前言
2018年 NLP 领域最大的突破毫无疑问是 BERT 预训练模型的提出,它刷新了11项 NLP 任务,本文打算从 Word Embedding 入手,介绍 NLP 当中的预训练发展过程,可能结合后期项目使用相应的算法,由于涉及实际使用,更新跨度会较大,希望能在学习和使用中有自己的发现和心得。
Embed这个词,英文的释义为"fix firmly and deeply in a surrounding mass"。Embedding在数学领域就表征某个数学结构中的一个实例被包含在另外一个实例中,当我们说某个对象 X 被嵌入到另外一个对象 Y 中,那么 Embedding 就由一个单射的、结构保持的映射 f : X → Y 来给定的。此处的结构保持的具体含义要依赖于X 和 Y 是哪种数学结构的实例而定。Word embedding 是NLP中一组语言模型(language modeling)和特征学习技术(feature learning techniques)的总称,这些技术会把词汇表中的单词或者短语(words or phrases)映射成由实数构成的向量上,比如One-Hot编码、High-dimensional sparse word vector、Low-dimensional sparse word vector,这些都是 Word Embedding 的做法。说白了词嵌入就是作为文本当中的输入数据,类比语音中的声谱MFCC等或是图像中的像素值矩阵,但它相较于这两者的不同之处就是在于它是语言模型训练得到的副产品。
NNLM
首先要提一下统计语言模型N元文法模型(N-gram Model),它的作用是为一个长度为 m 的字符串确定一个概率分布
,表示其存在的可能性,其中
到
依次表示这段文本中的各个词。公式如下:
由此而来的基本语言模型:
其实就是假设当前词只与之前1或者几个词有关系,就是隐马尔可夫的思想嘛,因此它有两个重要应用场景:
(1)基于一定的语料库,利用 N-Gram 预计或者评估一个句子是否合理。
(2)评估两个字符串之间的差异程度。这是模糊匹配中常用的一种手段。
