3.0 ETH数据结构篇
在以太坊中,有三棵树的说法,分别是状态树、收据树和交易树。了解了这三棵树,就弄清楚了以太坊的基础数据结构设计。 而以太坊实现的是一个"平台性"的应用,其复杂性必然较高。因此,其内部数据结构设计也存在一定复杂度。对此,ETH数据结构篇将花费较多篇幅进行编写。
3.1 引入
首先,我们要实现从账户地址到账户状态的映射。在以太坊中,账户地址为160位,表示为40个16进制数。状态包含了余额(balance)、交易次数(nonce),合约账户中还包含了code(代码)、存储(stroge)。
-
直观地来看,其本质上为Key-value键值对,所以直观想法便用哈希表实现。若不考虑哈希碰撞,查询直接为常数级别的查询效率。 但采用哈希表,难以提供Merkle proof。Merkel proof用来证明tree里面有什么,使用Merkle Tree的另一个目的是使各个节点的状态一致。
3.2 思考如何组织账户的数据结构
-
我们能否像BTC中,将哈希表的内容组织为Merkle Tree?这里我个人的理解是,把哈希表中的键值对就像交易的内容一样放在叶子节点。 比如你和一个人要签合同,希望他能证明一下他有多少钱,证明账户余额。一种方法是把哈希表组成一个Merkle tree, 算出一个根哈希值,放在区块头中公布出去,根哈希值是正确的就能保证底下的树没用被篡改。但当新区块发布,哈希表内容会改变,再次将所有的账户状态组织为新的Merkle Tree?如果这样,每当产生新区块(ETH中新区块产生时间为10s左右),都要重新组织Merkle Tree,注意是对账户余额的状态做一个Merkle Tree,账户可以是无限的,所以这不现实。
那为什么比特币系统就直接用了Merkle Tree?比特币系统中是对一个区块中的交易内容进行MT,不是整个账户的余额,区块包含上限为4000个交易左右,所以Merkle Tree不是无限增大的。并且每个区块里的交易信息大多数与上一个区块不一样,所以每个区块建立一个Merkel Tree是正常的,但是在ETH中,账户余额发生变化的仅仅为很少一部分数据,我们每次重新构建Merkle Tree代价很大。
-
那我们不要哈希表了,直接使用Merkle Tree,每次修改只需要修改其中一部分即可,这个可以吗?这里我个人的理解是,把一个账户地址和其所对应的状态直接放在叶子节点上。 但是,Merkle Tree并未提供一个高效的查找和更新的方案。此外,将所有账户构建为一个大的Merkle Tree,必须进行排序(Sorted Merkle Tree),因为账户如果散乱放在叶节点上,那构建的Merkle Tree不唯一,那不利于全节点的状态一致性。但是BTC中为什么不用排序,因为每个挖矿的节点打包交易的顺序确实不一样,但是大家最终会同步获得记账权的节点的块信息,当然就不需要排序。如果以太坊也像比特币一样把账户的状态每次在本地组装成一个Merkle Tree放在区块中然后再发布出去,首先这样的Merkle Tree的占用量很大,其次每次就修改很少的一部分账户余额,但还要把所有的账户状态建立树再打包没必要。
-
那么经过排序,使用Sorted Merkle Tree可以吗? 新增账户,由于其地址随机,插入Merkle Tree时候很大可能在Tree中间,发现其必须进行重构。所以Sorted Merkle Tree插入、删除(实际上可以不删除)的代价太大。
既然哈希表和 Merkle Tree都不可以,那么我们看一下实际中以太坊采取的数据结构:MPT。
注意:BTC系统中,虽然每个节点构建的Merkle Tree不一致(不排序),但最终是获得记账权的节点的Merkle Tree才是有效的。
扫描二维码关注公众号,回复: 14664097 查看本文章
3.3 一个简单的数据结构——trie(字典树、前缀树)
如下为一个通过5个单词组成的trie数据结构(只画出key,未画出value)

特点:
-
trie中每个节点的最大分支数目取决于Key值中每个元素的取值范围(图例中最多26个英文字母分叉+一个结束标志位)。在以太坊中地址表示成40位16进制,16再加上一个结束标志位,一共17个分支。
-
trie查找效率取决于key的长度,键值越长查找访问的内存次数就要更多。在以太坊中,地址长度为40个16进制的数,key值固定是40。(以太坊的地址是公钥取哈希截取后面一半,得到160位的地址。)
-
理论上使用哈希表可能会出现哈希碰撞,意思是两个地址可能不一样但映射到了同一个地方,而trie上面不会发生碰撞。
-
给定输入,无论如何顺序插入,构造的trie都是一样的。
-
更新操作局部性较好。
那么trie有缺点吗? 它的缺点是存储浪费。很多节点只存储一个key,但其“儿子”只有一个,出现一脉单传的情况,过于浪费,对于一些节点需要进行合并。因此,为了解决这一问题,我们引入Patricia tree/trie。
3.4 Patricia trie(Patricia tree)
Patricia trie就是进行了路径压缩的trie。如上图例子,进行路径压缩后如下图所示:

需要注意的是,如果新插入单词,原本压缩的路径可能需要扩展开来。那么,需要考虑什么情况下路径压缩效果较好?树中插入的键值分布较为稀疏的情况下,可见路径压缩效果较好。比如有几个单词很长的时候。
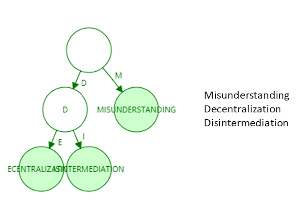
那在以太坊系统中,路径是否稀疏呢?160位的地址存在2^160 种,该数实际上已经非常大了,和账户数目相比,可以认为地址这一键值非常稀疏。为什么要这么稀疏呢?防止账户碰撞(比地球爆炸的概率还要小)。 因此,我们可以在以太坊账户管理种使用Patricia tree这一数据结构!但实际上,在以太坊种使用的并非简单的PT(Patricia tree),而是MPT(Merkle Patricia tree)。 把普通指针换成哈希指针。
3.5 Merkle Tree 和 Binary Tree
区块链和链表的区别在于区块链使用哈希指针,链表使用普通指针。 同样,Merkle Tree 相比 Binary Tree,也是普通指针换成了哈希指针。
所以,以太坊系统中可如此,将所有账户组织为一个经过路径压缩和排序的Merkle Tree,其根哈希值存储于block header中。
BTC系统中只有一个交易组成的Merkle Tree,而以太坊中有三个(三棵树)。 也就是说,在以太坊的block header中,存在有三个根哈希值。
根哈希值的用处:
-
防止篡改。
-
提供Merkle proof,可以证明账户余额,轻节点可以进行验证。
-
证明某个账户是否存在,例如你想向这个账户转一笔钱,想先知道这个账户是否在全节点中存在。如果存在,就把这个分支作为Merkle Proof发过去。
以太坊用的不是原生版的MPT(Merkle Patricia tree)用的是modified MPT。
3.6 Modified MPT (Modified Merkle Patricia tree)
