系列文章:
2022李宏毅作业hw1—新冠阳性人员数量预测。_亮子李的博客-CSDN博客_李宏毅hw1
hw-2 李宏毅2022年作业2 phoneme识别 单strong-hmm详细解释。_亮子李的博客-CSDN博客_李宏毅hw2
2021李宏毅作业hw3 --食物分类。对比出来的80准确率。_亮子李的博客-CSDN博客_李宏毅hw3
地址:
git地址:
https://github.com/xiaolilaoli/lihongyi2022homework/tree/main/hw4_speaker
数据和比赛地址:
ML2022Spring-hw4 | Kaggle
前言:
作业4主要难点应该在于视频里模块的应用。因为都是一些陌生的模块,所以写起来会没那么容易。做了作业才发现transformer的模块的真的有很多很多。
但是我觉得还有更难的地方,就在于hw4的验证集和测试集分布有一些差别。这样导致我一时间非常蒙蔽然后不知道怎么办了。 试问你一直以来坚持的目标,你达到之后才知道那是个错误切虚幻的,你的心会作何感想? 我现在就是这种感觉。


最后的成绩是这个 没有达到strong,比较难受。因为我电脑跑这个作业实在是太慢了 不像以前的作业,可以让我慢慢迭代。尝试很多的结构和参数,这个作业如果大一点 一个epo要接近11分钟。。。然后每次要两百个epo。。。到这里不禁感叹 资源才是王道啊 。。。
一个BUG:
一开始的时候, 我的验证集准确率高达百分之89。我心里高高兴兴,快快乐乐的,去kaggle提交了答案。然后,下面就是我不信邪的结果。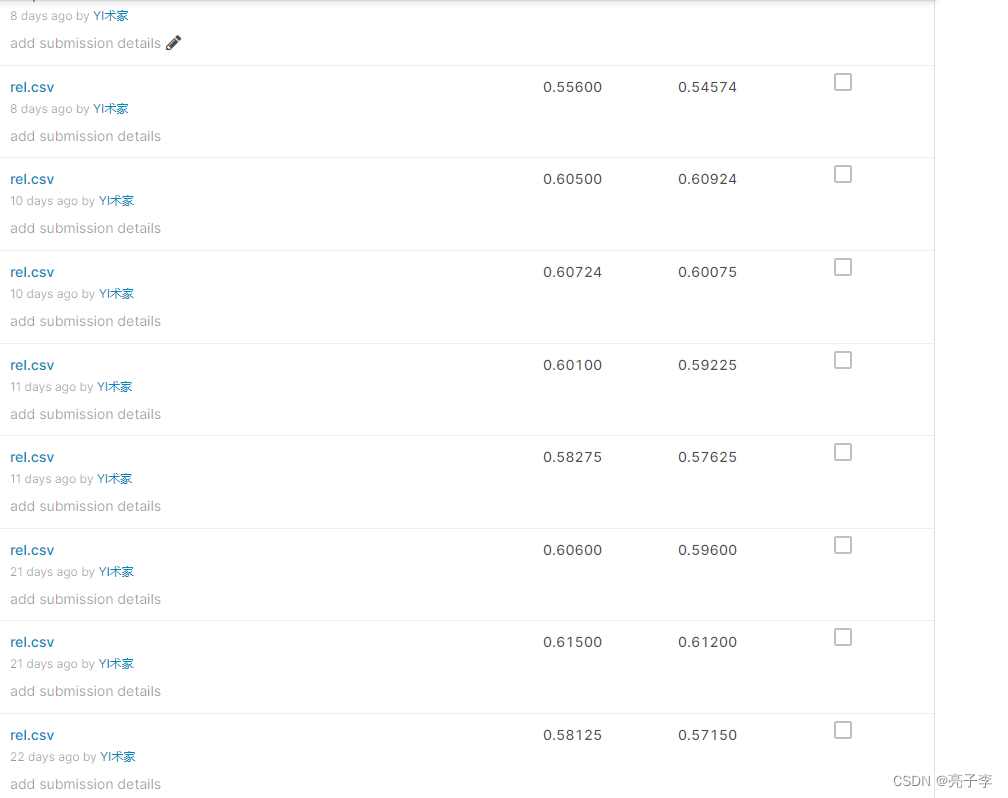
是的,即使我不信邪的提交了无数次,但发现自己仍然是 毫无变化而且准确率极低。我审查了每一步代码试图找到出错的原因。还是没找到,最后不得不求助朋友,让他把他的代码发给我看。经过一步一步审查,终于发现了错误的地方在哪。 错误的原因就在于我自作主张的把测试集的长度模仿训练集和验证集做了裁剪。 在训练的时候,对于长度超过seg_len(我当时是128)的样本,都会进行裁剪, 验证的时候同样。但是在官方代码里,并没有对测试集数据进行裁剪,所以就导致测试集的batch只能为1(因为样本长度不同). 我一看,这怎么可以,果断三下五除二把测试集也裁剪了。最后就导致测试集上的效果极差。 当我把测试集原样送进模型,果然正确率得到了很大的提升。 但是还是比验证集低上很多。 其实这就已经说明训练集和测试集的分布是差了很多很多的。
为什么我验证集上裁剪, 正确率依然可以达到90.而在提交的测试集上裁剪,准确率只有60呢?理论上来说,网络应该关注的是发言人的声色。那么发言人说话的长度应该对结果没有什么影响才对。但是实验强烈的反驳了这一点。长度,就是有关系,而且关系挺大的。这个现象的深层原因我也不知道为什么,如果有大佬知道,评论一下呗。
正文:
1 数据部分

数据部分 ,可以看下 官方的视频 和 官方的代码。这次的任务,是根据一段音频来预测这段话是谁说的。给的训练数据像上图右下角那个图。 一个说话人有很多段音频,给出了音频的地址和长度。我们取一部分作为训练集,剩下的作为验证。
下面是一个读文件的函数。
def readTrainMel(dataDir):
map_path = Path(dataDir) / 'mapping.json'
mapping = json.load(map_path.open())
print(mapping)
speaker2id, id2speaker = mapping.values()
x = []
y = []
val_x = []
val_y = []
dataPath = Path(dataDir) / 'metadata.json'
data = json.load(dataPath.open())
speakers = data['speakers']
for speaker in speakers:
speakerList = speakers[speaker]
for each in speakerList:
x.append((each['feature_path'], each['mel_len']))
y.append(speaker2id[speaker])
return x, y
speaker2id, id2speaker 这两个是标签和发言者id的转换。 最后我们记录下发言人每条发言的地址和这条地址对应的标签(发言者)。比如如果一个发言人他有10条数据,我们就记录10个语音的地址,这10个地址都对应着标签X。
下面是dataset。
class speakerData(Dataset):
def __init__(self, dataDir, mode='train', segment_len=256, x=None , y= None):
super(speakerData, self).__init__()
self.segment_len = segment_len
self.dataDir = dataDir
self.mode = mode
map_path = Path(dataDir) / 'mapping.json'
mapping = json.load(map_path.open())
print(mapping)
speaker2id, id2speaker = mapping.values()
if mode == 'train':
self.x = x
self.y = torch.LongTensor(y)
elif mode == 'test':
x = []
dataPath = Path(dataDir) / 'testdata.json'
data = json.load(dataPath.open())
n_mels = data['n_mels']
utterances = data['utterances']
for utterance in utterances:
x.append((utterance['feature_path'], utterance['mel_len']))
self.x = x
self.id2speaker = id2speaker
def __getitem__(self, item):
uttrPath = os.path.join(self.dataDir ,self.x[item][0])
uttrData = torch.load(uttrPath)
n_mel = self.x[item][1]
if self.mode == 'train':
if n_mel > self.segment_len:
start = random.randint(0, n_mel-self.segment_len)
end = start + self.segment_len
uttrData = uttrData[start: end]
if self.mode == 'test':
segment_len = 2000
if n_mel > segment_len:
start = random.randint(0, n_mel-self.segment_len)
end = start + self.segment_len
uttrData = uttrData[start: end]
if self.mode == 'train':
return uttrData, self.y[item]
elif self.mode == 'test':
return self.x[item][0], uttrData
def __len__(self):
return len(self.x)
dataset中都是比较平常的地方。值得注意的地方有:
x中存储的是文件名,所以要根据文件名找到那个文件,读出数据。
seg_len需要自己设置 。官方的128就挺好的。 当训练或者验证的长度超过他,就裁剪为128。当测试的时候, 可以选择不裁剪,但是不裁剪有时候会出现爆内存的情况(如果你的编码维度高的话)。因为有些人的说话长度高达三四千。 可怕。 所以我裁剪了2000的长度。
看loader
def my_clooate(batch):
mel, speaker = zip(*batch)
mel = pad_sequence(mel,batch_first=True,padding_value=-20)
return mel, torch.LongTensor(speaker)
def inference_collate_batch(batch):
"""Collate a batch of data."""
