本文是向大家介绍Prometheus中PromQL的查询语法以及常用语句,可以帮助大家理解和掌握Prometheus的查询语言。
1、简介
Prometheus是通过指标名称(metrics name)以及对应的一组标签(labelset)唯一定义一条时间序列。指标名称反映了监控样本的基本标识,而label则在这个基本特征上为采集到的数据提供了多种特征维度。用户可以基于这些特征维度过滤,聚合,统计从而产生新的计算后的一条时间序列。
PromQL是Prometheus内置的数据查询语言,其提供对时间序列数据丰富的查询,聚合以及逻辑运算能力的支持。并且被广泛应用在Prometheus的日常应用当中,包括对数据查询、可视化、告警处理当中。可以这么说,PromQL是Prometheus所有应用场景的基础,理解和掌握PromQL是Prometheus入门的第一课。
2、数据类型
PromQL 表达式或子表达式包括以下四种类型:
瞬时向量 (Instant vector): 一组时序,每个时序只有一个采样值
区间向量 (Range vector): 一组时序,每个时序包含一段时间内的多个采样值
标量 (Scalar): 一个简单的数字浮点值
字符串 (String): 一个简单的字符串值
2.1、瞬时向量选择器
瞬时向量选择器用来选择一组时序在某个采样点的采样值。最简单的情况就是指定一个度量指标,选择出所有属于该度量指标的时序的当前采样值。比如下面的表达式:
apiserver_request_total

可以通过在后面添加用大括号包围起来的一组标签键值对来对时序进行过滤。比如下面的表达式筛选出了 job 为 kubernetes-apiservers,并且 resource为 pod的时序:
apiserver_request_total{job="apiserver",resource="pods"}
匹配标签值时可以是等于,也可以使用正则表达式。总共有下面几种匹配操作符:
=:完全相等
!=: 不相等
=~: 正则表达式匹配
!~: 正则表达式不匹配
下面的表达式筛选出了container是kube-scheduler或kube-proxy或kube-apiserver的时序数据
