Word2vec
处理文本任务首先要将文字转换成计算机可处理的数学语言,比如向量,Word2vec就是用来将一个个的词变成词向量的工具。
word2vec包含两种结构,一种是skip-gram结构,一种是cbow结构,skip-gram结构是利用中间词预测邻近词,cbow模型是利用上下文词预测中间词

这两种模型有三层,输入层,映射层,输出层,隐藏层是线性结构,所以相对于语言模型训练较快。
CBOW模型输入是上下文的词向量,这个词向量时随机初始化的产生的,将这个上下文词向量加起来得到映射层,输出层是层次softmax
层次softmax也是提高Word2vec训练速度的关键技术,为什么层次softmax比普通的softmax要快呢?根本原因当然是层次softmax的计算量要少很多
如果采用普通的softmax,在输出层需要得到一个词典大小的概率分布,公式是softmax(Wx+b),W有一个维度是10000维,这是一个很大的权重矩阵,整个优化目标是10000个
如果是层次softmax,那输出层是一个霍夫曼二叉树,这个二叉树的最大深度是log(D)-1,每个节点处进行一个二分类,二分类的权重矩阵W2有一个维度是2,相对于词典大小10000来说就是很小的数,计算全部叶节点的概率(叶节点数目等于词典大小)就需要中间节点数目个W2大小的矩阵,中间节点数目=D-1
对于CBOW模型来说,如果取窗口大小是3,就是知道前面一个词,后面一个词的词向量,预测中间那个词的词向量,在所有语料中每三个词就是一个样本,比如‘我爱我的祖国’,可以得到‘我 爱 我’,‘爱 我 的’,‘我 的 祖国’三个样本,用这三个样本训练CBOW,先将词‘我’,‘爱’,‘的’,‘祖国’随机初始化,知道‘我’的词向量,用这个词向量来预测‘爱’的词向量,在映射层把上下文词向量相加,在输出层,如果采普通的softmax,就是用softmax(wx+b)这样的公式计算,最终得到的是一个词典大小的向量,表示词典中的每个词是中间词的可能性,这种计算方法需要得到词典中每个词(每个类别)的概率,要得到每个词的概率就要首先得到每个词的打分,其时间复杂度是O(D),计算非常耗时
如果采用层级softmax来计算输出层的概率,因为层级softmax首先构建了一个霍夫曼树,在求解词典中的每个词的概率时不需要计算出所有词的打分,只需要计算根节点到叶节点路径上的概率即可,而路径的最大深度是log(D),最终得到的也是一个词典大小的向量,表示中间词是词典中的某个词的概率。求解某个词对应的概率只需要计算log(D)词运算。
首先要明确的是:softmax与层次softmax在输出层最终得出的都是一个词典大小的向量(概率分布),只不过求解概率分布的方法不同,softmax是直接计算出词典中每个词的打分人后在归一化求概率,层次softmax是先根据语料计算出词典中每个词的词频,然后根据词频构建霍夫曼树,得到霍夫曼树之后就可以得到根节点到每一个叶节点的路径(叶节点代表的就是词典中的每个词,一颗霍夫曼树中有词典大小个叶节点),得到路径之后再根据路径计算词典中每个词的概率,计算这个概率的时间复杂度是O(logD),比直接计算打分的O(D)的时间复杂度低很多。
疑问,你说计算每一条路径的时间复杂度是O(logD),要比O(D)低很多,但是普通的softmax是一下子把所有的词的打分都算出来了,而层次softmax只是算出来一条路径的概率,还有其他的词的概率需要再一次计算,虽然每一条路径的时间复杂度低,但是要计算所有的路径,如何比较计算多次与计算一次谁的用时少呢?
答:首先,的确是普通的softmax一次就把需要的所有词的打分就计算出来了,在进行归一化时不用反复计算,层次softmax需要每条路径都计算一次,但是即使这样,层次softmax也比普通的softmax计算量少,看下面的例子。
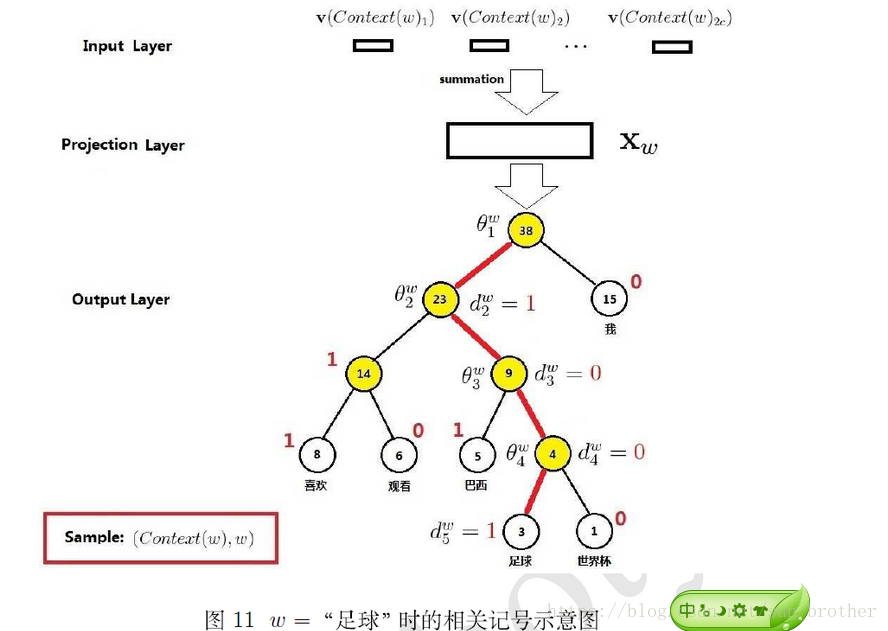
输出层是层次softmax,构建的霍夫曼树如题所示,现在要让输出层输出字典中所有词的概率分布,就要计算每个词的概率,每个词对应的是图中的叶节点,现在假设求出了‘足球’这个词的概率,求这个词概率的时间复杂度是O(logD),那其他词的概率怎么求呢?需要一一计算每一条路径吗?事实上,当我们求出’足球’这个词的概率之后,与红线相连的父节点的另一条分支的概率也求出来了,不需要再重新计算,最后不知道概率的分支只有权值为14的父节点对应的两个叶节点,只需要求出他们其中一个的概率就可以把所有的叶节点的概率求出来,而求14对应的概率的时间复杂度O(剩余分支时间复杂度)<=O(logD),所以,求出所有叶节点的概率的时间复杂度是O(logD)+O(剩余分支时间复杂度),根据时间复杂度的定义,时间复杂度相加的结果是几个加数的最大值,所以层次softmax的总的时间复杂度仍然是O(logD)。
CBOW经过输出层得到字典上的概率分布之后,需要利用目标函数来优化网络实现权重的更新。
对于整个语料而言,优化目标是最大化
其中D是语料中的所有样本,样本的划分根据窗口大小来确定,比如窗口大小为3时,‘我爱我的祖国’可以得到‘我 爱 我’,‘爱 我 的’,‘我 的 祖国’三个样本,每个样本的中间词是要预测的词,因为在输出层得到的是一个词典大小维度的概率分布,只需要将最大概率对应的词当做预测词就可以了,现在还是不知道如何优化呀。of course,现在把上面额优化目标展开,就可以清晰的看到需要优化的权重,
如果输出层是softmax,那么
,就是一个简单的归一化公式,其中
表示待优化参数,代表的是每个词的词向量,这是一个似然函数,优化的过程就是最大似然函数求解的过程,最大似然函数求解用的方法是求导,就是对目标函数进行求导,让导数等于0来求待定参数的过程,在此不详细解说。
如果输出层是层次softmax,根据上图,构建的霍夫曼树的每个节点上有有一个辅助参数
,因为在每个节点处都是一个二分类,要使用逻辑回归进行二分类计算每个节点处的概率肯定要有一个矩阵与Xw相乘,而
就是逻辑回归公式中用到的矩阵,在CBOW模型中这个
没有别的作用,也没有对应的物理意义,就是一个中间变量而已,训练完成后他会被抛弃不要。有了辅助变量就可以得到每一条分支的概率,得到每一条分支的概率之后,将从根节点到叶节点的路径上的所有概率相乘就得到了该叶节点的概率,也就是词典中某个词的概率,将所有的叶节点的概率都求出来就得到词典上的概率分布,现在我们用符号将上面的过程表示出来:
表示二叉树的左右,
=0表示二叉树的左边,
=1表示二叉树的右边,用逻辑回归计算概率时正样本(也就是二叉树的左分支,这个可以随意指定)的概率表示成
与d联合写出来是
可以看出,
用来确定当前结点的左边分支的概率,
用来确定到达某个叶节点是选左边分支还是选右边分支,这样所有的叶节点的概率都可以用这种方法表示出来:
对全部语料来说,目标函数是
这个函数仍然是一个似然函数,对这个函数进行优化采用的是随机梯度下降法最大化目标函数,本质仍是求导。
CBOW模型是否包含词序信息?
