记一次神奇的SQL查询经历,group by、order by慢查询优化
一、问题背景
现网出现慢查询,在500万数量级的情况下,单表查询速度在30多秒,需要对sql进行优化,sql如下:
mysql> select age,count(*) from `user` u where name ='harry5102' and sex=1 group by age order by age;
+-----+----------+
| age | count(*) |
+-----+----------+
| 11 | 2 |
| 12 | 1 |
...
| 104 | 2 |
| 105 | 4 |
| 109 | 4 |
+-----+----------+
85 rows in set (7.46 sec)
我在测试环境构造了500万条数据,模拟了这个慢查询。
简单来说,就是查询一下姓名,性别相同的用户的各个年龄的人数。很简单的sql,可以看到,查询耗时为7.46秒。查询时间太长了,如果不优化,势必会验证影响用户的体验,这还是小问题,如果并发稍微高一些,数据库连接将会被占满,导致无法对外提供服务,内存暴涨等一些列问题,优化迫在眉睫!
说一下user表,用存储过程生成500万个数据
测试表结构
表DDL语句是
CREATE TABLE `user` (
`id` bigint NOT NULL AUTO_INCREMENT,
`name` varchar(50) NOT NULL DEFAULT '',
`sex` tinyint NOT NULL,
`address` varchar(255) NOT NULL,
`currentDate` datetime NOT NULL DEFAULT CURRENT_TIMESTAMP,
`state` tinyint NOT NULL COMMENT '激活状态',
`mvno_id` varchar(50) NOT NULL,
`org_id` varchar(50) NOT NULL DEFAULT '',
`phone` varchar(11) DEFAULT NULL,
`age` int NOT NULL DEFAULT '0',
PRIMARY KEY (`id`),
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_0900_ai_ci
存储过程
DELIMITER // \
CREATE PROCEDURE insertusers () \
BEGIN \
DECLARE num INT; \
DECLARE username VARCHAR(50); \
SET num = 1; \
WHILE (num < 5000000) DO \
if num%1000=1 then
start transaction; \
end if; \
set username=CONCAT('harry',num%10000); \
INSERT INTO user ( \
`name`, \
sex, \
address, \
state, \
mvno_id, \
org_id, \
phone, \
age
) \
VALUES \
(username, num%3, CONCAT(uuid(),num), num%3, uuid(),uuid(),CONCAT('159',num%10000011),(10+round(rand() * 100, 0))); \
if num%1000=0 then \
commit; \
end if; \
SET num = num + 1; \
END \
WHILE; \
END// \
DELIMITER ; \
感兴趣的朋友可以直接拿去执行来测试
执行存储过程:
call insertusers();
看执行计划
mysql> explain select age,count(*) from `user` u where name ='harry5102' and sex=1 group by age order by age;
+----+-------------+-------+------------+------+---------------+------+---------+------+---------+----------+----------------------------------------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+-------+------------+------+---------------+------+---------+------+---------+----------+----------------------------------------------+
| 1 | SIMPLE | u | NULL | ALL | NULL | NULL | NULL | NULL | 4950132 | 1.00 | Using where; Using temporary; Using filesort |
+----+-------------+-------+------------+------+---------------+------+---------+------+---------+----------+----------------------------------------------+
1 row in set, 1 warning (0.00 sec)
可以看到,还没加任何索引,试试加下索引看看
加索引
分析sql语句:select age,count(*) from user u where name =‘harry5102’ and sex=1 group by age order by age;
发现where后面使用了几个字段,name,sex,age 三个字段
那么,怎么创建索引呢?创建多少个索引呢?
这得要理解mysql的索引机制了
mysql的索引机制
什么是索引?
索引是帮助mysql高效查询而排好序的数据结构。
mysql底层默认是采用了B+tree的数据结构作为索引的,什么是B+tree?
B+tree是一棵平衡树,普通的树基本每个节点以存储key-value的形式存储数据的,即数据分布在树的各个节点中。而B+tree有点特殊,数据并没有都存储在各个节点中,而是只有叶子节点存储了具体的数据,而非叶子节点则存储了索引和指向下个叶子深度节点的指针,这样一来,非叶子节点因为没有存储具体数据,所以可以存储更多的索引和指向下个深度节点的指针,能保证一棵B+tree存储更多的数据,这个更多数据指的是千万级别
索引分类:
聚簇索引,二级索引,非聚簇索引,hash索引等
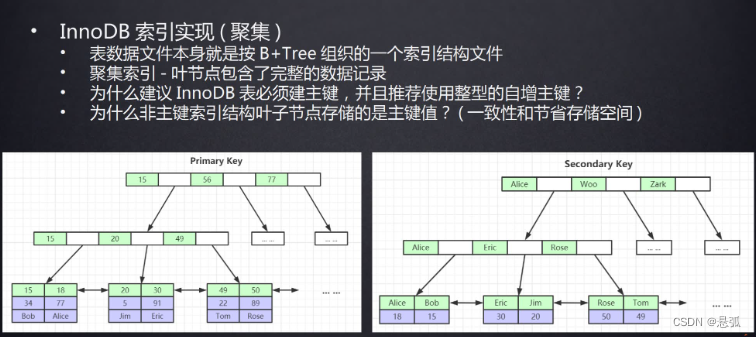
- 什么是聚簇索引?