NNLM 即 Neural Network based Language Model,由Bengio在2003年提出,它是一个很简单的模型,由四层组成,输入层、嵌入层、隐层和输出层。模型接收的输入是长度为的词序列,输出是下一个词的类别。首先,输入是单词序列的index序列,例如单词 I 在字典(大小为)中的index是10,单词 am 的 index 是23, Bengio 的 index 是65,则句子“I am Bengio”的index序列就是 10, 23, 65。嵌入层(Embedding)是一个大小为的矩阵,从中取出第10、23、65行向量拼成的矩阵就是Embedding层的输出了。隐层接受拼接后的Embedding层输出作为输入,以tanh为激活函数,最后送入带softmax的输出层,输出概率。
NNLM最大的缺点就是参数多,训练慢。另外,NNLM要求输入是定长,定长输入这一点本身就很不灵活,同时不能利用完整的历史信息。以下就是对句子中某一词
的前
项学习网络,就是最大化:
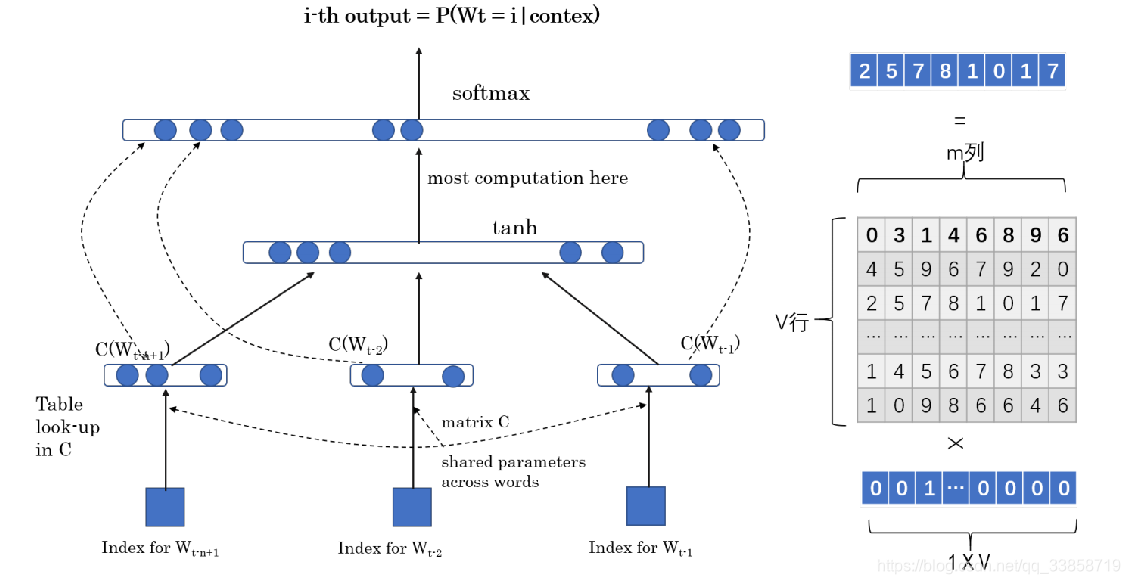
前面的单词用Onehot编码,与右边的矩阵相乘得到输入向量 ,每个单词的输入拼起来最后softmax层输出预测下一个单词,所以网络更新的就是右边这个矩阵的参数,而这个矩阵就是语言模型得到的副产品 Word Embedding, V 代表词典大小,m就是 embedding 的编码数。这个网络用Pytorch实现如下:
class NNLM(nn.Module):
def __init__(self):
super(NNLM, self).__init__()
self.C = nn.Embedding(n_class,embed_size)
self.H = nn.Parameter(torch.randn(n_step*embed_size, n_hidden).type(dtype))
self.W = nn.Parameter(torch.randn(n_step * embed_size, n_class).type(dtype))
self.d = nn.Parameter(torch.randn(n_hidden).type(dtype))
self.U = nn.Parameter(torch.randn(n_hidden, n_class).type(dtype))
self.b = nn.Parameter(torch.randn(n_class).type(dtype))
def forward(self,X):
X = self.C(X)
X = X.view(-1,n_step*embed_size)
tanh = torch.tanh(self.d + torch.mm(X,self.H)) # [bs,n_hidden]