单看CBOW的模型图,有上下文的词预测中间的词,而且还把上下文的词向量直接相加了,显然是丢掉了次序信息的,比如‘我爱你’和‘你爱我’这两句话用CBOW模型预测中间词‘爱’得到的结果肯定是一样的,因为‘我’和‘你’的词向量时一样的,在映射层相加的结果也是一样,后面肯定也是一样的,但是如果CBOW不包含词序信息,那这个模型训练出来的词向量为什么还这么好用呢?他的名字是连续词袋模型,还有一种模型叫词袋模型,词袋模型肯定是不包含词序信息的,这个CBOW与BOW的区别又是什么呢?
BOW的定义:
首先给出两个简单的文本文档如下:
John likes to watch movies. Mary likes too.
John also likes to watch football games.
基于上述两个文档中出现的单词,构建如下一个词典 (dictionary):
{"John": 1, "likes": 2,"to": 3, "watch": 4, "movies": 5,"also": 6, "football": 7, "games": 8,"Mary": 9, "too": 10}
上面的词典中包含10个单词, 每个单词有唯一的索引, 那么每个文本我们可以使用一个10维的向量来表示(每个词在该文本中的个数组成的向量来表示该文本的向量表达,一个文本是一个词典大小的向量,向量的每一维是对应位置的词在这条文本中出现的次数)。如下:
[1, 2, 1, 1, 1, 0, 0, 0, 1, 1]
[1, 1,1, 1, 0, 1, 1, 1, 0, 0]
该向量与原来文本中单词出现的顺序没有关系,而是词典中每个单词在文本中出现的频率。
显然,词袋模型没有上下文,没有词序,每个词不用词向量表示,只用一个表示索引的数字表示,除了词频信息外没有其他信息。
CBOW之所以叫连续词袋模型,是因为在每个窗口内它也不考虑词序信息,因为它是直接把上下文的词向量相加了,自然就损失了词序信息。很多博客中都说CBOW抛弃了词序信息,指的就是在每个窗口内部上下文直接相加而没有考虑词序,但是要说用CBOW模型训练出来的词向量完全不包含词序信息(或者说语序信息)我觉得太绝对了,我认为虽然在CBOW的窗口内部丢掉了词序信息,但是在窗口滑动过程中是按照通顺的自然语言顺序滑动的,或者样本就是按照一定的语序取出来的,所以最终得出的词向量中会包含一定的语序信息,只不过通过取样得到的语序信息对词向量的约束很小,不如在CBOW窗口内部加入ngram这种强约束得到的词序信息明确且强烈。但是对一个训练词向量的浅层模型来说,有没有引入词序信息也不是太重要,因为在做具体任务时,只是将词向量作为初始化表征,词序什么的还会有更复杂的模型来捕获他们,一个词向量包含的信息毕竟是有限的。
好,这个问题明确了,CBOW模型窗口内部抛弃了词序信息,对语言来说语序是很重要的,‘我爱你’的词袋特征是‘我’ ‘爱’ ‘你’ ,‘你爱我’的词袋特征是‘你’ ‘爱’ ‘我’,这两个句子的特征是完全相同的,但是这两个句子的语义是不一样的,如果在CBOW窗口内加入ngram特征(比如2gram)就会得到额外的信息,第一个句子的2gram特征是‘我爱’和‘爱你’,第二个句子的特征是‘你爱’ 和‘爱我’,这样就把上下文完全相同的两个句子区分开了,这种做法就是fastText的做法。
fastText原理
fastText简单来说就是将句子中的每个词先通过一个lookup层映射成词向量,然后对词向量取平均作为真个句子的句子向量,然后直接用线性分类器进行分类,从而实现文本分类,不同于其他的文本分类方法的地方在于,这个fastText完全是线性的,没有非线性隐藏层,得到的结果和有非线性层的网络差不多,这说明对句子结构比较简单的文本分类任务来说,线性的网络结构完全可以胜任,而线性结构相比于非线性结构的优势在于结构简单,训练的更快。
这是对于句子结构简单的文本来说,但是这种方法显然没有考虑词序信息,对于那些对词序很敏感的句子分类任务来说(比如情感分类)fastText就不如有隐藏层等非线性结构的网络效果好,比如线面这几个句子是对词序很敏感的类型:
‘The movie is not very good , but i still like it . ’
‘The movie is very good , but i still do not like it .’
