2018-BAM: Bottleneck Attention Module(BAM)
基本信息
作者: Jongchan Park*†1,Sanghyun Woo*2,Joon-Young Lee3,In So Kweon2,
期刊: BMVC
引用: *
摘要: 深度神经网络的最新进展是通过架构搜索来获得更强的代表能力。在这项工作中,我们重点研究注意力在一般深度神经网络中的作用。我们提出了一种简单有效的注意力模块,称为瓶颈注意力模块(BAM),可以与任何前馈卷积神经网络集成。我们的模块沿着两条独立的路径,通道和空间,推断出一张注意力图。我们将我们的模块放置在模型的每个瓶颈处,在那里会发生特征图的下采样。我们的模块用许多参数在瓶颈处构建了分层注意力,并且它可以以端到端的方式与任何前馈模型联合训练。我们通过在CIFAR-100、ImageNet-1K、VOC 2007和MS COCO基准上进行大量实验来验证我们的BAM。我们的实验表明,各种模型在分类和检测性能上都有持续的改进,证明了BAM的广泛适用性。代码和模型将公开提供
1.简介
- 提高性能的一个基本方法是设计一个良好的主干架构,如AlexNet、VGGNet、GoogLeNet、ResNet、DenseNet,这些主干体系结构都有自己的设计选择,并且比以前的体系结构表现出显著的性能提升。
- 另一个可提升的点在于注意力机制,方便地与现有的CNN架构集成。
本文提出了“瓶颈注意力模块”(BAM),这是一种简单高效的注意力模块,可以在任何细胞神经网络中使用。给定一个三维特征图,BAM生成一个三维注意力图来强调重要元素。在BAM中,我们将推断3D注意力图的过程分解为两个流,从而显著减少了计算和参数开销。由于特征图的通道可以被视为特征检测器,因此两个分支(空间和通道)明确地学习要关注的“什么”和“哪里”。
本文的贡献:
- 提出了一个简单有效的注意力模块BAM,它可以与任何细胞神经网络集成
- 通过广泛的消融研究验证了BAM的设计。
- 在多个基准(CIFAR-100、ImageNet-1K、VOC 2007和MS COCO)上用各种基线架构进行的广泛实验中验证了BAM的有效性
2.相关工作
- 跨模态注意:注意力图被用作以条件方式解决任务的有效方法,但它们是在单独的阶段进行训练的,用于特定任务的目的。
- 自注意力:残差注意力网络(计算/参数开销大)、SE-Net(错过了空间域)
- 自适应模块:根据输入动态地改变输出,如动态滤波器网络、空间Tranformer网络、可变形卷积网络,BAM也是一个自适应模块,通过注意力机制动态抑制或强调特征图
3.BAM模型

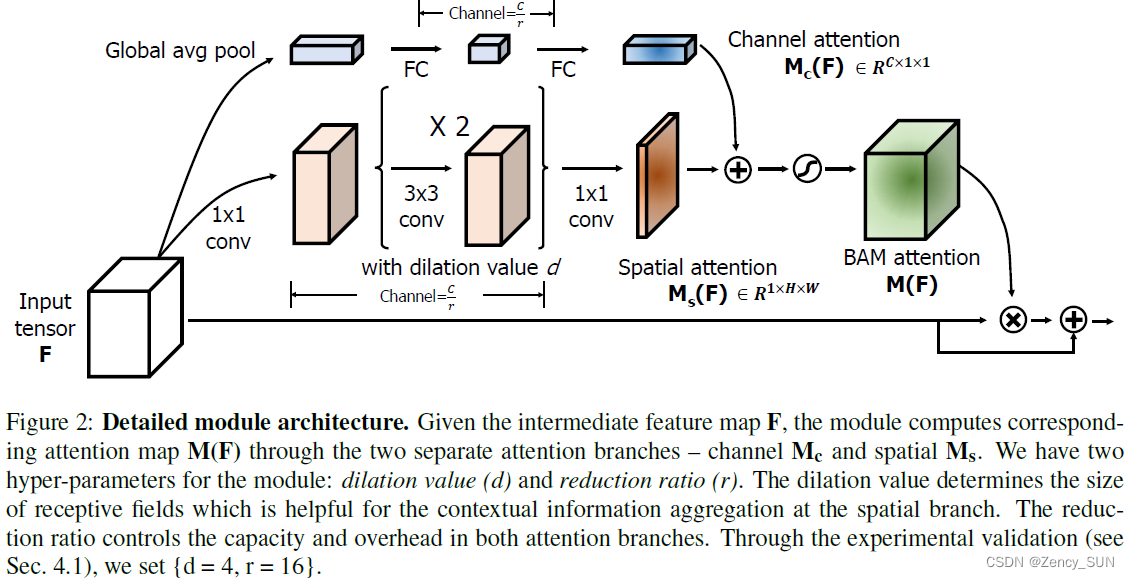
- CA支线:Avgpool——Flatten——Line——BN——Relu——Line
- SA支线:Conv+BN+Relu——dilationConv+BN+Relu——dilationConv+BN+Relu——Conv