mysql的默认存储引擎是innodb,我们创建了innodb后,可以进入到mysql的数据目录下,可以发现,每个聚簇索引的表,都包含两个文件,其中一个表的定义文件,一个是.ibd的文件,这个文件实际上存储的数据就是一个表的索引和数据了,而聚簇索引的意思就是索引和数据放在同一个文件的,就叫做聚簇索引,比如innodb存储引擎的主键索引,就是聚簇索引,也是一棵B+tree结构
-
什么是二级索引?
二级索引也是B+tree结构,只是和聚簇索引不一样的是,二级索引的B+tree上的叶子节点并不存储具体数据,而是存储的主键值
- 什么是非聚簇索引?
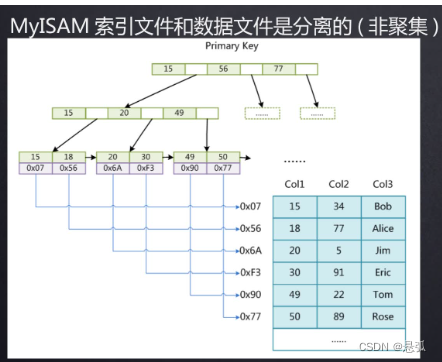
myisam存储引擎创建的表,我们去到数据目录下,会发现有三个文件,其中一个是表的定义文件,一个是数据文件,还有一个是索引文件。这种数据和索引分开存储的索引,我们叫做非聚簇索引
- hash索引,就是将索引的key进行hash,存放到数组和链表中,hash索引不能进行范围查询,只能进行等号查询和in查询
而每种索引下又还可以继续分类,分为主键索引,唯一索引,普通索引,全文索引
除了上述提到的索引之外,还有组合索引,或者叫联合索引,就是使用多个字段组合起来作为一个索引,组合索引的B+tree长什么样?
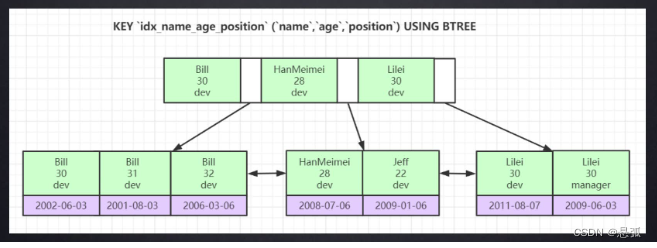
怎么理解组合索引?为什么组合索引遵循最左前缀原则?
从上图中可以看出,组合索引也是排好序的数据结构,比如上图中的组合索引是(name,age,position)
仔细留意你会发现,这个组合索引实际上是按name字段先排好序,接着再按age字段排序,最后在按position字段排序。这也就是为什么要遵循最左前缀原则了。如果跳过了name字段去查询age和position,那后面的字段将是无序的
因为大部分的sql查询语句都是多个条件的,因此我们一般说的sql优化,大多数就是针对二级索引中普通索引,唯一索引类型的优化,优化的目标就是希望查询的sql能使用到索引,从而提升查询的效率
sql优化实战
通过上文的索引原理的介绍,我们知道了索引实际上就是一个排好序的B+tree数据结构,遵循最左前缀原则,好了,我们回到我们的sql语句
select age,count(*) from user u where name =‘harry5102’ and sex=1 group by age order by age;
我们按以下两个方案去优化,看看优化效果怎么样
- 给查询条件的和order by中的每个字段分别建索引
- 建立组合索引
给查询条件的和order by中的每个字段分别建索引
先看第一种情况,分别给每个查询条件中的字段和order by建索引,即分别给name、sex、age 这三个字段单独建索引
alter table `user` add index idx_name(name);
alter table `user` add index idx_sex(sex);
alter table `user` add index idx_age(age);
因为索引和数据是存储在同一个文件上的,500万的数据如果新增索引,那就需要维护500万的数据,因此当我们建索引时会发现执行蛮长时间才能创建好一个索引
建好这三个索引之后,我们就来看看查询效果如何
mysql> select age,count(*) from `user` u where name ='harry5102' and sex=1 group by age order by age;
+-----+----------+
| age | count(*) |
+-----+----------+
| 11 | 2 |
| 12 | 1 |
...
