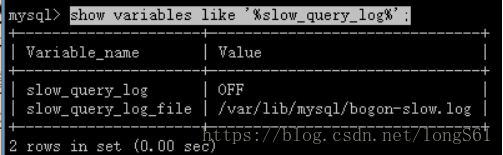
先查询是否开启:
show variables like '%slow_query_log%';
开启慢查询日志:
set global slow_query_log=1;
查看参数设置:
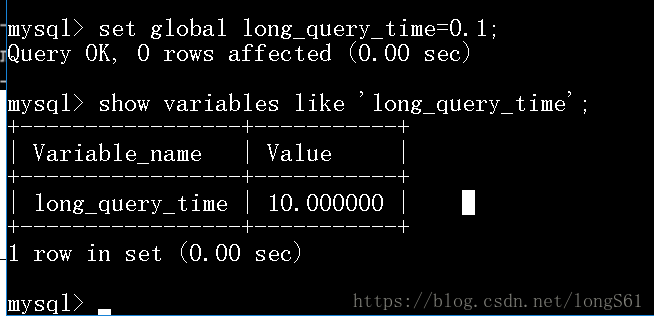
show variables like 'long_query_time'; //这里查询的是查过多少时间才会记录成慢查询
默认10秒以上的sql语句记录到日志中
修改参数:
set global long_query_time=0.1; 满足0.1秒查询时间的sql语句就记录
修改之后不能直接看到修改后的值,如下图
所以,我们需要新打开一个窗口去查看
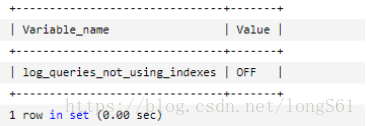
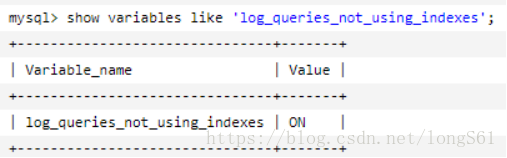
开启系统变量log-queries-not-using-indexes:未使用索引的查询也被记录到慢查询日志中(可选项)。如果调优的话,建议开启这个选项。
show variables like 'log_queries_not_using_indexes';
set global log_queries_not_using_indexes=1;
当我们把所有的都开启之后,它就会把所有超过我们刚刚设定的阈值的sql语句记录在我们设定的慢查询里
接下来,我们将针对当前的sql语句进行分析
分析语句慢的原因:
我们开启了慢查询去记录一些执行时间比较久的SQL语句,找出这些SQL语句并不意味着完事了,
再通过explain 或者profiles来分析语句
0:查看profile是否开启
show variables like "profiling";
set profiling=on;

然后再通过
1)Show profiles;
这个命令是显示当前所有连接的工作状态.
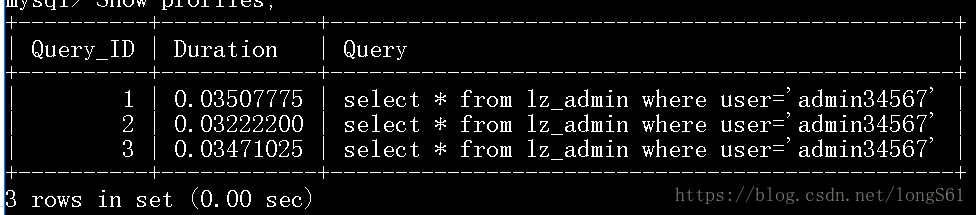
2)查看单条语句执行过程
show profile for query 5;
这里的5指的就是 Query_ID,意思是你想分析哪条sql语句
什么情况下产生临时表?
1: group by 的列和order by 的列不同时, 2表边查时,取A表的内容,group/order by另外表的列
2: distinct 和 order by 一起使用时
3: 开启了 SQL_SMALL_RESULT 选项
什么情况下临时表写到磁盘上?
答:
1:取出的列含有text/blob类型时 ---内存表储存不了text/blob类型
2:在group by 或distinct的列中存在>512字节的string列
3:select 中含有>512字节的string列,同时又使用了union或union all语句
少用子查询 少使用group by
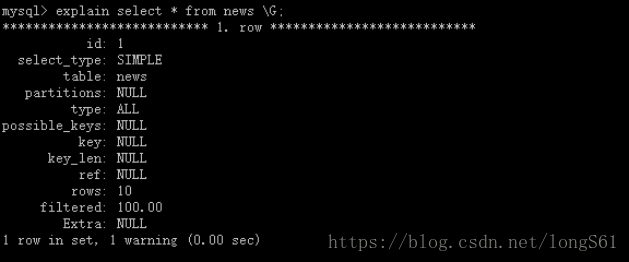
在日常工作中,有些时我们常常用到explain这个命令来查看一个这些SQL语句的执行计划,查看该SQL语句有没有使用上了索引,有没有做全表扫描,这都可以通过explain命令来查看。
explain显示了mysql如何使用索引来处理select语句以及连接表。可以帮助选择更好的索引和写出更优化的查询语句。
explain的列分析
id: 代表select 语句的编号, 如果是连接查询,表之间是平等关系, select 编号都是1,从1开始. 如果某select中有子查询,则编号递增.
explain select count(user) from lz_admin where user='zll';

type列: 是指查询的方式, 非常重要,是分析”查数据过程”的重要依据( 从上往下性能越来越好)
可能的值
all: 意味着从表的第1行,往后,逐行做全表扫描.,运气不好扫描到最后一行.
index: 比all性能稍好一点,
通俗的说: all 扫描所有的数据行,相当于data_all index 扫描所有的索引节点,相当于index_all
range: 意思是查询时,能根据索引做范围的扫描
ref 意思是指 通过索引列,可以直接引用到某些数据行
eq_ref 是指,通过索引列,直接引用某1行数据, 常见于连接查询中
const, system, null 这3个分别指查询优化到常量级别, 甚至不需要查找时间.
一般按照主键来查询时,易出现const,system
或者直接查询某个表达式,不经过表时, 出现NULL
max,min在表中优化过,不需要\真正查找,为NULL 所以type为null
ref列 指连接查询时, 表之间的字段引用关系. 显示使用哪个列或常数与key一起从表中选择行。
rows : 是指估计要扫描多少行.
extra:
using index: 是指用到了索引覆盖,效率非常高
using where 是指光靠索引定位不了,还得where判断一下
using temporary 是指用上了临时表, group by 与order by 不同列时,或group by ,order by 别的表的列.
using filesort : 文件排序(文件可能在磁盘,也可能在内存),
Select tables optimized away 这个值意味着仅通过使用索引,优化器可能仅从聚合函数结果中返回一行
select sum(shop_price) from goods group by cat_id( 这句话,用到了临时表和文件排序)
type列: 是指查询的方式, 非常重要,是分析”查数据过程”的重要依据
可能的值
all: 意味着从表的第1行,往后,逐行做全表扫描.,运气不好扫描到最后一行.
扩展
http://blog.csdn.net/kk185800961/article/details/49179619
https://www.cnblogs.com/xiaoboluo768/p/5400990.html
https://www.cnblogs.com/lpfuture/p/5756543.html