
保持语义信息的物体素描:图片变成简笔画的形式,可生成各种层次的主要轮廓并且保留其主要视觉特征。不仅要把原来的物体变成一个非常简单的形象,也要保证观众能不能看出这到底是个什么物体,这就需要模型抓住原来物体最关键的一些特征。
相关工作:之前的研究都是去收集好的、抽象层次固定的数据集,这属于一种data driven的方式,这种方式生成的素描画风格和形式就收到了限制。这就违背了图像生成的初衷(不同层次)。另一方面,使用固定的数据集还有一个劣势,就是种类不能很丰富,现有的素描数据集种类非常有限。
那么如何摆脱对于有监督数据集的依赖呢?如何寻找一个图像的语义信息抽取的特别好的模型呢?答案就是CLIP!由于图像语义配对的学习方式,对物体的语义信息抓取的特别好,而且又有出色的zero-shot能力。CLIP不受图像风格的限制,始终都能把图像特征编码的非常好。

能通过控制笔画的多少,生成不同层次的简笔画。
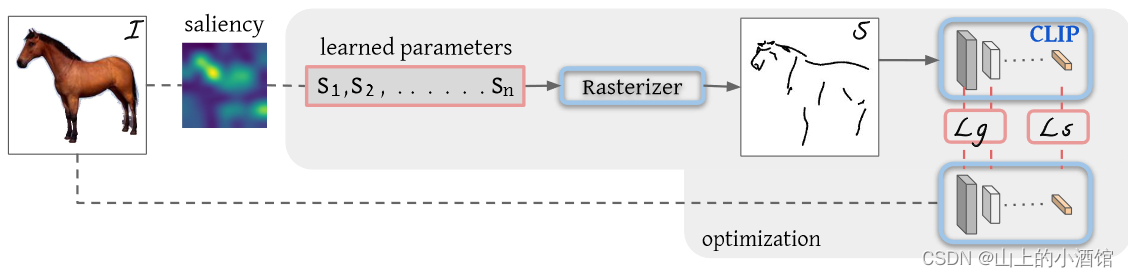
主体部分:任务就是在白纸上随机生成Bezier曲线,然后通过不停的训练,这些曲线就组合成了简笔画。
贝兹(Bezier)曲线就是空间中一系列点控制的曲线(学过CAD的朋友应该了解),在二维空间中的点(x,y),每条线由四点个(p1~p4)控制。通过模型的训练更改四个点的位置来控制Bezier曲线,最后生成简笔画。
随机生成了笔画为n的Bezier曲线,然后通过Rsaterizer(光栅化器)将笔画映射到二维画布上。文章的贡献有两点,前边是如何选择更好的初始化,后边是选择了一个更合适的损失函数。
得到了初步的简笔画,把CLIP模型作为teacher网络,生成伪标签(Ground True),然后用来蒸馏自己的模型。这里借助了CLIP模型的稳健性,如果说初步的简笔画和CLIP输入的原始图像都是一个物体(如上图中都是马),那么经过CLIP后应该都是对马这个物体的描述,两者因尽可能接近。因此就可以将CLIP的image embedding作为伪标签也就是ground true计算损失函数。


作者在原文中也说得很清楚,直接使用一个预训好的CLIP的图像编码器,不需要进一步训练就可以提取自然图像和简笔画。另外,预训好的CLIP的图像编码器由于通过图像文本匹配的方法训练好了,就可以提取出高级的语义信息。损失就是通过余弦相似度计算,生成简笔画与原始图像经过CLIP图像编码后越相似,损失越小。

