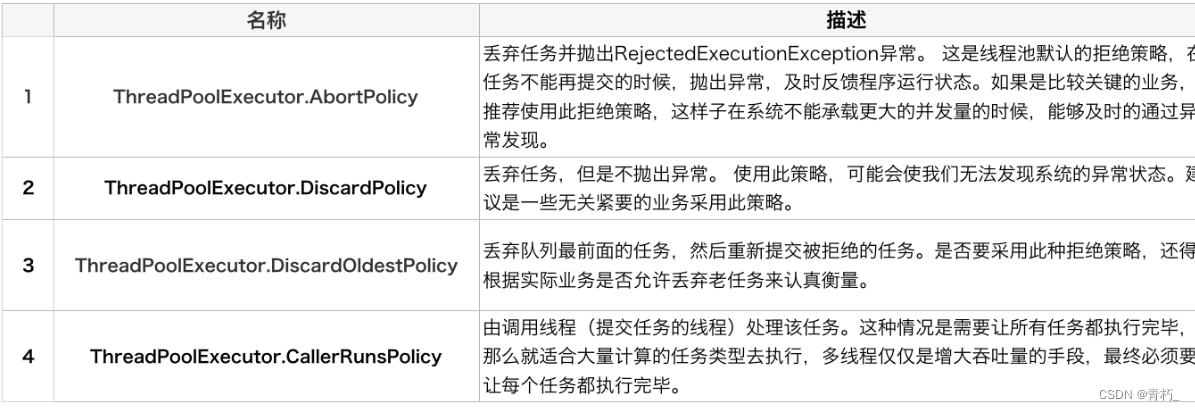
1.背景
实际业务开发中,经常会用到多线程去处理业务提高处理效率,大家对继承Thread、实现Runnable、new Thread这些手动创建线程的方式应该很熟悉,简单业务理论上这种方式没有太大问题,但是这种方式是不建议的。阿里巴巴规约也强制要求不能用手动创建线程的方式,这样创建的线程过多会带来额外的开销,包括创建销毁线程的开销、调度线程的开销等等,同时也降低了计算机的整体性能,影响业务处理效率;

2.介绍以及作用
为了解决手动创建的各种问题,那么就可以使用线程池,谈到线程池就会想到池化技术,其中最核心的思想就是把宝贵的资源放到一个池子中,里面维护多个线程,等待监督管理者分配可并发执行的任务;每次使用都从里面获取,用完之后又放回池子供其他人使用,有点吃大锅饭的意思。它的作用体现在以下几个方面:
- 避免了处理任务时创建销毁线程开销的代价,另一方面避免了线程数量膨胀导致的过分调度问题,保证了对内核的充分利用。
- 降低资源消耗:通过池化技术重复利用已创建的线程,降低线程创建和销毁造成的损耗。
- 提高响应速度:任务到达时,无需等待线程创建即可立即执行。
- 提高线程的可管理性:线程是稀缺资源,如果无限制创建,不仅会消耗系统资源,还会因为线程的不合理分布导致资源调度失衡,降低系 统的稳定性。使用线程池可以进行统一的分配、调优和监控,避免了线程数量膨胀导致的过分调度问题,保证了对内核的充分利用。