feat_paths, mels = zip(*batch)
return feat_paths, torch.stack(mels)
def getDataloader(path, batchSize, mode):
if mode == 'train' :
x , y = readTrainMel(path)
dataset = speakerData(path, mode='train', x=x, y=y)
trainlen = int(0.9 * len(dataset))
lengths = [trainlen, len(dataset) - trainlen]
train_set, val_set = random_split(dataset, lengths)
train_loader = DataLoader(train_set, batchSize, shuffle=True,collate_fn=my_clooate)
val_loader = DataLoader(val_set, batchSize, shuffle=True,collate_fn=my_clooate)
return train_loader, val_loader
elif mode == 'test':
dataset = speakerData(path, mode=mode)
test_loader = DataLoader(dataset, 1, shuffle=False,collate_fn=inference_collate_batch)
return test_loader
步骤就是 先读出来x和y 然后分割成训练和验证。(话说这个分割函数我还是第一次见 ,从官方代码学的) loader读进去。 注意collate_fn这个函数的作用是来组织bat内数据的。一般是默认的,就是把很多数据分别合起来。 在这里自己定义了,因为我们超过128的数据都被裁剪了 ,那么不足128的呢,必须补足128.因为batch内数据长度必须相同。 test时 bat为1 就不用补了 .
数据部分就是这个样字。 当你把文件读入后,会发现一个语音feature 一般是X*40 比如 600*40.40就是一个特征维度。 然后裁剪后变成128*40 变成batch 就是B*28*40. 然后输入到模型中去
2 模型准备:
官方的模型是这样的
class Classifier(nn.Module):
def __init__(self, d_model=80, n_spks=600, dropout=0.1):
super().__init__()
# Project the dimension of features from that of input into d_model.
self.prenet = nn.Linear(40, d_model)
# TODO:
# Change Transformer to Conformer.
# https://arxiv.org/abs/2005.08100
self.encoder_layer = nn.TransformerEncoderLayer(
d_model=d_model, dim_feedforward=256, nhead=2
)
# self.encoder = nn.TransformerEncoder(self.encoder_layer, num_layers=2)
# Project the the dimension of features from d_model into speaker nums.
self.pred_layer = nn.Sequential(
nn.Linear(d_model, d_model),
nn.ReLU(),
nn.Linear(d_model, n_spks),
)
def forward(self, mels):
"""
args:
mels: (batch size, length, 40)
return:
out: (batch size, n_spks)
"""
# out: (batch size, length, d_model)
out = self.prenet(mels)
# out: (length, batch size, d_model)
out = out.permute(1, 0, 2)
# The encoder layer expect features in the shape of (length, batch size, d_model).
out = self.encoder_layer(out)
# out: (batch size, length, d_model)
out = out.transpose(0, 1)
# mean pooling
stats = out.mean(dim=1)
# out: (batch, n_spks)
out = self.pred_layer(stats)
return out先是一个prenet把数据从40维度转到80维度, 然后是transformer的编码,最后是预测层。一层mlp加上一个linear。 注意在前向的时候,transformer模型需要进行一个维度的转换。从BLD(batch,长度,维度)转换到LBD.其实我有点不理解这样的转换。而且有一些transformer模块也不需要这样的转换。 之后有一个平均池化,将trans的输出在长度上平均。平均后输出预测。 其实我一直觉得平均不太好,因为你说一个很大,一个很小,这样岂不是和都差不多得到的结果一样了??
下面是我用的模型 。
class Classifier2(nn.Module):
def __init__(self, d_model=512, n_spks=600, dropout=0.1):
super().__init__()
# Project the dimension of features from that of input into d_model.
self.prenet = nn.Linear(40, d_model)