output = self.b + torch.mm(X,self.W) + torch.mm(tanh,self.U) #[bs,n_class】
return output
具体代码可以查看我的github源码
word2vec
Word2Vec是较早提出并使用有效延续至今的NLP任务的简单模型,其中涉及到了两种算法,一个是CBOW一个是Skip-Gram,不同于之前的一些Word Embedding方法,它能够自动实现:单词语义相似性的度量;词汇的语义的类比。反应的是类似下面这种关系:
“国王” – “王后” ≈ “男” – “女”
“英国” – “伦敦” ≈ “法国” – “巴黎” ≈ “首都”
Skip-Gram
给定input word来预测上下文。
Skip-Gram模型实际上分为了两个部分,第一部分为建立模型,第二部分是通过模型获取嵌入词向量。它的整个建模过程实际上与自编码器(auto-encoder)的思想很相似,即先基于训练数据构建一个神经网络,当这个模型训练好以后,我们并不会用这个训练好的模型处理新的任务,我们真正需要的是这个模型通过训练数据所学得的参数,例如隐层的权重矩阵在中实际上就是我们试图去学习的“word vectors”。基于训练数据建模的过程,我们给它一个名字叫“Fake Task”,意味着建模并不是我们最终的目的。以下是网络模型:
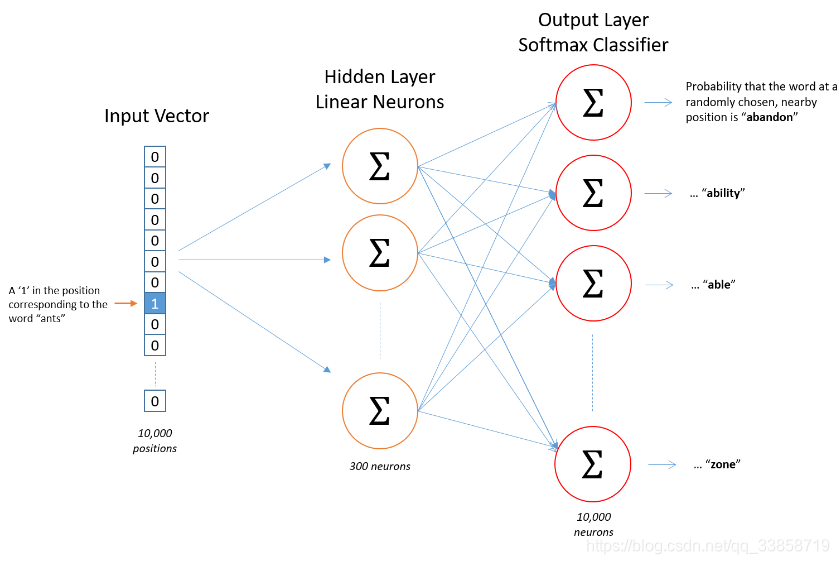
关于这个网络的详细说明,CS224n有官方的笔记可以参考:Skip-Gram
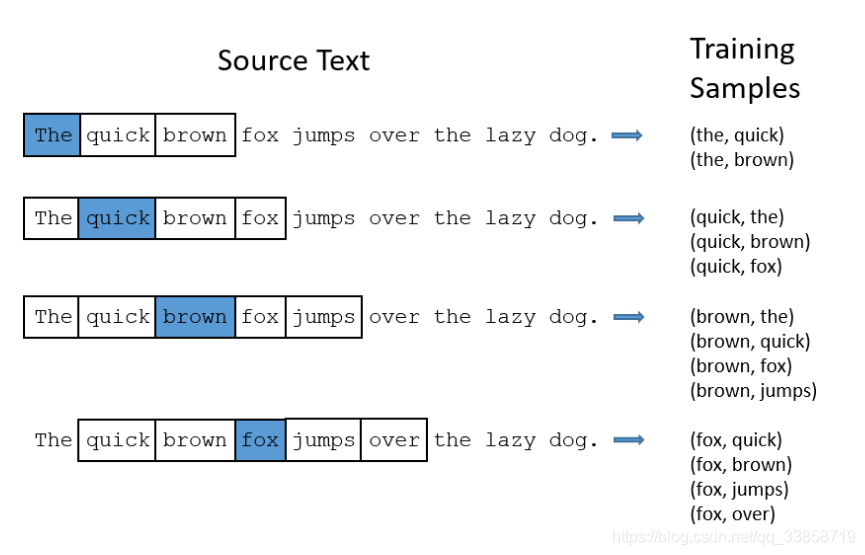
其实就是模型的输出概率代表着到我们词典中每个词有多大可能性跟 input word 同时出现。如下图,蓝色代表 input word ,将skip_num设置为2,则可以得到每个滑框得到的输入网络的样本对,它们同样都是根据样本单词总量来设置Onehot向量。
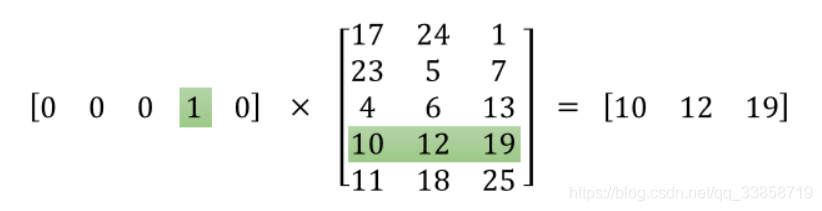
而我们训练得到的隐层矩阵就是一个"单词数" x “embedding特征量” 的权重矩阵,这就是我们所要的 Word Embedding,而其中每一行就是每个单词训练得到的向量表示,我们通过索引(图中的矩阵相乘是便于理解,由于向量的稀疏浪费计算资源一般不会直接矩阵相乘)得到每个单词的向量。
skip-gramgithub上有源码可以参考,使用了pytorch训练了几句简单的句子并可视化了最终得到的词向量的空间分布,因为数据量太少仅仅作为简单的参考。