- 提供更多更强大的功能:线程池具备可拓展性,允许开发人员向其中增加更多的功能。
实际业务开发中,一般都会根据实际业务并发情况或者cpu资源等等因素自定义创建
ThreadPoolExecutor threadPoolExecutor = new ThreadPoolExecutor(
int corePoolSize,
int maximumPoolSize,
long keepAliveTime,
TimeUnit unit,
BlockingQueue<Runnable> workQueue,
ThreadFactory threadFactory,
RejectedExecutionHandler handler);
参数解释:
int corePoolSize:核心线程数
线程池中的常驻核心线程数,在创建了线程池后,当有请求任务来之后,就会安排池中的核心线程去执行请求任务,当任务数量到达corePoolSize后,就会把到达的任务放入阻塞消息队列队列中;int maximumPoolSize:线程池可支持的最大线程数:
当前线程数达到corePoolSize(核心线程数)后,如果继续有任务被提交到线程池,会将大于核心线程数的任务缓存到阻塞队列中,如果阻塞队列满了,则会去创建一个新线程来出来这个处理,创建的新线程数量则由当前maximumPoolSize数量决定;long keepAliveTime:大于核心线程的其他线程空闲后的存活时间
一个线程如果处于空闲状态,并且当前的线程数量大于corePoolSize,那么在指定时间后,这个空闲线程会被销毁,这里的指定时间由keepAliveTime来设定;TimeUnit unit:释放时间的单位,m,h,d , 和keepAliveTime结合使用BlockingQueue<Runnable> workQueue:阻塞消息队列
当任务数量大于核心线程数,则会放入workQueue阻塞队列中。阻塞队列则又分为以下几种:

ThreadFactory threadFactory:线程工厂
创建一个新线程时使用的工厂,可以用来设定线程名、是否为daemon线程等等RejectedExecutionHandler handler:拒绝策略
当工作阻塞队列中的任务已到达最大限值,并且线程池中的线程数量也达到最大限值(或者说任务数超过最大线程数+阻塞队列数),这时如果有新任务提交进来,则会执行一些拒绝策略:
3.核心参数代码演示
实际业务开发中一般使用注入bean的方式去使用它
@AutoConfiguration
public class TaskExecutorConfiguration {
/**
* 获取当前机器的核数, 请根据实际场景 CPU密集 || IO 密集
*/
public static final int cpuNum = Runtime.getRuntime().availableProcessors();
@Bean
public Executor getAsyncExecutor() {