下图为以太坊中使用的MPT结构示意图。右上角表示四个账户(为了直观,显示较少)和其状态(只显示账户余额)。(需要注意这里的指针都是哈希指针)
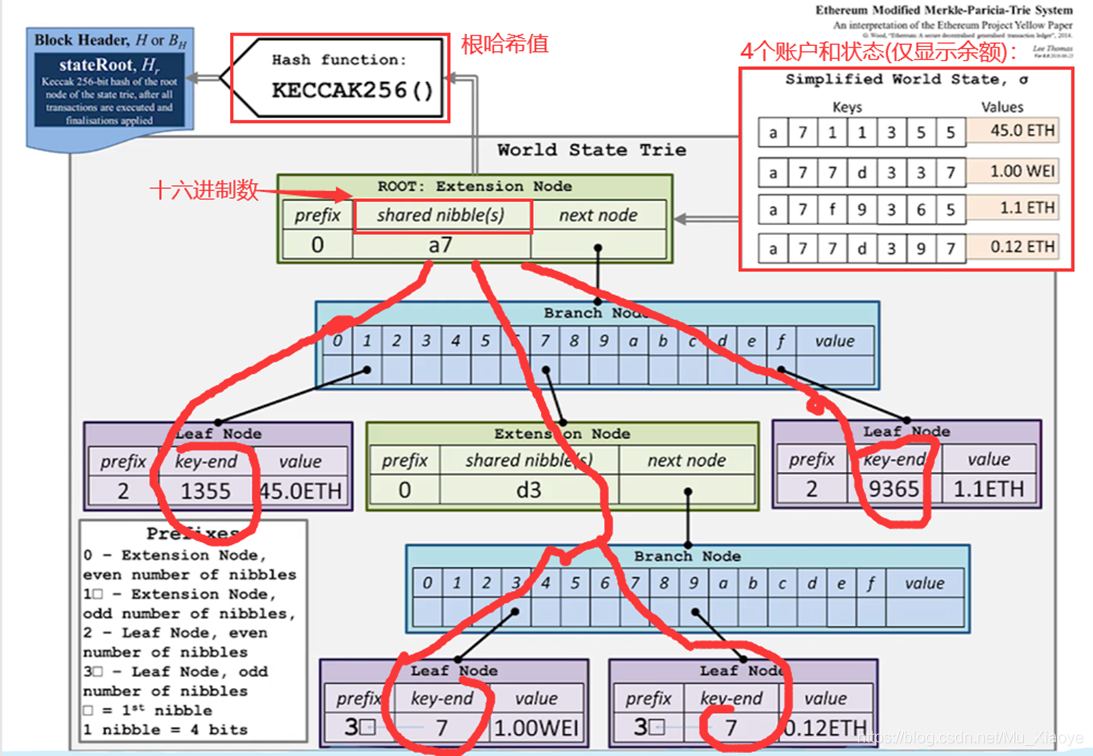
Extension Node: 如果这个节点出现了路径压缩就会是Extension Node。
nibble:十六进制数。
每次发布新区块,状态树中部分节点状态会改变。但改变并非在原地修改,而是新建一些分支,保留原本状态。如下图中,仅仅有新发生改变的节点才需要修改,其他未修改节点直接指向前一个区块中的对应节点。
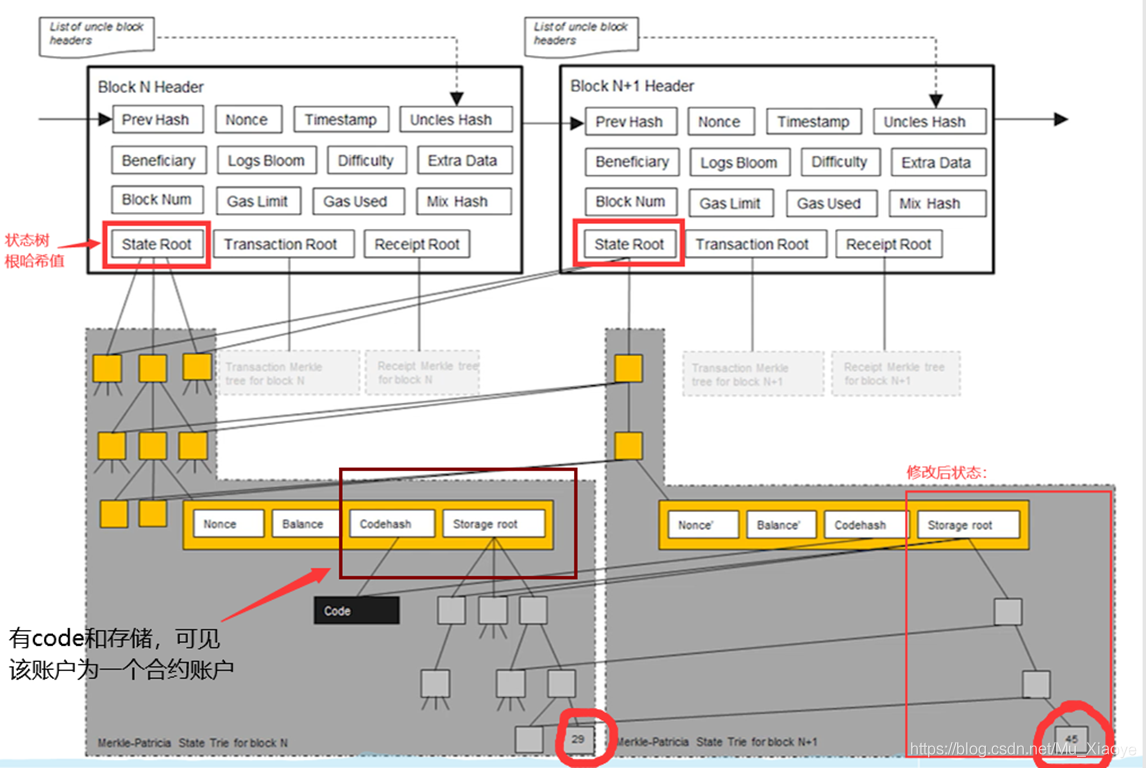
所以,系统中全节点并非维护一棵MPT,而是每次发布新区块都要新建MPT。只不过大部分节点共享,只有少数发生变化的节点要新建分支。
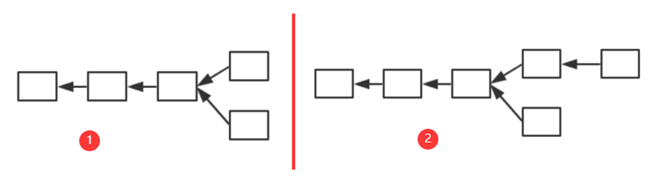
为什么要保存原本状态?为何不直接修改? 为了便于回滚(roll back)。如下1中产生分叉,而后上面节点胜出,变为2中状态。那么,下面节点中状态的修改便需要进行回滚。因此,需要维护这些历史记录。不想比特币简单脚本,如果要发生回滚只需要对账户重新加减,但以太坊中有智能合约,无法轻易的对代码的结果产生回滚。
3.7 通过代码看以太坊中的数据结构
1. block header中的数据结构

ParentHash:前一个区块的块头的哈希值。
Root:状态树的根哈希值。
MixDigest:是根据Nonce经过哈希运算算出来的一个值
2. 区块结构

3. 区块在网上真正发布时的信息

最后说明 状态树中保存Key-value对,key就是地址,而value状态通过RLP(Recursive Length Prefix,一种进行序列化的方法)编码序列号之后再进行存储。