container_processes{container=~"kube-scheduler|kube-proxy|kube-apiserver"}
2.2、区间向量选择器
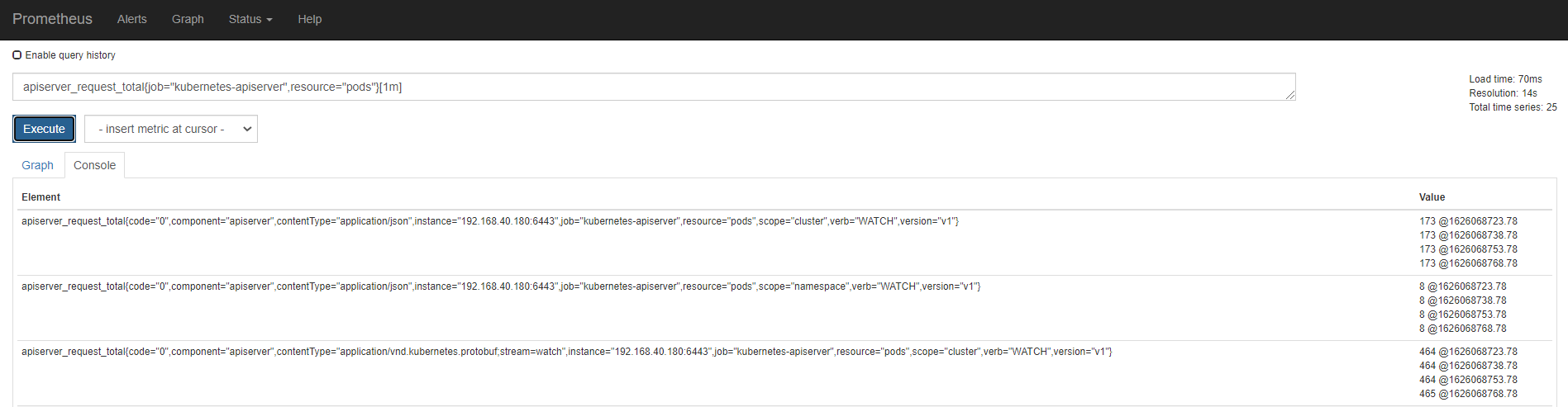
区间向量选择器类似于瞬时向量选择器,不同的是它选择的是过去一段时间的采样值。可以通过在瞬时向量选择器后面添加包含在 [] 里的时长来得到区间向量选择器。比如下面的表达式选出了所有度量指标为apiserver_request_total且resource是pod的时序在过去1 分钟的采样值。
这个不支持Graph,需要选择Console,才会看到采集的数据
apiserver_request_total{job="apiserver",resource="pods"}[1m]
说明:时长的单位可以是下面几种之一:
s:seconds
m:minutes
h:hours
d:days
w:weeks
y:years
2.3、偏移向量选择器
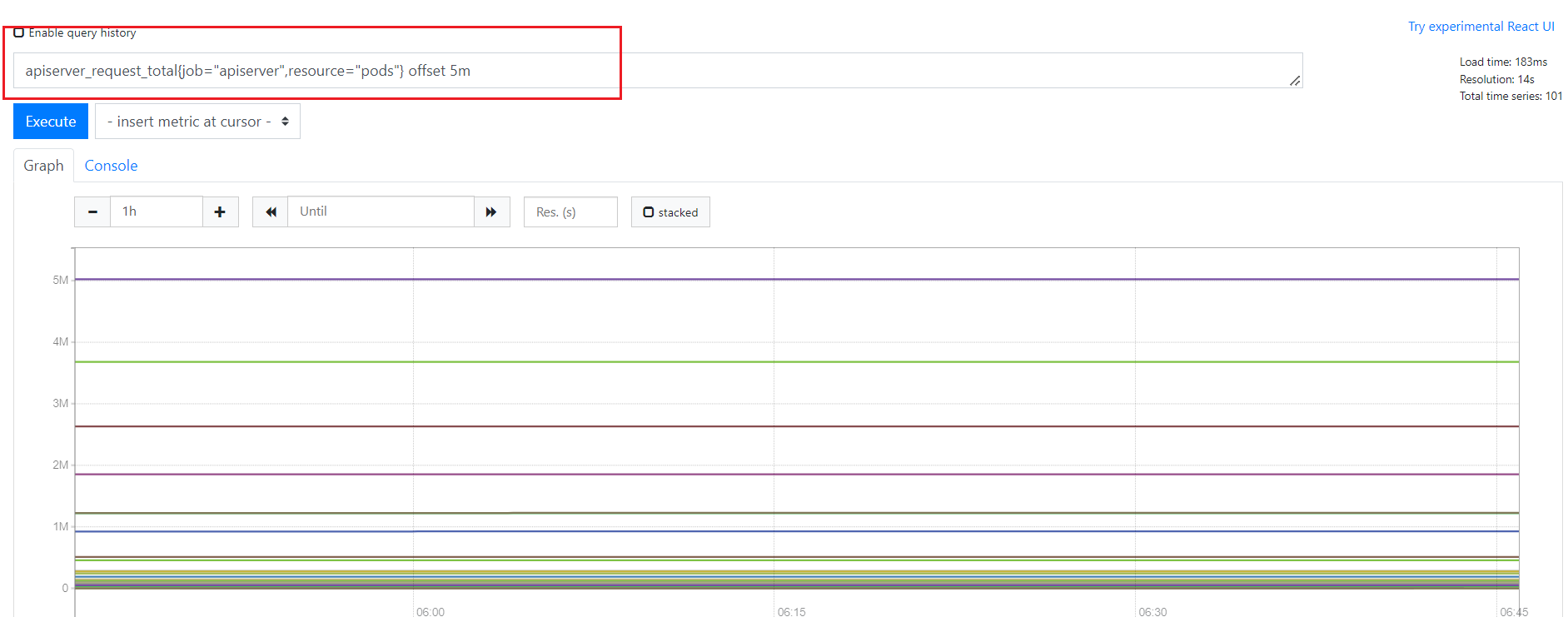