# TODO:
# Change Transformer to Conformer.
# https://arxiv.org/abs/2005.08100
self.blocks = nn.ModuleList([
ConformerBlock(
dim=d_model,
dim_head=64,
heads=8,
ff_mult=4,
conv_expansion_factor=2,
conv_kernel_size=15,
attn_dropout=dropout,
ff_dropout=dropout,
conv_dropout=dropout
)
for i in range(6)])
self.pooling = self_Attentive_pooling(d_model)
self.pred_layer = AMSoftmax(d_model, n_spks)
def forward(self, mels):
"""
args:
mels: (batch size, length, 40)
return:
out: (batch size, n_spks)
"""
# out: (batch size, length, d_model)
out = self.prenet(mels)
for blk in self.blocks:
out = blk(out)
stats = self.pooling(out)
# out: (batch, n_spks)
out = self.pred_layer(stats)
return out如果你把d_model调节的很小 ,比如80, 128,那么你会得到一个训练集准确度百分之99,验证集90的结果。 但是线上提交结果只有70多。
如果你把d_model调节的很大 ,比如512,那么你会得到一个训练集准确度百分之90,验证集85的结果。 但是线上提交结果有80多。
但是有时候也不一定 , 神经网络 真的是玄学, 我都服了 说实话,,,。
这件事情挺令人疑惑的。写到这里 我决定再跑一次。
下面是模型中的一些模块 ,都来自大神, encore 大佬 和李宏毅助教的讲述
【ML2021李宏毅机器学习】作业4 Speaker Classification 思路讲解_哔哩哔哩_bilibili
conformer block 来源于
Conformer: Convolution-augmented Transformer for Speech Recognition
他的做法就是把单纯的transformer层换成右边的层。
本身多头注意力后面就应该直接输出进feed的 ,他加了一个卷积模块在中间,这样可以让模型在关注全局特征的时候也关注一下局部的特征。
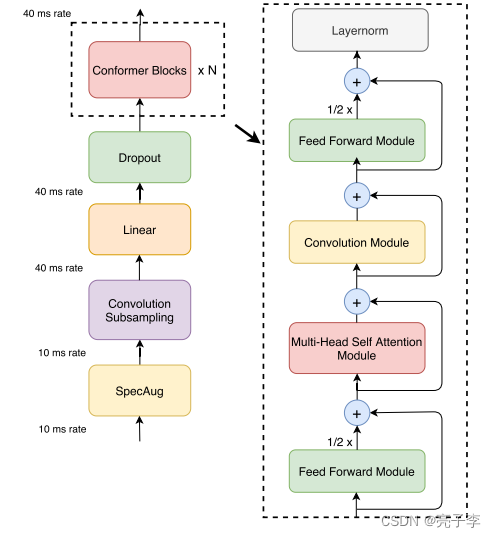

我用的时候发现一层不是很够啊 所以就垒了很多层。
self_Attentive_pooling
class self_Attentive_pooling(nn.Module):
def __init__(self, dim):
super(self_Attentive_pooling, self).__init__()
self.sap_linaer = nn.Linear(dim, dim)
self.attention = nn.Parameter(torch.FloatTensor(dim,1))
torch.nn.init.normal_(self.attention, std=.02)
print(1)
def forward(self, x):
# x = x.permute(0, 2, 1)
h = torch.tanh(self.sap_linaer(x))
w = torch.matmul(h, self.attention).squeeze(dim=2)
w = F.softmax(w, dim=1).view(x.size(0), x.size(1), 1)
x = torch.sum(x * w, dim=1)
return x就是我上面谈到的问题了 ,对于一个bert的输出,一般是batch*length*dim.如果你直接mean,那两个5和一个0一个10的结果是一样的。这样会觉得不符合人的直觉。 所以也有用第一个token分类的,取 out[:,0,:]。。 这里的SELF——attpooling 的意思是,对于每一个特征,根据他自己的特征算出该给他赋予的权重。
AMsoftmax : Additive Margin Softmax for Face Verification
class AMSoftmax(nn.Module):
def __init__(self, in_feats, n_classes, m=0.3, s=15, annealing=False):
super(AMSoftmax, self).__init__()
self.linaer = nn.Linear(in_feats, n_classes, bias=False)
self.m = m
self.s = s
def _am_logsumexp(self, logits):
max_x = torch.max(logits, dim=-1)[0].unsqueeze(-1)
term1 = (self.s*(logits - (max_x + self.m))).exp()
term2 = (self.s * (logits - max_x)).exp().sum(-1).unsqueeze(-1) - (self.s*(logits-max_x)).exp()
return self.s * max_x + (term2 + term1).log()
def forward(self, *inputs):
x_vector = F.normalize(inputs[0], p=2, dim=-1)
self.linaer.weight.data = F.normalize(self.linaer.weight.data, p=2,dim=-1)
logits = self.linaer(x_vector)
scaled_logits = (logits-self.m)*self.s
return scaled_logits - self._am_logsumexp(logits)
amsoftmax的功能是 让类内的特征靠的更近, 类外的离得更远 。怎么实现的呢 ?

别问我 ,我也看不懂。用就完事了 ..............
训练 :
训练到现在已经没啥好说的了,训就完事了。
其他
这个作业的主要点也就是这些。 我也不知道怎么提点了。可能有些手段还可以提点 ,比如调参。但是计算资源真的不能供应我尝试。
其他模块跟前几次作业是一样的啦。