ThreadPoolTaskExecutor taskExecutor = new ThreadPoolTaskExecutor();
// 核心线程大小 默认区 CPU 数量
taskExecutor.setCorePoolSize(corePoolSize.orElse(cpuNum));
// 最大线程大小 默认区 CPU * 2 数量
taskExecutor.setMaxPoolSize(cpuNum * 2);
// 队列最大容量
taskExecutor.setQueueCapacity(500);
taskExecutor.setRejectedExecutionHandler(new ThreadPoolExecutor.CallerRunsPolicy());
taskExecutor.setWaitForTasksToCompleteOnShutdown(true);
taskExecutor.setAwaitTerminationSeconds(60);
taskExecutor.setThreadNamePrefix("Test-Thread-");
taskExecutor.initialize();
return taskExecutor;
}
下面演示一下核心线程、最大线程、拒绝策略参数的执行原理: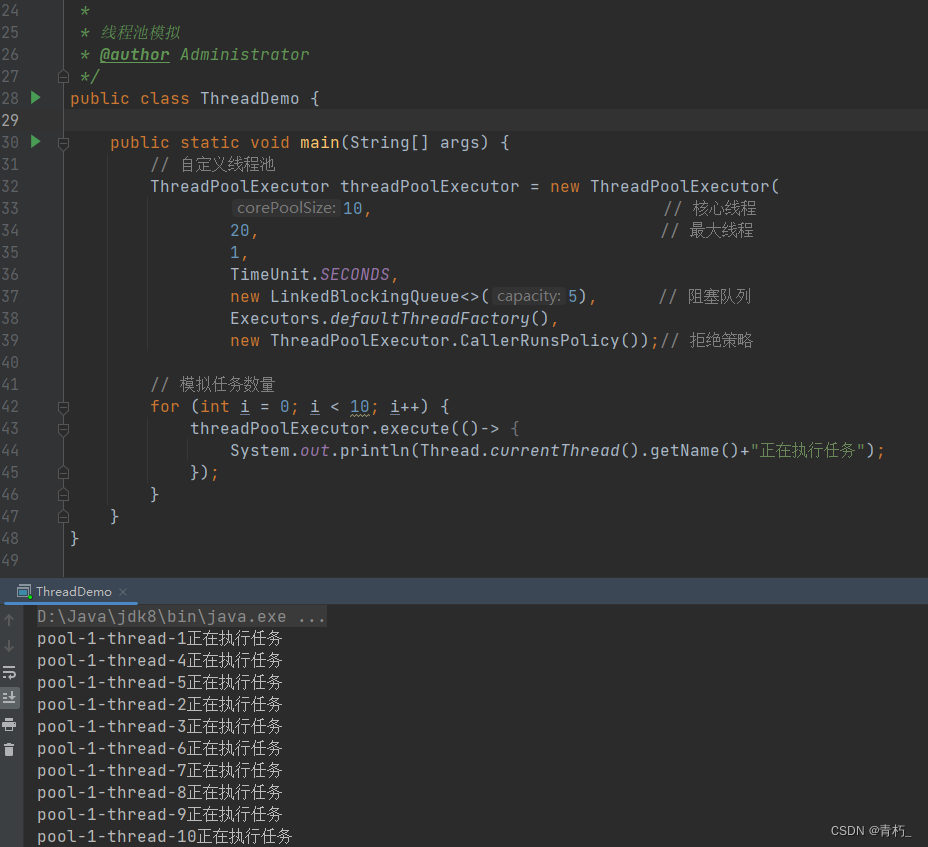 任务数量:10,
任务数量:10,
核心线程: 10,
最大线程数: 20,
阻塞队列数量:5,