前面介绍的选择器默认都是以当前时间为基准时间,偏移修饰器用来调整基准时间,使其往前偏移一段时间。偏移修饰器紧跟在选择器后面,使用 offset 来指定要偏移的量。比如下面的表达式选择度量名称为apiserver_request_total的所有时序在 5 分钟前的采样值。
apiserver_request_total{job="apiserver",resource="pods"} offset 5m
3、聚合操作符
PromQL 内置的聚合操作符,这些操作符作用域瞬时向量。可以将瞬时表达式返回的样本数据进行聚合,形成一个新的时间序列。
sum (求和)
min (最小值)
max (最大值)
avg (平均值)
stddev (标准差)
stdvar (标准方差)
count (计数)
count_values (对value进行计数)
bottomk (后n条时序)
topk (前n条时序)
quantile (分位数)
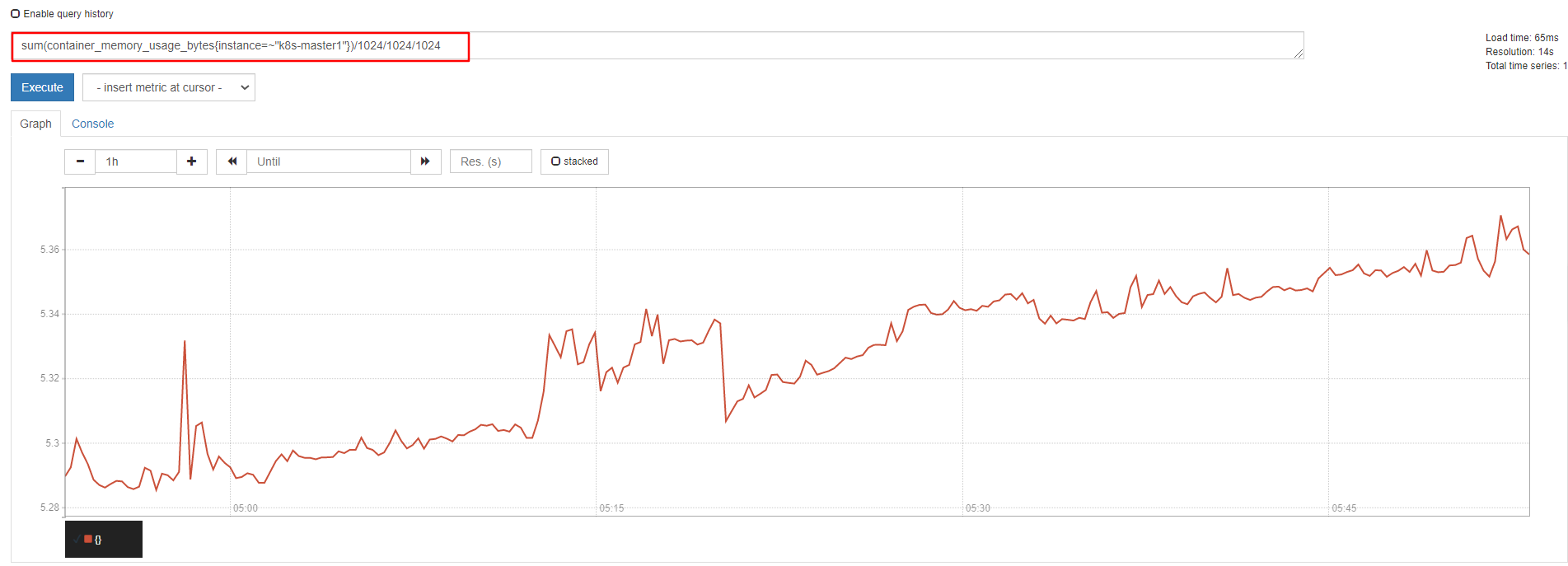