- MC与MF的结合方式:将两者扩展到CxHxW,在各种组合方法中,如元素相加、乘法或最大操作,我们选择元素相加来实现有效的梯度流动。在求和之后,采用一个sigmoid函数来获得最终的三维注意力图谱M(F),其范围在0到1之间。这个三维注意力图谱与输入特征图谱F进行元素相乘,然后在原始输入特征图谱上添加,以获得精炼的特征图谱F’。
4.实验
4.1.在CIFAR-100上的消融实验
- 扩张值d和缩减率r:d=4,r=16最佳
- 分开或合并的分支机构:验证空间分支和通道分支的有效性,
- 以及MC与MF的结合方式:SUM效果最好
- 与放置原始 convblocks 的比较:参数减少,效果增加,意味着BAM的改进不仅仅是由于深度的增加,而是由于有效的特征细化
- 瓶颈: 放置BAM的有效点
4.2.在CIFAR-100上的分类结果
BAM可以用较少的网络参数有效地提高网络的效果。由于我们的轻量级设计,整体的参数和计算开销是微不足道的。
4.3 在ImageNet-1K上的分类结果
BAM可以在大规模数据集中的各种模型上有很好的泛化能力,同时参数和计算的开销可以忽略不计,这表明提出的模块BAM可以有效地提高网络容量。另一个值得注意的是,改进的性能来自于只在网络中放置三个模块。
4.4.BAM在紧凑型(轻量化)网络中的有效性
紧凑型网络是为移动和嵌入式系统设计的,所以设计方案有计算和参数限制。BAM提高了所有模型的准确性,而且开销很小。
4.5.MS COCO对象检测
我们观察到比基线有明显的改进,证明了BAM在其他识别任务中的泛化性能。
4.6.VOC 2007物体检测
BAM提高了所有具有两个骨干网络的强大基线的准确性。请注意,BAM的准确率提高是以可忽略不计的参数开销实现的,这表明提高不是由于天真的容量增加,而是由于我们有效的特征细化。
4.7.与SE-Net的比较
BAM在大多数情况下以较少的参数胜过了SE。我们的模块需要的GFLOPS略多,但参数比SE少得多,因为我们只把我们的模块放在瓶颈处。
5.结论
我们提出了瓶颈注意模块(BAM),这是一种增强网络表示能力的新方法。我们的模块通过两个独立的途径有效地学习什么和在哪里集中或压制,并有效地完善中间特征。受人类视觉系统的启发,我们建议将注意力模块放在网络的瓶颈处,这是信息流的最关键点。为了验证其功效,我们用各种最先进的模型进行了广泛的实验,并证实BAM在三个不同的基准数据集上的表现优于所有的基线: CIFAR-100、ImageNet1K、VOC2007和MS COCO。此外,我们将该模块如何作用于中间的特征图进行了可视化,以获得更清晰的理解。有趣的是,我们观察到层次化的推理过程,这与人类的感知过程相似。我们相信我们在瓶颈处的自适应特征细化的发现对其他视觉任务也是有帮助的。
代码实现
https://github.com/xmu-xiaoma666/External-Attention-pytorch
https://github.com/Jongchan/attention-module
个人总结
BAM是CBAM的姊妹篇,是一个比SE-Net更强大,且轻量化的注意力网络,也融合了CA和SA,可广泛用于多种CNN网络中,同时建议将其应用到网络的“瓶颈处”