CBOW
给定上下文预测中间词。
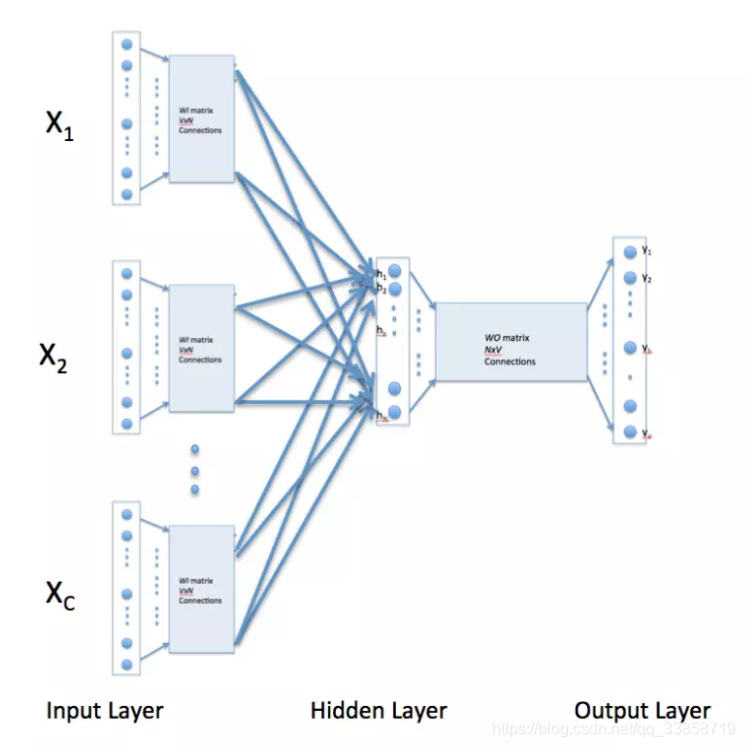
跟前一个做法相反,这里输入层是由one-hot编码的输入上下文组成,其中窗口大小为C,词汇表大小为V。隐藏层是N维的向量。最后输出层是也被one-hot编码的输出单词y。被one-hot编码的输入向量通过一个V×N维的权重矩阵WW连接到隐藏层;隐藏层通过一个N×V的权重矩阵W′连接到输出层。这里就不详细说明了。
总结: 两种Word2Vec算法相比,Skip-Gram精度更高,但CBOW训练时间更短,一般前者更受重用一些,它有个很大的作用就是同义词或是相近用法的词距离更近一些,因为他们的上下文肯定是很相似的,这有助于进行词干化工作(stemming),就是把名字的复数形式、动词的不同时态归为一类的处理,对于文本分类分词等工作有一定帮助。但是这种基于简单网络的Embedding有一个很大的漏洞就在于一词多义的问题,一个单词都是占用一行参数,一个词的不同上下文会把这个词编码到同一个空间去,这就无法在使用时区分多义词的不同语义,而这个问题下面提到的ELMO就可以很好地解决。
GloVe
GloVe 是 Global Vectors for Word Representation 的缩写。
对于One-hot词向量:
无法通过两向量夹角余弦值计算其相似度,word2vec是一种嵌入模型,通过这种模型训练出的词向量可以较好的表示出词之间的相似度,但是word2vec仅仅考虑了两个词在一段上下文的相关度,而GloVe考虑了两个词向量在全文中的相关度。这里首先介绍两种算法:
-
基于奇异值分解(SVD)的LSA算法,该方法对term-document矩阵(矩阵的每个元素为tf-idf)进行奇异值分解,从而得到term的向量表示和document的向量表示。此处使用的tf-idf主要还是term的全局统计特征。
-
另一个方法是word2vec算法,该算法可以分为skip-gram 和 continuous bag-of-words(CBOW)两类,但都是基于局部滑动窗口计算的。即,该方法利用了局部的上下文特征(local context)。
LSA和word2vec作为两大类方法的代表,一个是利用了全局特征的矩阵分解方法,一个是利用局部上下文的方法。GloVe 模型就是将这两中特征合并到一起的,即使用了语料库的全局统计(overall statistics)特征,也使用了局部的上下文特征(即滑动窗口)。为了做到这一点GloVe模型引入了Co-occurrence Probabilities Matrix。