1)计算k8s-master1节点所有容器总计内存:
sum(container_memory_usage_bytes{instance=~"k8s-master1"})/1024/1024/1024
2)计算k8s-master1节点最近1m所有容器cpu使用率
sum(rate(container_cpu_usage_seconds_total{instance=~"k8s-master1"}[1m])) / sum(machine_cpu_cores{ instance =~"k8s-master1"}) * 100
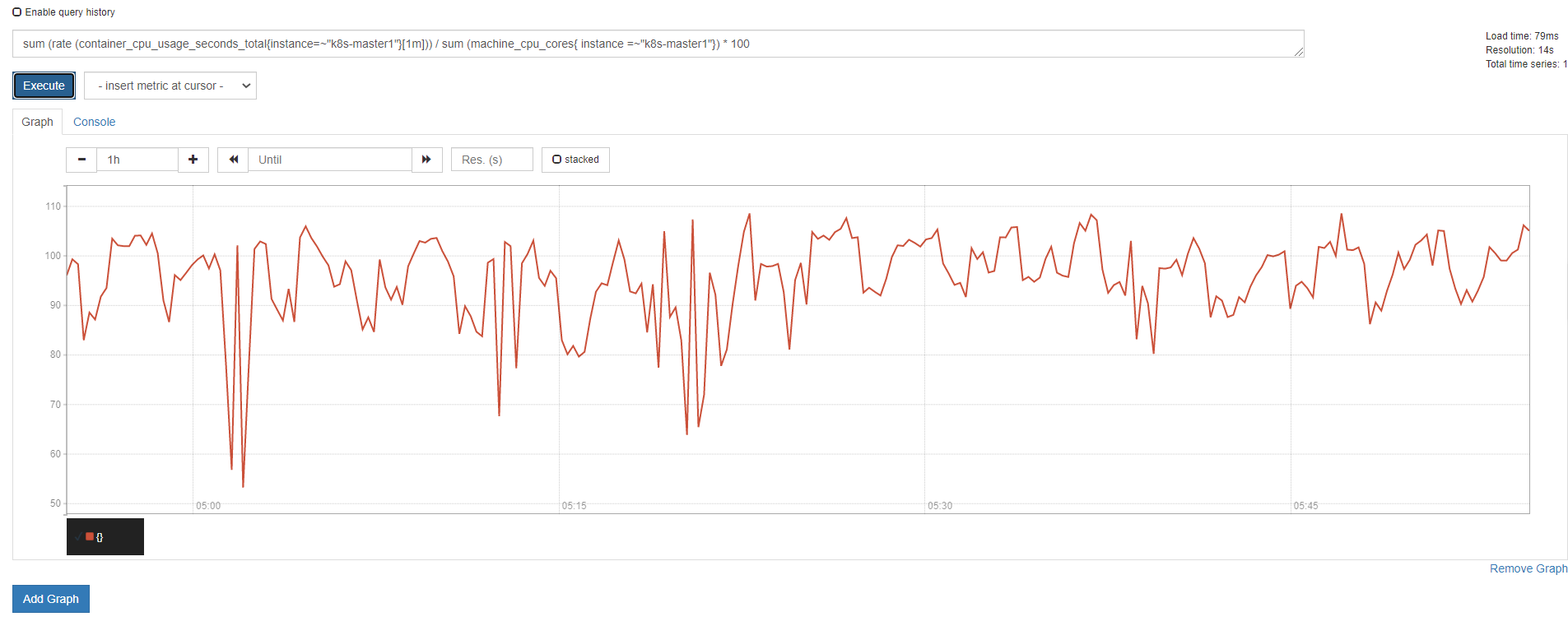
3)计算最近1m所有容器cpu使用率
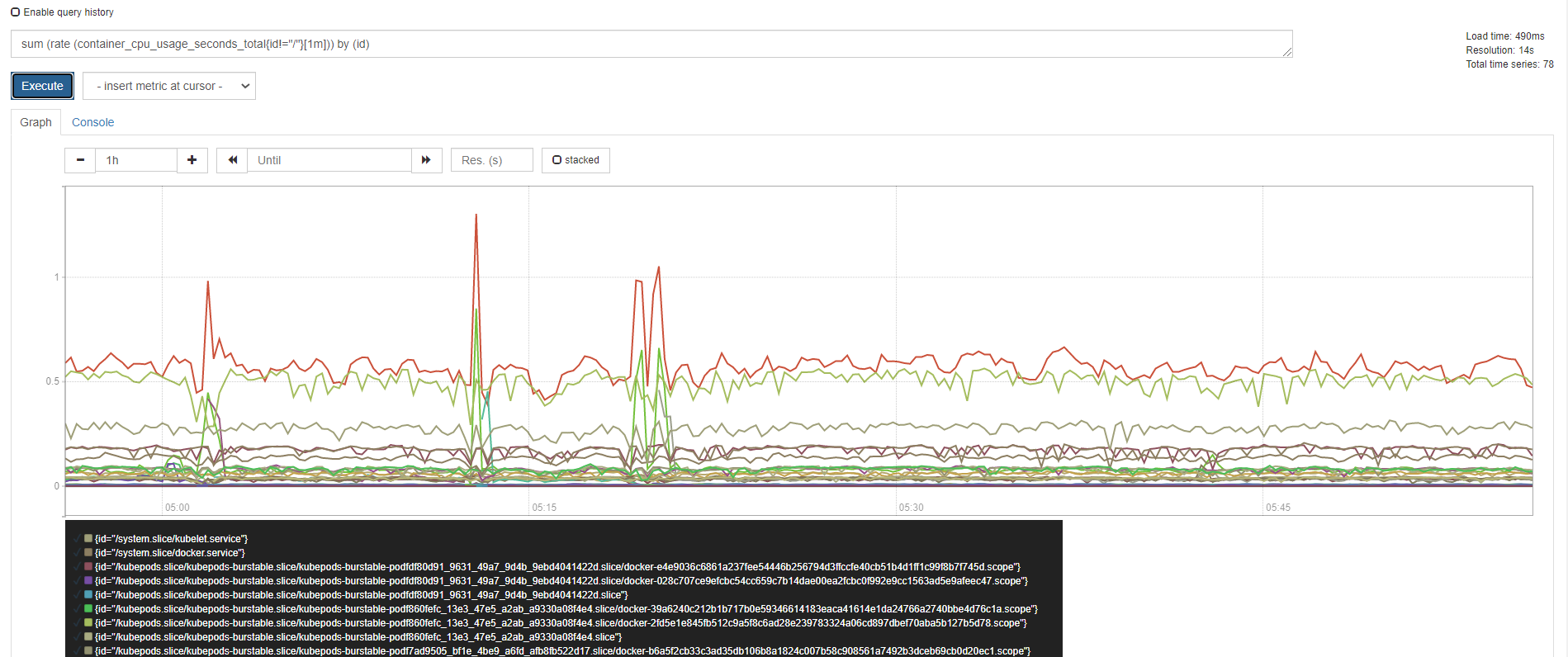
4、内置函数
Prometheus 内置了一些函数来辅助计算,下面介绍一些典型的函数。
abs():绝对值
sqrt():平方根
exp():指数计算
ln():自然对数
ceil():向上取整
floor():向下取整
