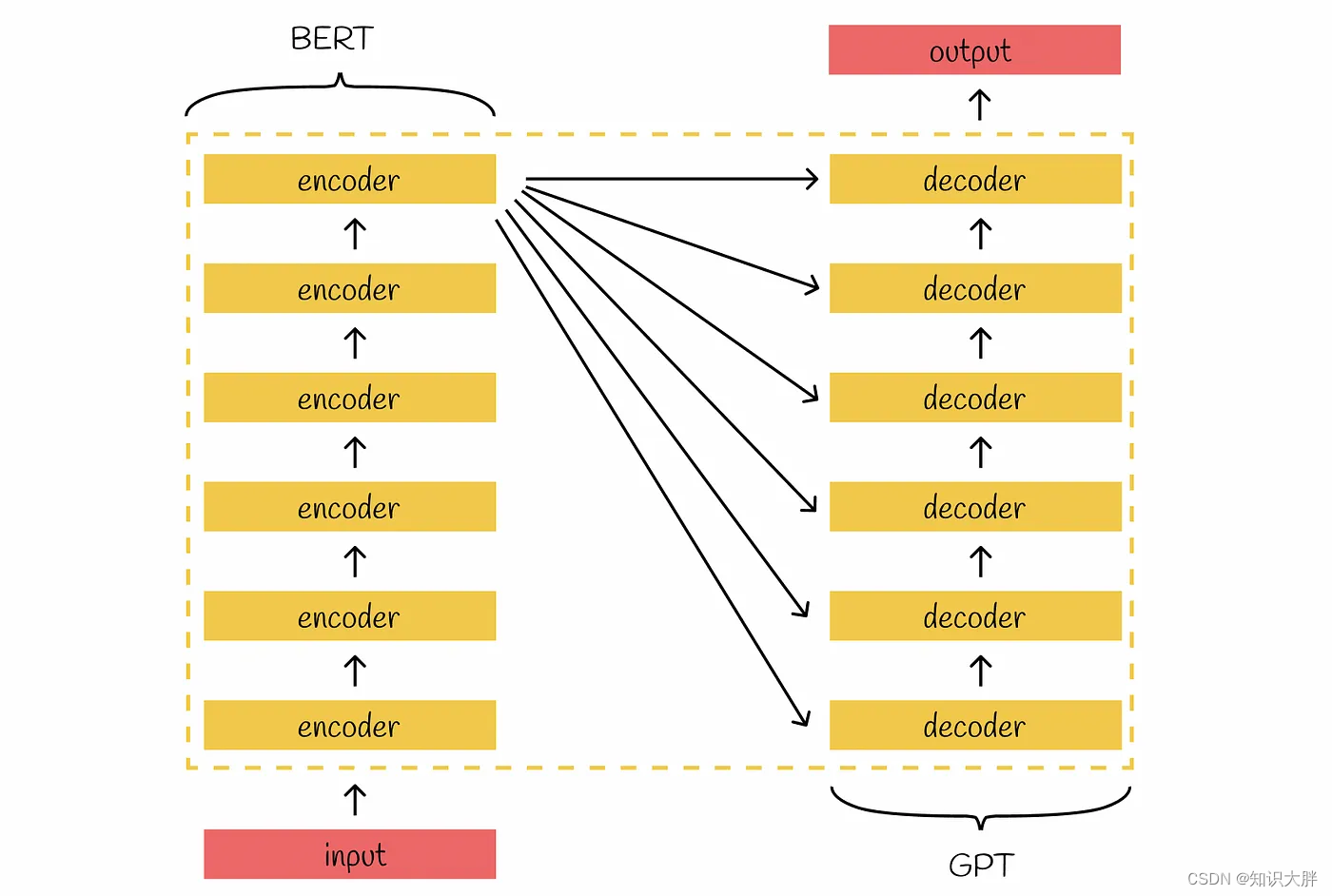
BERT 版本
BERT 存在两个主要版本:Base 和 Large。除了使用不同数量的参数之外,它们的架构完全相同。总体而言,与 BERT Base 相比,BERT Large 需要调整的