拒绝策略:CallerRunsPolicy(由调用线程,也就是提交任务的线程处理该任务)
此时可以看到核心线程10个,任务也是10个,此时任务数等于核心线程数,核心线程数量刚好够用,控制台打印10个线程去执行10个任务。如果我们加到11个任务呢? 此时核心线程数量是不够的,多出一个任务,那么此时,就会把多出的这一个任务放到队列中,等待核心线程执行完其他任务就会分配一个线程过来执行阻塞队列中的任务;所以还是10个线程去执行11个任务,所以如果我们我们开启15个线程以及15个线程以内的任务,都会用这10个核心线程数去执行15个任务,如下图:
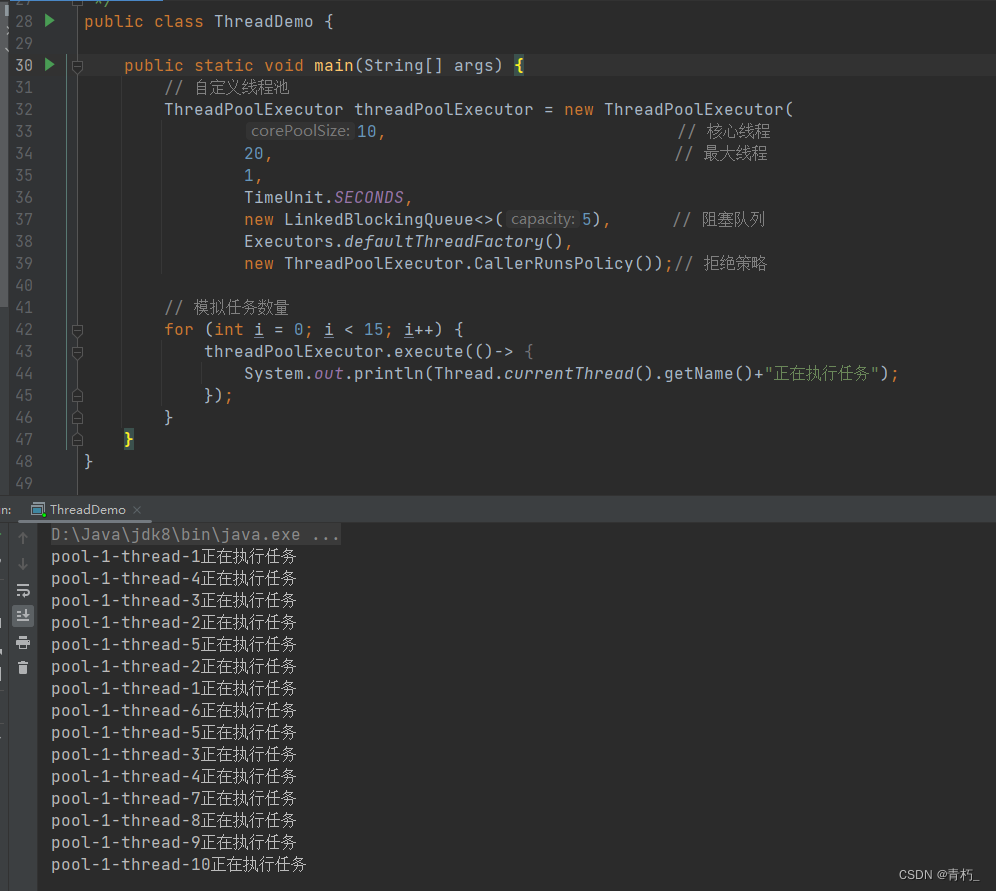
可以看到1、2、3、4、5号线程执行了两次。
如果超过(核心数+阻塞队列)数量,执行16个任务,核心线程数10个,可以运行10个任务,阻塞队列中可以放入5个,那么多出一个怎么办? 此时最大线程数量起作用了,最大线程数配置的是20个,所以又创建一个线程去执行阻塞队列中放不下的一个任务;如下图:

17个任务:12个线程
18个任务:13个线程
19个任务:14个线程
20个任务:15个线程
21个任务:16个线程
…
25个任务:20个线程,如下图
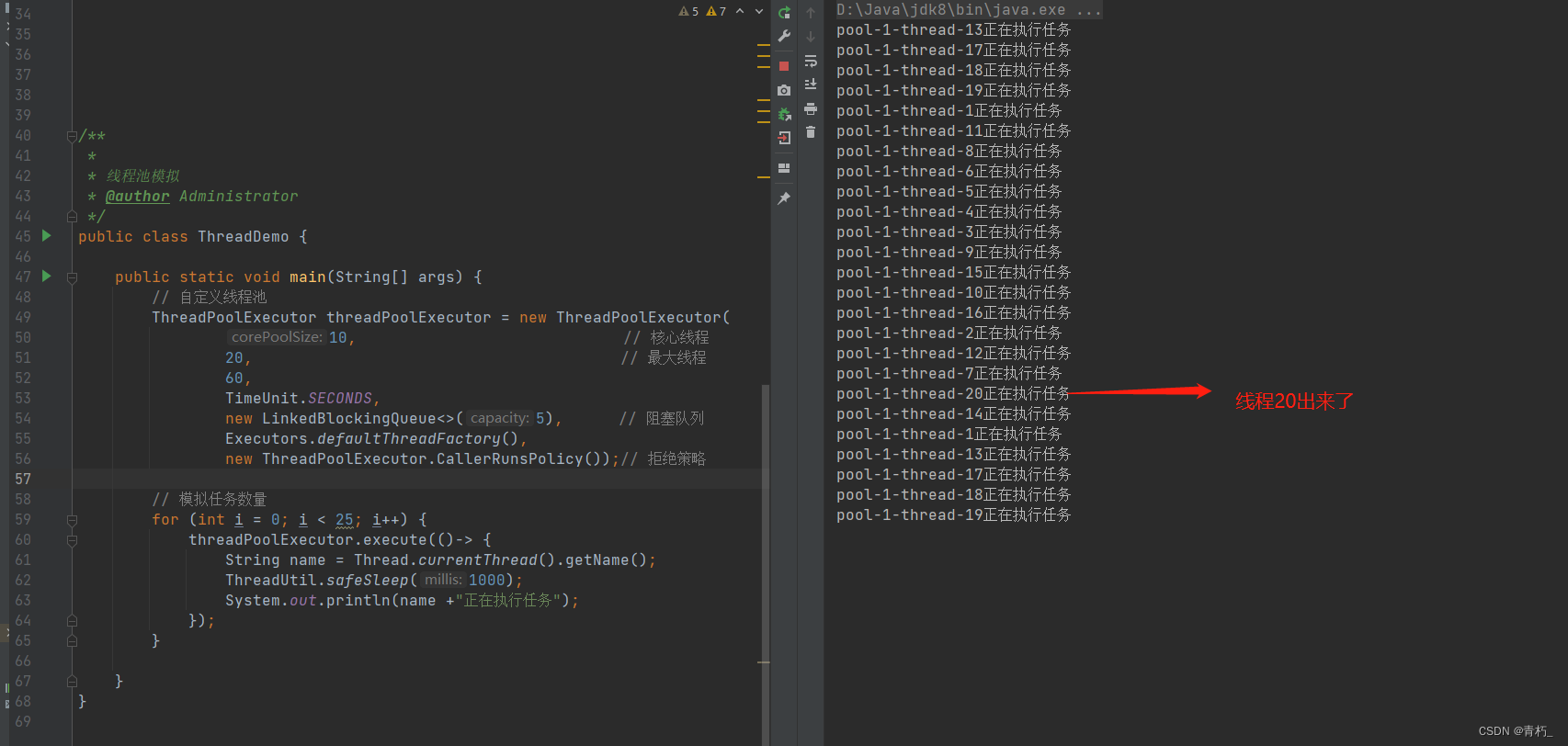
此时25个线程,配置的最大线程数是20,那么就是20个线程去执行任务,剩下5个在阻塞对列中;
那么问题又来了,如果超过25个线程会怎么处理?此时线程池的拒绝策略该上场了:
以上演示配置的拒绝策略是:
-
CallerRunsPolicy():如果任务数大于25,大于25的任务则由调用者(咱们这里用的main方法),所以main线程去处理,演示如下:
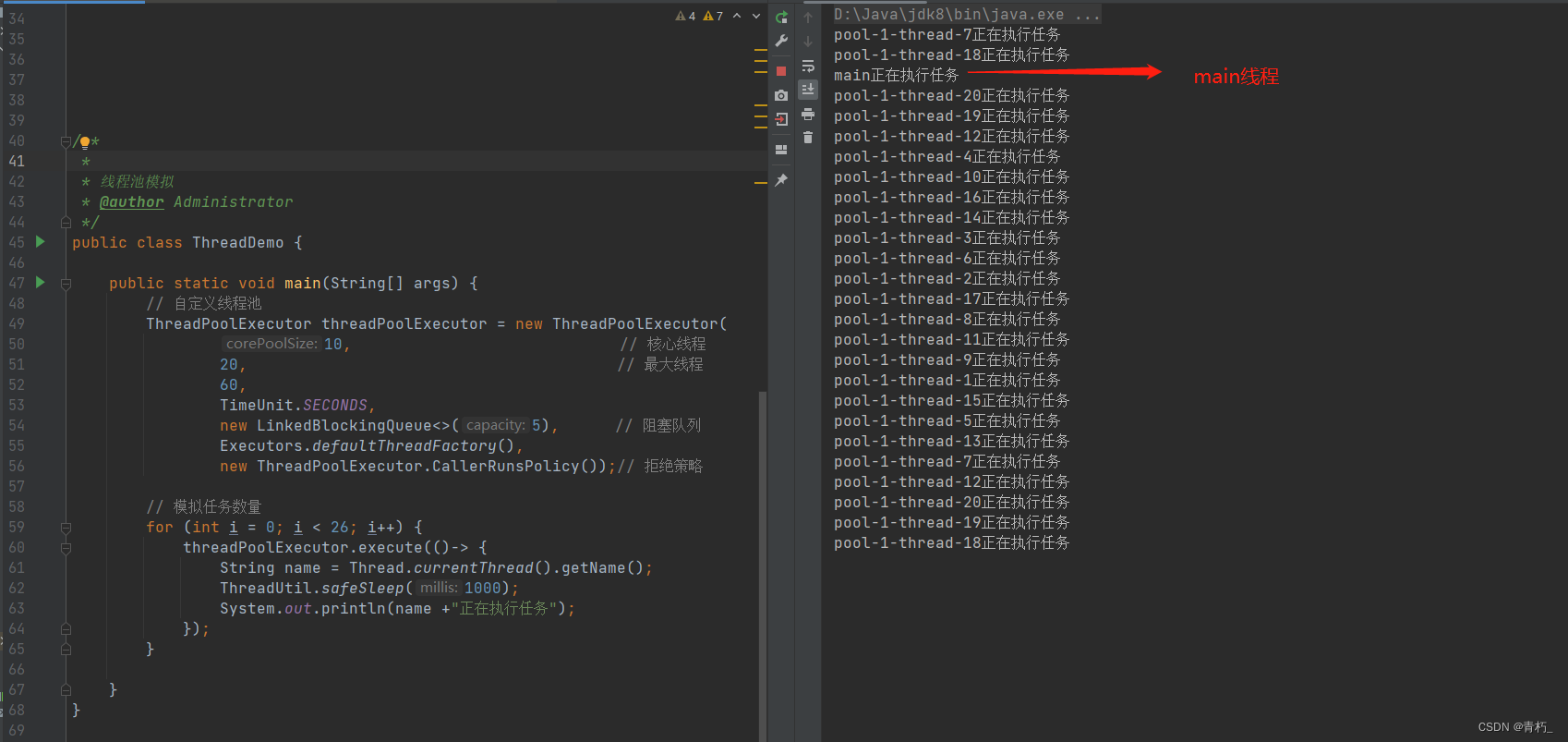
-
AbortPolicy():丢弃任务并抛出异常,如下图:
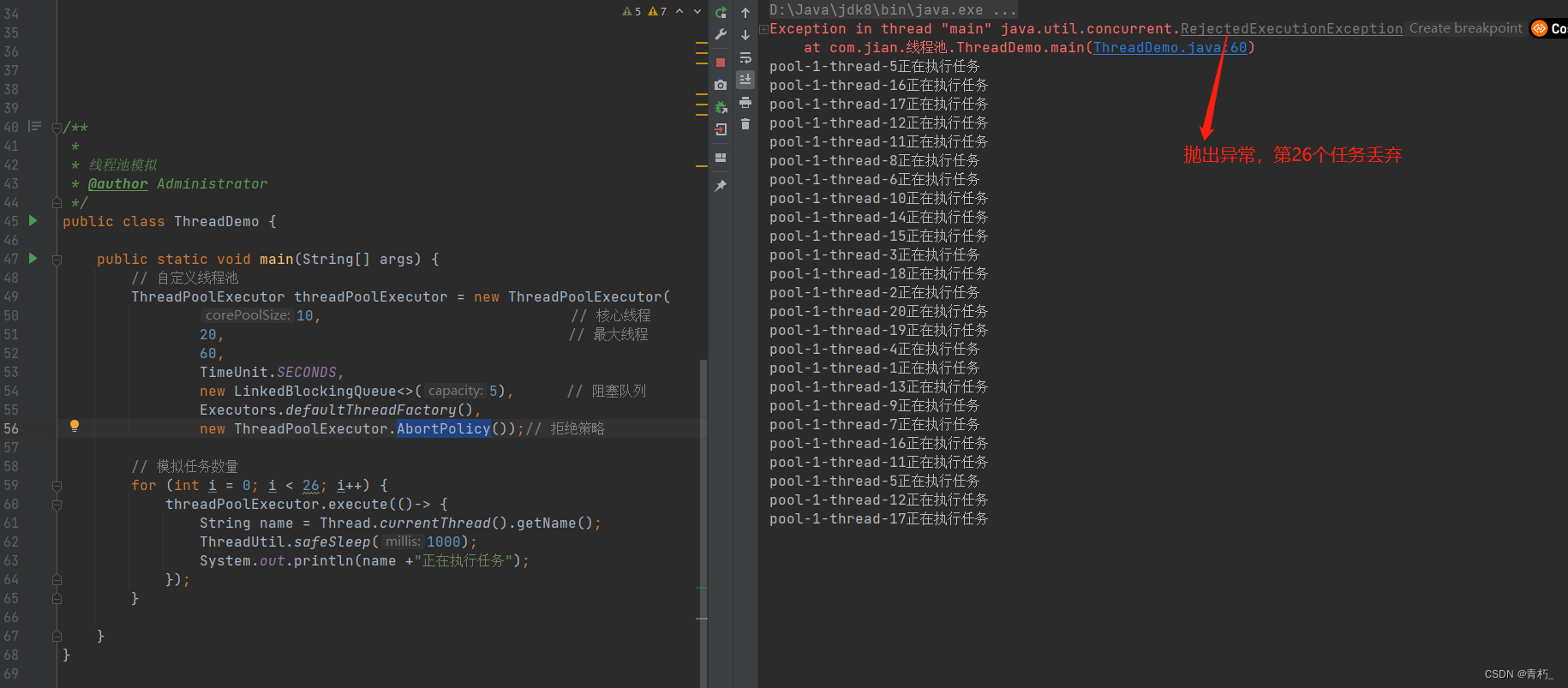
-
DiscardPolicy():丢弃任务,不抛出异常 -
DiscardOldestPolicy():丢弃最前面的任务,执行拒绝的任务
这两种拒绝策略在main方法中不太好体现出来,总之他们都会有丢任务的风险,实际使用中清楚就行。
3.注意点
3.1. 线程池隔离
如果我们很多业务都依赖于同一个线程池,当其中一个业务因为各种不可控的原因消耗了所有的线程,导致线程池全部占满。这样其他的业务也就不能正常运转了,这对系统的打击是巨大的。
比如我们 Tomcat 接受请求的线程池,假设其中一些响应特别慢,线程资源得不到回收释放;线程池慢慢被占满,最坏的情况就是整个应用都不能提供服务。所以我们需要将线程池进行隔离。通常的做法按照业务进行划分:比如下单的任务用一个线程池,获取数据的任务用另一个线程池。这样即使其中一个出现问题把线程池耗尽,那也不会影响其他的任务运行。
3.1. 线程池配置
首先弄清楚IO密集型和CPU密集型:
CPU密集型:占cpu多,非常复杂的调用, for循环次数多,或者递归调用层次很深等等,导致一直使用cpu,这种情况线程池核心数不宜过多,最好等于cpu数量,能充分利用cpu,减少线程切换。建议cpu数+1