round():四舍五入取整
delta():计算区间向量里每一个时序第一个和最后一个的差值
sort():排序
rate(): 计算整个时间范围内区间向量中时间序列的每秒平均增长率
irate(): 仅使用时间范围中的最后两个数据点来计算区间向量中时间序列的每秒平均增长率, irate 只能用于绘制快速变化的序列,在长期趋势分析或者告警中更推荐使用 rate 函数
increase(): 计算所选时间范围内时间序列的增量,它基本上是速率乘以时间范围选择器中的秒数
1)查看prometheus_http_requests_total ,平均数据向下取整
floor(avg(prometheus_http_requests_total{code="200"}))
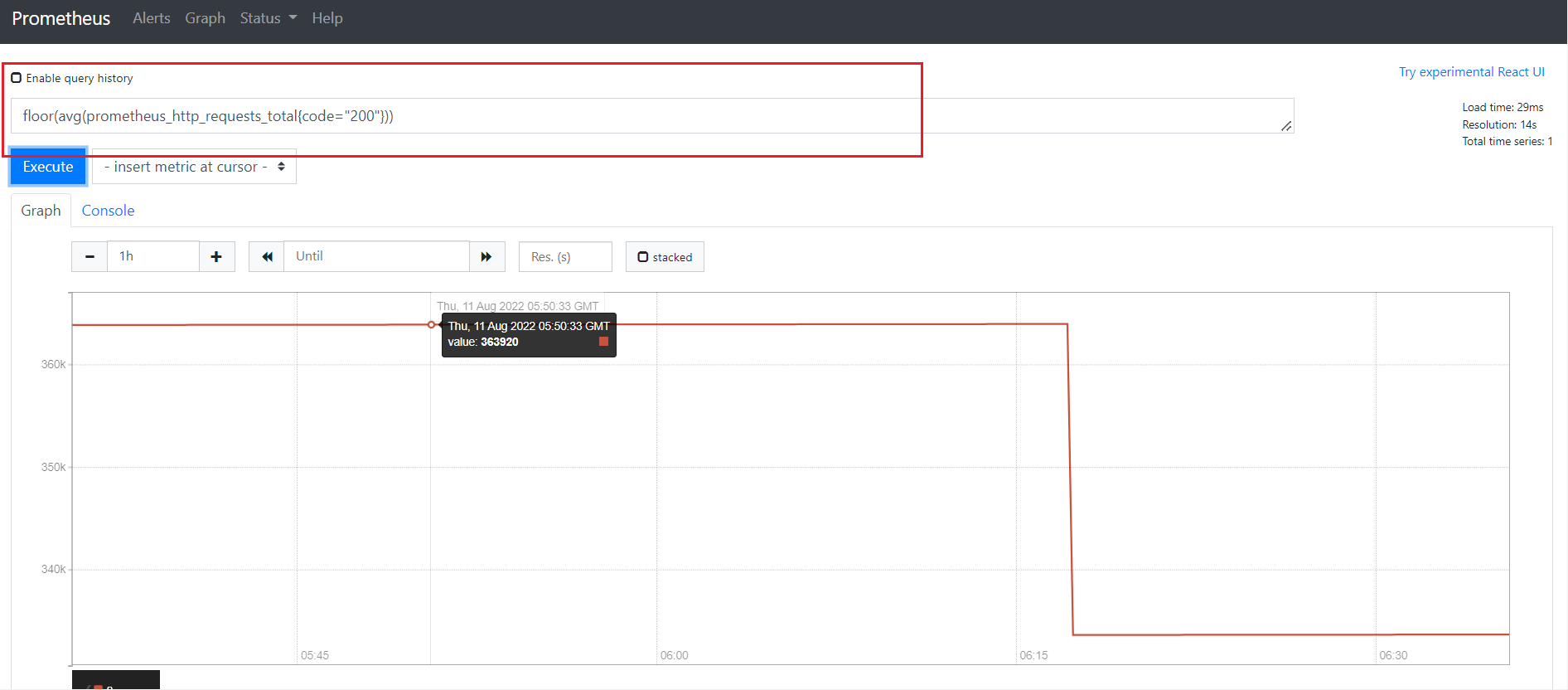
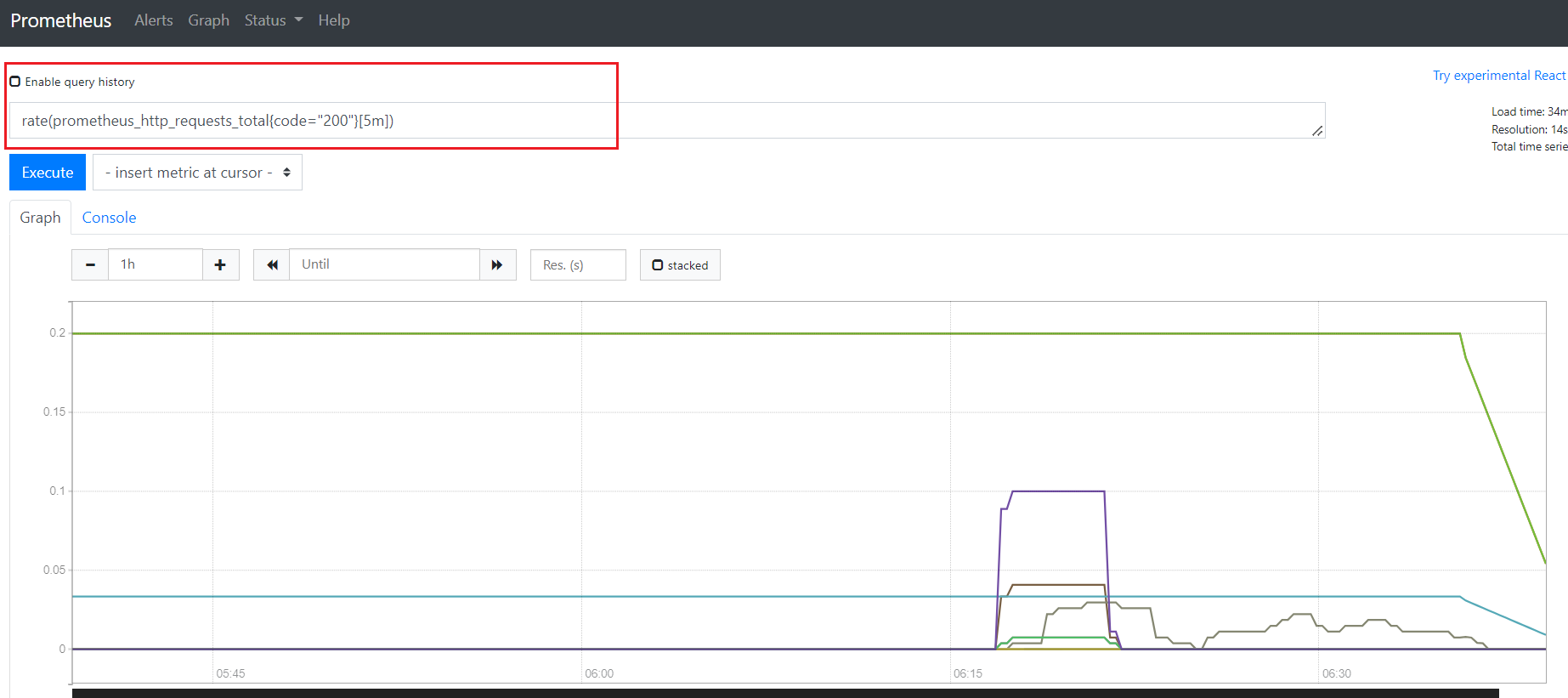
2)查看prometheus_http_requests_total 5分钟内,平均每秒数据