‘I do not like it , but the movie is still very good .’
这几个句子的词序差不多,用到的词也差不多,但是表达的意思是完全相反的,如果直接把词向量取平均,显然得到的平均词向量也是相差不到,在经过线性分类器分类很容易把这两个不同的类别分到同一类里,所以fastText很难学出词序对句子语义的影响,对复杂任务还是需要用复杂网络学习任务的语义表达。
对于长文本的文本分类任务来说,就算是用词袋模型,效果也不差
在Word2vec的基础上,把N-grams也当做词来训练word2vec,最后每个词的向量将由这个Ngrams得出。这个改进能提升模型对morphology的效果, 即”字面上”相似的词语distance也会小一些.
fastText包含三部分:模型结构,层次softmax,ngram
fastText和Word2vector的CBOW模型很相似,不同的是fastText预测句子标签,CBOW预测中间词
fastText的Ngram特征
词向量训练中常用的特征是词袋模型,但是词袋模型不能引入词序信息,比如‘我爱你’的词袋特征是‘我’ ‘爱’ ‘你’ ,‘你爱我’的词袋特征是‘你’ ‘爱’ ‘我’,这两个句子的特征是完全相同的。如果加入Ngram,这两个句子的特征就不同了,‘我爱你’的特征由加入了‘我爱’和‘爱你’,你爱我的特征有加入了‘你爱’和‘爱我’,用Ngram得到的特征是完全不同的,这两句话就能区别开了,当然,‘你爱’和‘爱我’这两个词也要包含在词典里,所以会有词频较少的词要舍弃,否则计算量太大的问题。
隐藏表征在不同类别所有分类器中进行共享,使得文本信息在不同类别中能够共同使用。这类表征被称为词袋(bag of words)(此处忽视词序)。在 fastText中也使用向量表征单词 n-gram来将局部词序考虑在内,这对很多文本分类问题来说十分重要。
层次softmax(hierarchical Softmax)
为什么层次softmax可以提高训练速度
要想知道层次softmax能够提高训练速度,肯定要知道他所比较的对象,层次softmax相对于普通的softmax来说极大地提高了训练速度,为什么会出现这样的结果呢?
首先要知道层次softmax的基本思想:
在训练词向量时,对于词典D中的任意一个词w,Huffman树中必存在一条从根节点到词w对应结点的路径(且这条路径是惟一的)在这条路径上存在若干分支,将每个分枝看做一次二分类,每次分类产生一个概率,将这些概率撑起来就是所需的概率p(w|context(w))。
对普通的softmax来说,对字典中的每个词都要预测一下概率,如果字典中有一万个词,那在已知上下文预测中间词的任务中对每个term都要预测1万次再取概率最大的对应的词,而对于层次softmax来说,输出层不是简单的softmax,而是一棵霍夫曼树,霍夫曼树的叶节点的个数是字典大小,他从根节点开始算概率,每次进行一个二分类,每次取较大的概率对应的结点作为下一次二分类的根节点,他的时间复杂度就是树的深度,这个深度是远远小于字典大小的。
在fastText中,由于最终的输出是预测句子的标签,这是一个监督学习过程,所以在训练过程中已经知道了要计算哪一条路径的概率,这样在计算霍夫曼树的路径时只需要计算一条路径而不用计算全部路径,大大提高了计算效率,而在测试过程中,由于没有标签,不知道真实的路径,仍然需要将霍夫曼树的每一个叶节点对应的路径的概率算出来。
fastText与CBOW的区别
fastText的模型和CBOW的模型结构一样,虽然结构一样,但是仍有不同
一、目的不一样,fastText是用来做文本分类的,虽然中间也会产生词向量,但词向量是一个副产物,而CBOW就是专门用来训练词向量的工具。