IO密集型:读磁盘、读网络、写文件、读写数据库、远程调用接口等业务多,此时cpu占用不太多,读取过程中可能会有很多时间等待,这样把线程数增大,让cpu忙起来,充分利用cpu。建议cpu数*2
混合型:如果IO密集型和CPU密集型的执行时间相差不太大,可以拆分开,以便于更好配置。如果执行时间相差太大,优化的意义不大,比如IO密集型耗时60s,CPU密集型耗时1s。
参考:最佳线程数目 = ((线程等待时间+线程CPU时间)/线程CPU时间 )* CPU数目
实际情况中,最好需要进行一个压测,根据压测的实际情况去配置线程池数量
注意:java中获取cpu: Runtime.getRuntime().availableProcessors();
3.2. 异常处理
在实际开发中,我们常常会用到线程池,但任务一旦提交到线程池之后,如果发生异常之后,怎么处理? 线程池的执行方法中,submit不打印异常信息,而execute则会打印异常信息
方法1:在excute的方法里面,可以通过重写afterExecute进行异常处理,但是注意! 这个也只适用于excute提交(submit的方式比较麻烦,下面说),因为submit的task.run里面把异常吞了,根本不会跑出来异常,因此也不会有异常进入到afterExecute里面。
方法2:try catch
…
3.3. 事务问题
编程式事务或者分布式事务来解决