rate(prometheus_http_requests_total{code="200"}[5m])
5、常用 PromQL语句
# Node 节点内存使用量
(node_memory_MemTotal_bytes - (node_memory_MemFree_bytes + node_memory_Buffers_bytes + node_memory_Cached_bytes)) / node_memory_MemTotal_bytes * 100
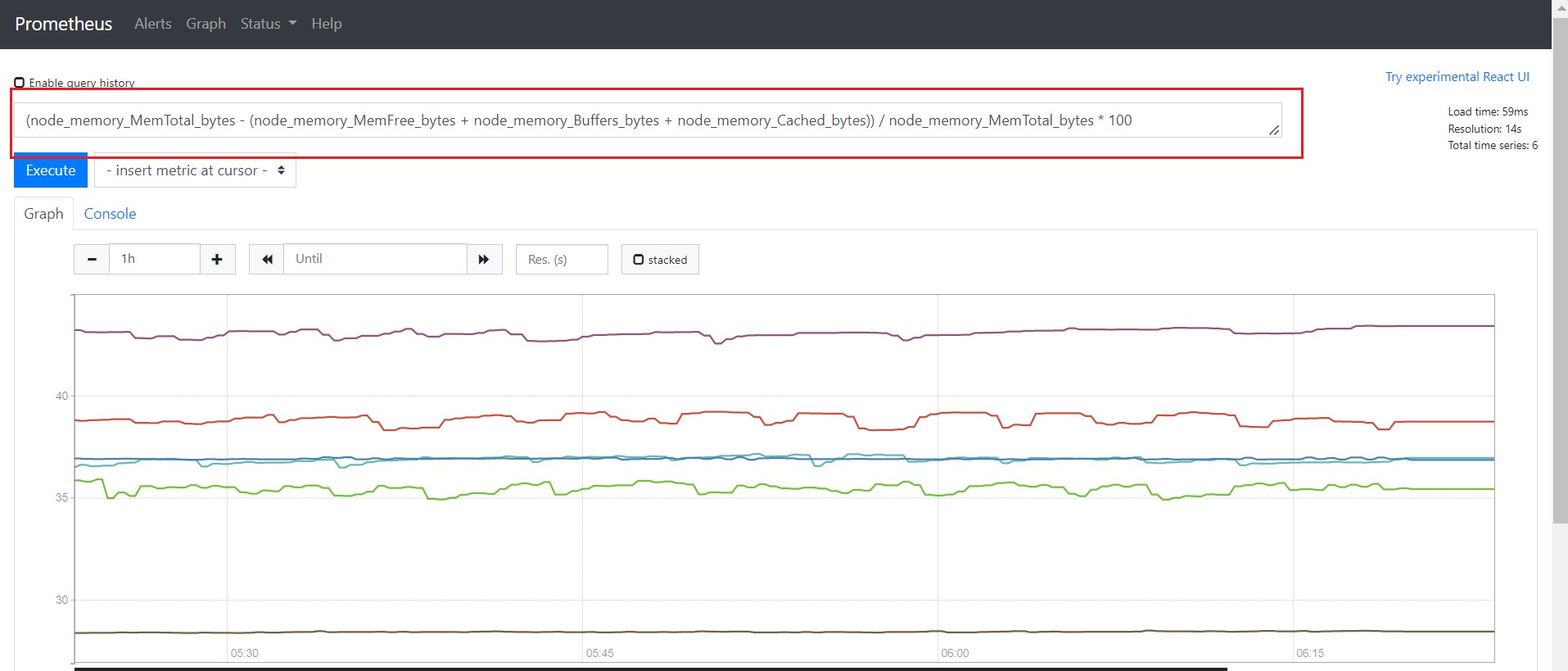
# Node 节点CPU使用率
100-avg(irate(node_cpu_seconds_total{mode="idle"}[5m])) by(instance)*100
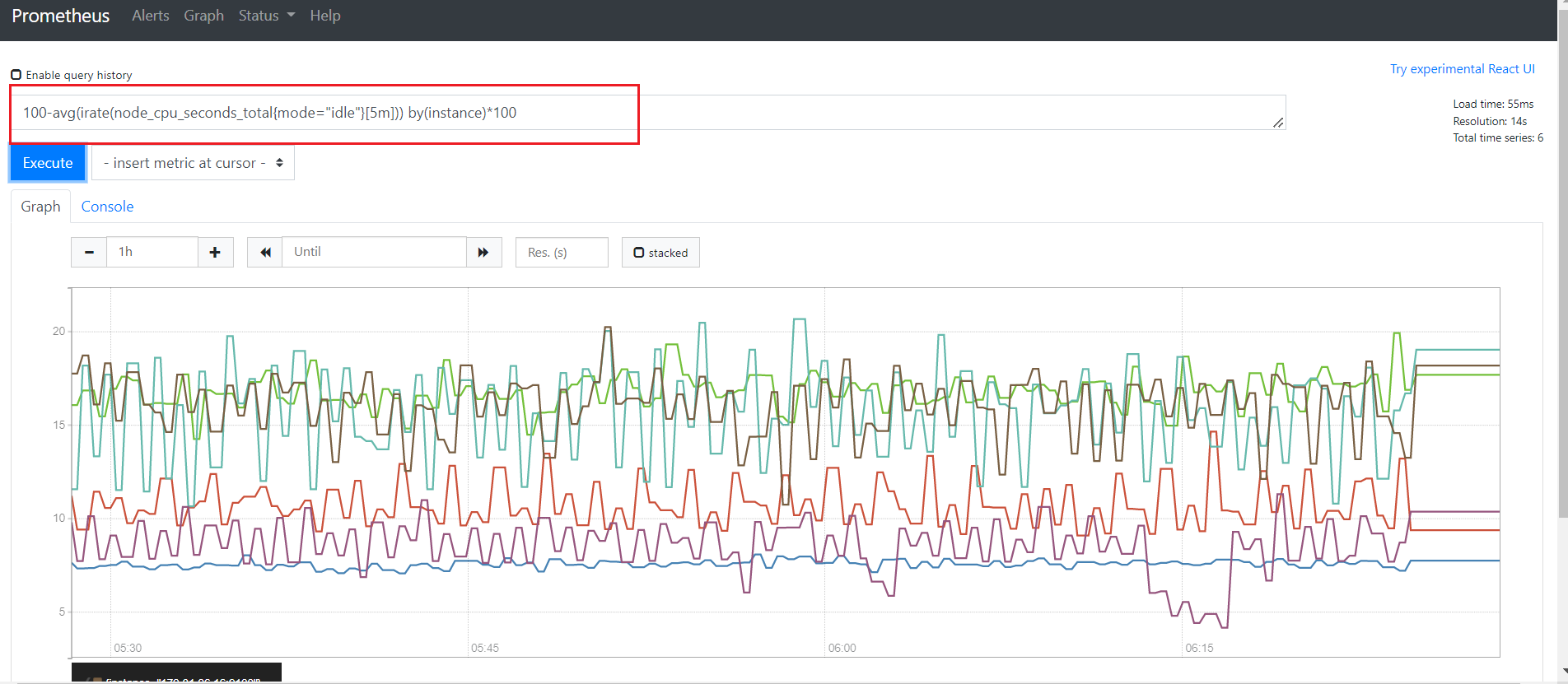
# Node 节点启动状态
up == 1为启动,0为停止
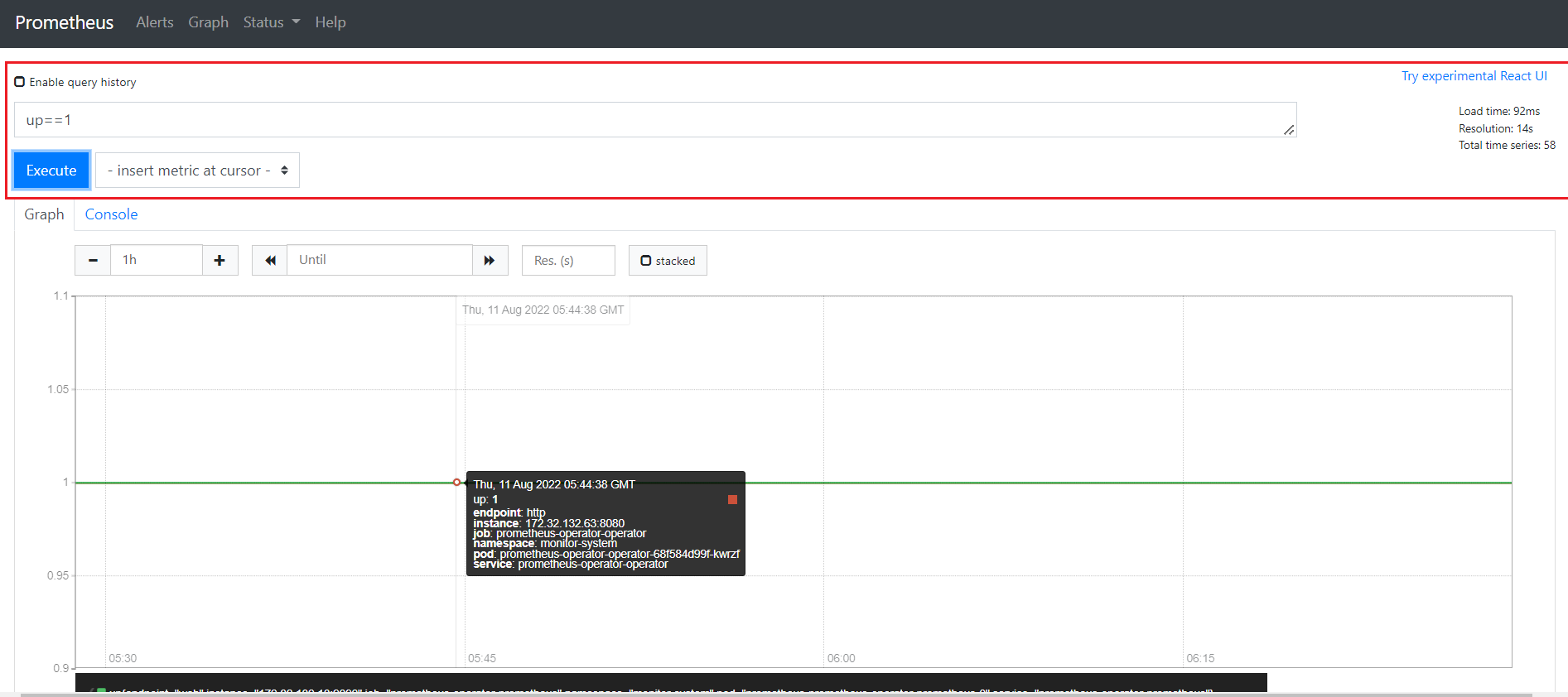