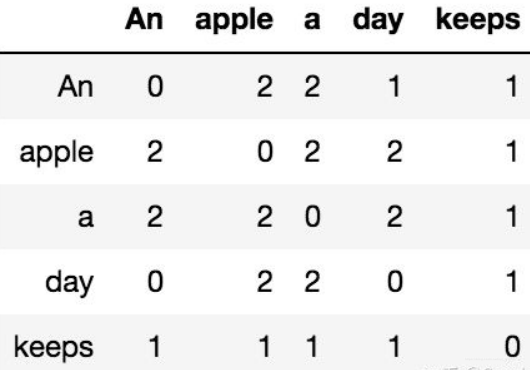
共现矩阵(Co-occurrence Probabilities Matrix)
训练GloVe模型前,首先需要构建一个共现矩阵,设词表大小为V,共现矩阵将是一个V行V列的方阵,而第
行第
列的表示了以第
个中心词
,第
个背景词
出现的次数。
假设我们有上下文:
我们设定滑窗大小m等于2,我们将会有如下中心词-背景词对:

然后遍历中心词-背景词对,更新共现矩阵,以上图为例,最后共现矩阵的结果将有如下形式:
共现矩阵揭示了某种规律,定义共现矩阵的第i行的和为:
之后我们有条件概率,即第j列对应的词出现在第i行上下文中的条件概率:
而对于某个词
,他在第
行或者第
行上下文出现的条件概率的比值:
这个值是可以直接观测并计算到的,并将会有如下规律:
- 如果 与 相关,且 与 相关,那么这个比值将会趋近于1
- 如果 与 相关,且 与 不相关,那么这个比值将会很小
- 如果 与 不相关,且 与 相关,那么这个比值将会很大
- 如果 与 不相关,且 与 不相关,那么这个比值将会趋近于1
损失函数
我们希望设计一个损失函数,希望对词表内每两个词对,
与
,尽可能与
在共现矩阵中对于第
,
上下文中,出现的条件概率比值相近:
两边取对数,对于分子分母:
可以看到问题得到了简化,我们希望左式的分子尽可能等于右式的分子,分母亦然,则问题被简化为:对于词表内任意一组词对
,
,我们希望最小化下式:
其中偏置项
,
将会替换
;
但是并不是每一个词对都是平权的,需要考虑词频来设定每一个词对的权重:
所以我们希望最小化:
最后使用中心词向量 与背景词向量 的和作为中心词向量的表示。
对比word2vec
1、两个模型在并行化上有一些不同,即GloVe更容易并行化,所以对于较大的训练数据,GloVe更快,word2vec速度与数据集规模密切相关。
2、在英文上,glove for GloVe 和 gensim for word2vec是常用的训练词向量的python package,完全可以使用自己的训练语料训练词向量。当然,他们都提供了google news(英文)上训练好的词向量,大家完全可以下载下来,直接使用。对于中文的训练语料,可以使用sogou中文新闻语料。