| 105 | 4 |
| 109 | 4 |
+-----+----------+
85 rows in set (3.71 sec)
效果还是很不错的,性能提升了50%左右了,但还是要很长的执行时间,按这个查询效率,还是一个非常不理想的
我们来看执行计划,看看用到了哪些索引
mysql> explain select age,count(*) from `user` u where name ='harry5102' and sex=1 group by age order by age;
+----+-------------+-------+------------+------+--------------------------+----------+---------+-------+------+----------+----------------------------------------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+-------+------------+------+--------------------------+----------+---------+-------+------+----------+----------------------------------------------+
| 1 | SIMPLE | u | NULL | ref | idx_name,idx_sex,idx_age | idx_name | 202 | const | 500 | 50.00 | Using where; Using temporary; Using filesort |
+----+-------------+-------+------------+------+--------------------------+----------+---------+-------+------+----------+----------------------------------------------+
1 row in set, 1 warning (0.00 sec)
通过执行计划可以看到,这里可能使用到的索引有三个,分别是idx_name,idx_sex,idx_age。但是实际上只用到了idx_name,而且出现了Using temporary; Using filesort,说明mysql在查询过程中用到了临时表和文件排序。这里为什么只用到了idx_name字段作为索引而已呢?我明明将查询条件中的三个字段都分别定义了索引了啊,为什么其他字段不用?
其实是这样的,mysql在执行sql语句之前,会有一个对sql语句优化的过程,这个优化过程中,会去计算这条sql语句的执行成本,即全表扫描,还有使用索引的成本,然后选择成本最低的来执行,也就是idx_name索引的执行成本最低。关于怎么查看执行成本不是本次的主题,不做过多介绍!
建立组合索引
将上文中建的三个索引删除,重新建组合索引
删除上文建的三个独立索引
drop index idx_age on `user`;
drop index idx_sex on `user`;
drop index idx_name on `user`;
新建组合索引,一般我们按区分度最高的排在前面来建,区分度可以用对应字段去重后处以总的记录数得到,值越大,说明区分度越高
在这里我们建的组合索引的顺序是idx_name_sex_age(name,sex,age)
alter table `user` add index idx_name_sex_age(name,sex,age);
建好之后,我们执行一下看看效果
mysql> select age,count(*) from `user` u where name ='harry5102' and sex=1 group by age order by age;
+-----+----------+
| age | count(*) |
+-----+----------+
| 11 | 2 |
| 12 | 1 |
...
| 105 | 4 |
| 109 | 4 |
+-----+----------+
85 rows in set (0.00 sec)
效果非常好,简直无敌了,几乎不耗时,或者说耗时可以忽略的,很明显,效果超级无敌好了
我们看一下执行计划
mysql> explain select age,count(*) from `user` u where name ='harry5102' and sex=1 group by age order by age;
+----+-------------+-------+------------+------+------------------+------------------+---------+-------------+------+----------+-------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+-------+------------+------+------------------+------------------+---------+-------------+------+----------+-------------+
| 1 | SIMPLE | u | NULL | ref | idx_name_sex_age | idx_name_sex_age | 203 | const,const | 166 | 100.00 | Using index |
+----+-------------+-------+------------+------+------------------+------------------+---------+-------------+------+----------+-------------+
1 row in set, 1 warning (0.00 sec)
可见,sql在执行时使用到了联合索引idx_name_sex_age,而且也用到了覆盖索引Using index。效果能不好吗?
现在有人可能会提问,要是不按性别作为查询条件,效果会怎么样?
mysql> select age,count(*) from `user` u where name ='harry5102' group by age order by age;
+-----+----------+
| age | count(*) |
+-----+----------+
| 11 | 2 |
| 12 | 1 |
...
| 105 | 4 |
| 109 | 4 |
+-----+----------+
85 rows in set (0.00 sec)
也是很快,看执行计划
mysql> explain select age,count(*) from `user` u where name ='harry5102' group by age order by age;
+----+-------------+-------+------------+------+------------------+------------------+---------+-------+------+----------+----------------------------------------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+-------+------------+------+------------------+------------------+---------+-------+------+----------+----------------------------------------------+
| 1 | SIMPLE | u | NULL | ref | idx_name_sex_age | idx_name_sex_age | 202 | const | 500 | 100.00 | Using index; Using temporary; Using filesort |
+----+-------------+-------+------------+------+------------------+------------------+---------+-------+------+----------+----------------------------------------------+
1 row in set, 1 warning (0.00 sec)
此时发现出现了Using temporary; Using filesort,虽然当前查询蛮快的,却不是很好的,可能是因为根据name过滤后没有多少数据了,所以还很快,但是其他场景未必就好了