# Node 节点IO性能
100-(avg(irate(node_disk_io_time_seconds_total[1m])) by(instance)* 100)
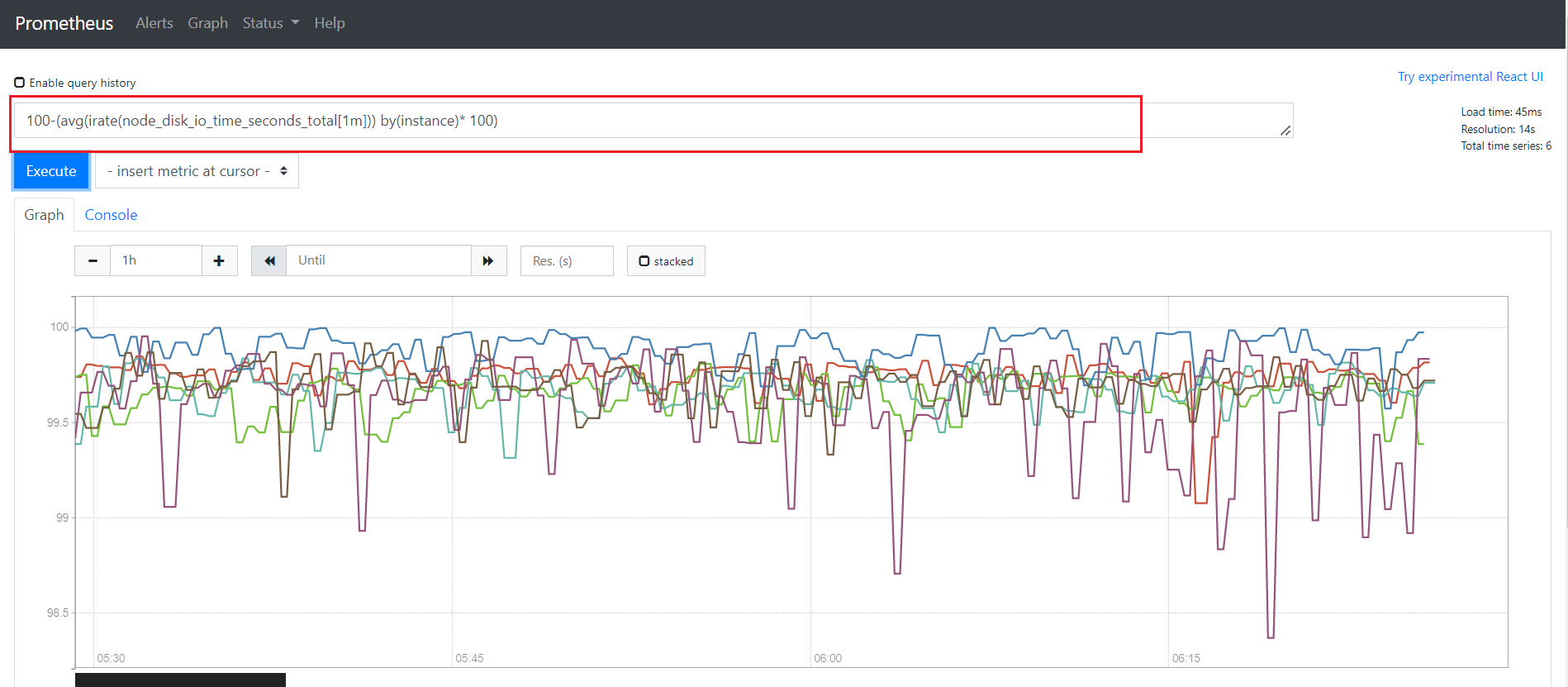
# Node 节点网卡出访流量
((sum(rate (node_network_transmit_bytes_total{device!~'tap.*|veth.*|br.*|docker.*|virbr*|lo*'}[5m])) by (instance)) * 100)
# Node 节点 TCP 会话处于established状态
node_netstat_Tcp_CurrEstab
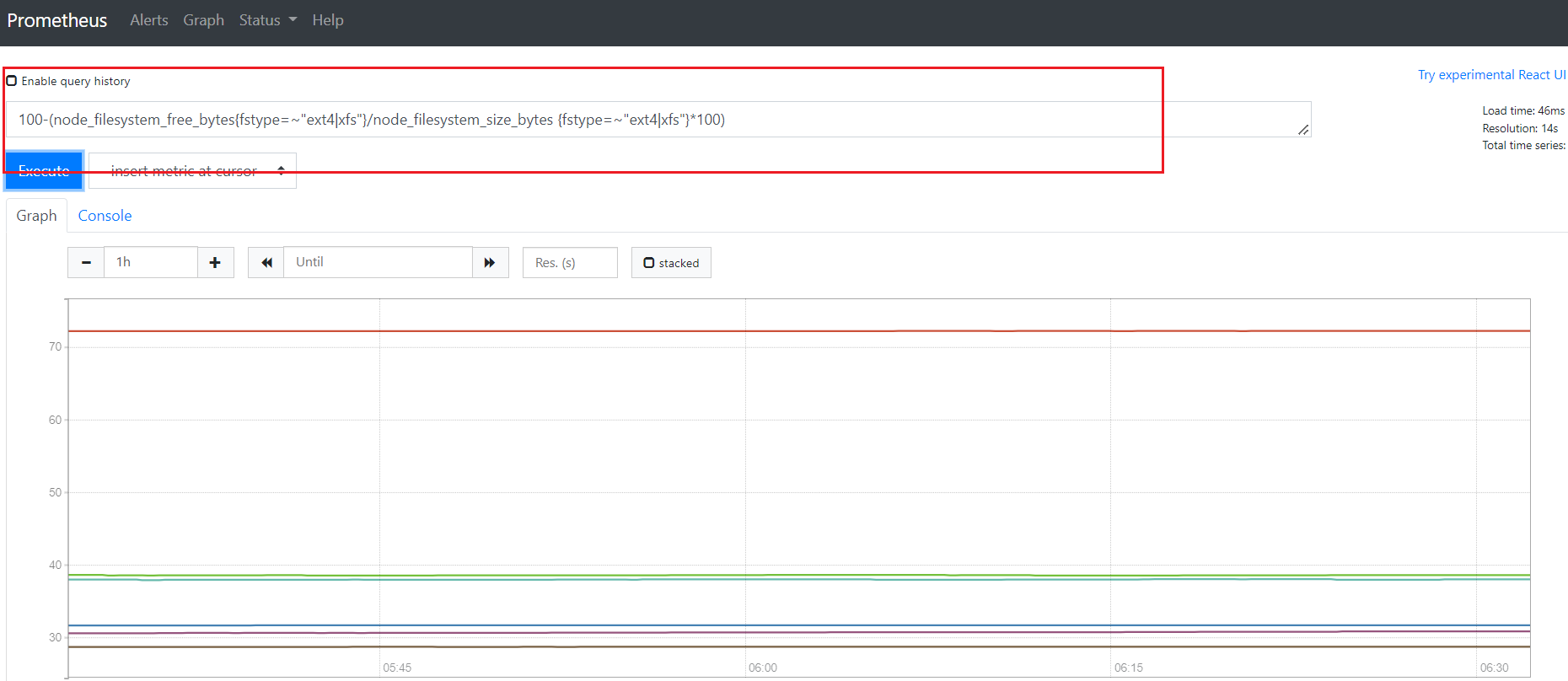
# Node 节点磁盘使用量
100-(node_filesystem_free_bytes{fstype=~"ext4|xfs"}/node_filesystem_size_bytes {fstype=~"ext4|xfs"}*100)