fastText的输出层是预测句子的类别标签,而CBOW的输出层是预测中间词;
fastText的输入层是一个句子的每个词以及句子的ngram特征,而CBOW的输入层只是中间词的上下文,与完整句子没有关系;
fastText是一个文本分类算法,是一个有监督模型,有额外标注的标签
CBOW是一个训练词向量的算法,是一个无监督模型,没有额外的标签,其标准是语料本身,无需额外标注。
用fastText做文本分类的关键点是极大地提高了训练速度(在要分类的文本类别很多的情况下,比如500类),原因是在输出层采用了层级softmax,层级softmax如何提高训练速度在上面CBOW的层级softmax中已经介绍了,在这里就是将叶节点有词频变成文本分类数据集中每种类别的样本数量,霍夫曼树的结构也可以处理类别不均衡的问题(每种类别的样本数目不同),频繁出现类别的树形结构的深度要比不频繁出现类别的树形结构的深度要小,这也使得进一步的计算效率更高(意思是数目多的样本深度小,那很多样本都只需乘一次就把概率计算出来了,自然就快)。
skip-gram模型
skip-gram模型与CBOW模型的做法刚好相反,skip-gram模型是已知中间词,预测他的上下文,模型结构如图所示
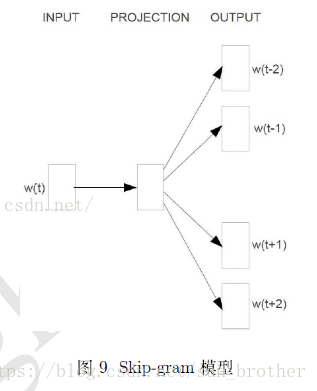
仍是上面的例子‘我爱我的祖国’,输入是‘爱’这个词的词向量,输出上下文两个‘我’,这里的映射层其实没有什么操作,为了统一CBOW和skip-gram模型的形式,方便比较才加了映射层,在skip-gram模型中,输入w(t)的地位就相当于CBOW模型中映射层得到的上下文求和的向量,后面对w(t)的操作与CBOW模型中对
的操作一样。
skip-gram模型的目标函数是
,以一般的情况来讨论,最终输出层输出的是一个词典大小的概率分布向量,要求的上下文是2个,那就去概率最高的前两个对应的词相加得到目标函数的一部分在优化,对整个语料来说,优化目标为最大化
为提高训练速度,输出层仍是采用层次softmax,构造霍夫曼树来做,除了构造霍夫曼树,word2vec还提出了一种提高训练速度的方法,叫做负采样。
负采样(Negative Sampling)
负采样是噪声对比估计的一个简化版本,目的是提高训练速度并改善所得词向量的质量,以CBOW中的负采样为例,目标词w是正样本,其他的词就是负样本了,而在预料中每个词的词频都不同,肯定是词频大的词被采到的概率就大,如何保证采样的公平性,事实上这是一个带权采样的问题,先不讨论负采样被认为是层次softmax的代替,结构简单易实现。
假设已经得到了一个负样本集NEG(w),我们记正样本的标签为1,负样本的标签为0,对于一个给定的正样本(context(w),w),我们希望最大化
因为只有一个w正样本,其余的都是负样本,上式可展开为
最大化g(w)就是最大化第一项(表示正样本),最小化 (负样本这一项),这正是我们所希望的。
Glove
Glove这种训练词向量的方法的核心思想是通过对’词-词’共现矩阵进行分解从而得到词表示的方法。
语言模型
语言模型可以对一段文本的概率进行估计,对信息检索,机器翻译,语音识别等任务有着重要的作用。语言模型分为统计语言模型和神经网络语言模型。下面一次介绍着两类语言模型。
统计语言模型
要判断一段文字是不是一句自然语言,可以通过确定这段文字的概率分布来表示其存在的可能性。比如一段文字有
这m个词组成,看看是不是一句话,就可以用下面的公式计算其联合概率:
在实际操作中,如果文本较长,
的估计会非常困难,所以就出现了一个简化模型N-gram语言模型:当前词只和它前面的n个词有关,与更前面的词无关,上面的式子就可以写成:
经典的统计语言模型就是N-gram语言模型。