除了高级的语义描述要尽可能一致外,低层次的空间信息(动作或位置、结构)也应该相似。为了测量这种几何上的相似性,使用L2损失。这里是把模型的前几层拿出来算目标函数,比如Res50,将Res-Layer2、Res-Layer3、Res-Layer4这些层的特征拿出来算目标函数。因为前边层的特征有长宽的概念,对位置(几何)比较敏感。用这些特征去算loss,就能保证几何形状,物体的朝向的一致性。最终的目标函数就是将两者相加,两者结合保证了物体语义上、几何上的一致性。
再一个就是贝兹(Bezier)曲线初始化,最开始的点放在哪很有讲究。就需要一个比较稳定的初始化方式,才能让模型更普适。作者提出基于saliency的初始化方式,具体来说就是用一个训练好的ViT,把最后一个多头自注意力取加权平均做成saliency MAP,就在这些映射上去看哪些特征更显著,然后在显著的区域上去采点。你在显著性的区域上采点,就是你已经知道了一个物体,或者说你已经沿着这个物体的边界去画贝兹曲线了。因此,你初始化的简笔画以及很不错了,与你最后的简笔画相差不多了。
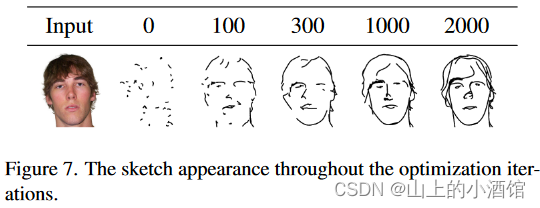
模型一共训练2000次迭代,但在100次迭代时就差不多收敛了,轮廓已经比较明显。这篇文章还有一个很好的点就是模型训练很快。只用一张V100的GPU就能在六分钟完成2000次迭代。

使用注意力采点的初始化后,眼睛等细致的关键特征就在简笔画中体现出来。对比Proposed图和采点图已经非常相似了,这说明一个好的初始化还是非常重要的。

后处理这边是模型每次都生成三个简笔画,然后计算三个loss,最终去最小的loss的简笔画作为最终的输出。
文章主要有以下两个买点:

1.CLIP Passo不受物体类别限制,可以为不常见的物体生成简笔画。

2.CLIP Passo可以通过控制笔画数量来达到任何程度的抽象。
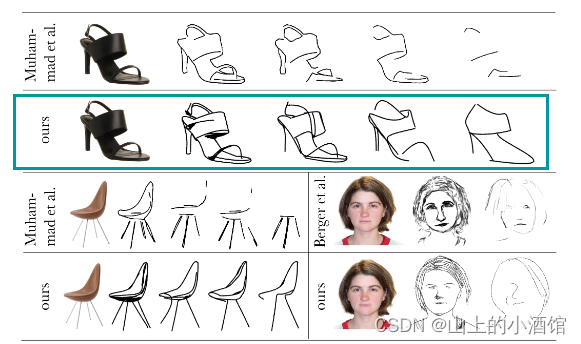
与其他方法相比,CLIP Passo更具备语义信息,更能抓住物体的本质。值得一提的是,右下角CLIP Passo感觉并不如其他方法生成的好,CLIP Passo没有把眼睛生成出来,头发也有些许的草率,或许是更为抽象吧~。
局限性:
1.图像有背景的时候,CLIP Passo效果就会差一些。CLIP Passo还是比较依赖自注意力初始化的,如果一张图像很复杂,那么注意力可能就不在要描述的物体上了,初始化时注意力采点可能就会采到其他物体上,初始化就比较差,最终的效果也就不会好。也就是说抗干扰性要差一些。文中采用的方法就是automati mask,取出前景,遮住背景,然后送进CLIP Passo。这就复杂了一些,变成了two-stage 的模型,如果能提出新的loss能把带背景或噪声的图片解决的很好,那也是很有意义的。
2. CLIP Passo初始化时,笔画都是同时生成的,不像人一样是一笔一笔序列式生成的(有前后顺序,下一笔参考上一笔)。
python的学习还是要多以练习为主,想要练习python的同学,推荐可以去看,他们现在的IT题库内容很丰富,属于国内做的很好的了,而且是课程+刷题+面经+求职+讨论区分享,一站式求职学习网站,最最最重要的里面的资源全部免费。
他们这个python的练习题,知识点编排详细,题目安排合理,题目表述以指导的形式进行。整个题单覆盖了Python入门的全部知识点以及全部语法,通过知识点分类逐层递进,从Hello World开始到最后的实践任务,都会非常详细地指导你应该使用什么函数,应该怎么输入输出。
牛客网(牛客网 - 找工作神器|笔试题库|面试经验|实习招聘内推,求职就业一站解决_牛客网)还提供题解专区和讨论区会有大神提供题解思路,对新手玩家及其友好,有不清楚的语法,不理解的地方,看看别人的思路,别人的代码,也许就能豁然开朗。
快点击下方链接学起来吧!
牛客网 - 找工作神器|笔试题库|面试经验|实习招聘内推,求职就业一站解决_牛客网
参考: