目录
三、Introduction and Related work
一、前言
本次组会阅读的文献为
C-GCN: Correlation based Graph Convolutional Network for Audio-video Emotion Recognition

二、Abstract
With the development of both hardware and deep neural network technologies, tremendous improvements have been achieved in the performance of automatic emotion recog nition (AER) based on the video data. However, AER is still a challenging task due to subtle(细微的) expression, abstract concept of emotion and the representation of multi-modal information. Most proposed approaches focus on the multi-modal feature learning and fusion strategy, which pay more attention to the characteristic of a single video and ignore the correlation among the videos. To explore this correlation, in this paper, we propose a novel correlation-based graph convolutional network (C-GCN) for AER, which can comprehensively(综合) consider the correlation of the intra-class and inter-class videos for feature learning and information fusion. More specififically, we introduce the graph model to represent the correlation among the videos. This correlated information can help to improve the discrimination of node features in the progress of graph convolutional network. Meanwhile, the multi-head attention mechanism is applied to predict the hidden relationship among the videos, which can strengthen the inter-class correlation to improve the performance of classififiers. The C-GCN is evaluated on the AFEW datasets and eNTERFACE’ 05 dataset. The fifinal experimental results demonstrate the superiority of our proposed method over the state-of-the-art methods.
随着硬件和深度神经网络技术的发展,基于视频数据的自动情感识别(AER)获得了极大的进展。然而,由于细微的表达,情感的抽象概念和多模态信息的表征,AER仍然是一个具有挑战性的任务。大多数提出的方法集中于多模态特征学习和融合方法,这使得研究人员更关注单个视频的特征并且忽略了视频之间的相互关系。为了探究这种相互关系,在这篇文章中,我们为AER问题提出了一个新颖的基于相关性的图卷积神经网络(C-GCN),这种方法可以综合性地考虑到内在类别和用于特征学习和信息融合的内在类别视频。更具体来说,我们引入了图模型来表示视频之间的相互关系。这些相关信息可以帮助我们去改善图卷积项目中节点特征的分歧。同时,多头注意力机制被施加在网络中去预测视频之间的隐藏关系,这可以通过加强内在类别相关性来改善分类的表现。C-GCN在AFEW和eNTERFACE'05数据集上被评估。最终的实验结果超过了SOTA表明我们提出的方法的优越性。
三、Introduction and Related work
Traditional multimodal based methods usually consist of three steps: First, speech signals and video signals are pre- processed, respectively(分别地). For speech signals, a sliding window(滑动窗) is utilized(使用)to extract the sequential features from the raw speech waveform(波形). Face images are detected from a video clip to identify facial components (e.g., eyes and nose) or landmarks(地标). Next, global speech features and facial component features are extracted for multimodal fusion. Finally, features from two different modalities are fused to obtain a fifinal feature vector, which is then fed into classififiers such as support vector machine (SVM) [5] or random forest to produce recognition results.
传统的多模态方法通常包含三个步骤:首先,声音信号和视频信号分别经过预处理。对于声音信号,使用滑动窗从原始语音波形中来提取序列特征。面部图像则从视频夹中被检测到来辨识面部成分(如:眼睛和鼻子)或者地标。然后,全局语音特征和面部组成特征被提取用于多模态融合。最终,两个不同模态的特征被融合以获得最终特征向量,这个特征向量然后放入类似于SVM或者随机森林的分类器来产生识别结果。
In this paper, we propose a novel correlation based graph convolutional network (C-GCN) to address the audio-video emotion recognition problem. Like Fig.1 presented, we aim to exploit the correlations among the videos to shorten thedistance between the video descriptors(描述符) from the same class in the feature space.
在这篇文章中,我们提出了一个新颖的C-GCN来解决声音-视频情感识别问题。像图1表现的那样,我们想要挖掘视频之间的相互关系来缩短特征空间中来自同一类的视频描述符之间的距离。
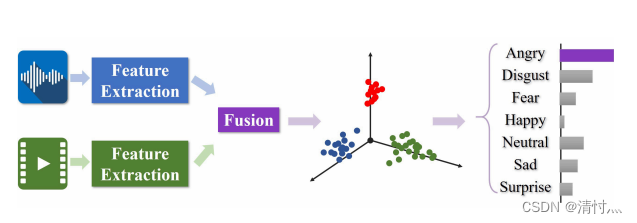
The key steps of our network can be summarized as follows: 1) Feature extraction: audio and visual signals are first preprocessed, respectively. Different models are then separately employed on the audio and visual signals to extract features. The factorized bilinear pooling(因子化双线性池) operation is employed to deeply fuse these multimodal features as a video descriptor. 2) Graph generation: in order to exploit the correlations among the videos, we construct a graph model using the obtained video descriptors as nodes. The original edges of the graph are constructed by the category information and similarity measurement(测量). Then the multi-head attention mechanism is performed on the graph model to generate a set of fully connected edge-weighted graphs for providing more accurate relationship among the videos. 3)Feature updating(更新): based on the multiple(多重的) fully connected edge-weighted graphs, to fully consider the relations between videos, we apply the classic attention-GCN model to produce the node embedding. For each video, we fifinally fuse multigraph information by mean-pooling operation to obtain the unique embedding for the emotion classifification.
我们网络的关键步骤可以总结为如下几点:1)特征提取:音频和视觉信号首先分别被预处理。不同的模型分开被应用到音频和视觉信号来提取特征。使用因子化双线性池操作深度融合这些多模态特征作为视频描述符。 2)图产生:为了挖掘视频之间的相互关系,我们将获得的视频描述符作为节点构造了一个图模型。图的原始边是由类别信息和相似测量构造的。然后,多头注意力机制被运用到图模型中来产生一个完全连接的边缘加权图的集合,用来提供视频的更精准的关系。 3)特征更新:在多重全连接边加权图的基础下,为了更能考虑到视频之间的相互关系,我们应用了经典的注意力-GCN模型来产生节点嵌入。对于每一个视频,我们最终通过平均池化操作的多图信息来获得用于情感分类的独特嵌入。
The contributions of this paper can be summarized as follows:• We propose a novel correlation based graph convolutional network (C-GCN) to address the emotion recognition problem, which can comprehensively consider the corre lation among the videos based on the constructed graph model;• We utilize multi-head attention mechanism to generate a set of fully connected edge-weighted graphs, which aims to predict the hidden relationship between the inter-class videos and guarantee the graph embedding performance;• We validate(证实)the effectiveness of our method on the AFEW dataset [4] and eNTERFACE’ 05 dataset [15]. Several current effificient methods are used for comparison in the experiments. The fifinal experimental results demonstratethe superiority of our approach.
这篇文章的贡献如下所示:
· 我们提出了一个新颖的C-GCN来解决情感识别问题,它可以综合地考虑到基于结构化图模型的相互关系。
· 我们使用多头注意力机制来产生全连接边加权图,这可以帮助预测在内在类型视频的隐藏关系和保证图嵌入性能。
· 我们在AFEW和eNTERFACE'05数据集上证实了我们方法的有效性。各种通常有效的方法在实验中与我们的方法进行对比。最后的实验结果表明我们方法的优越性。
四、Proposed Method
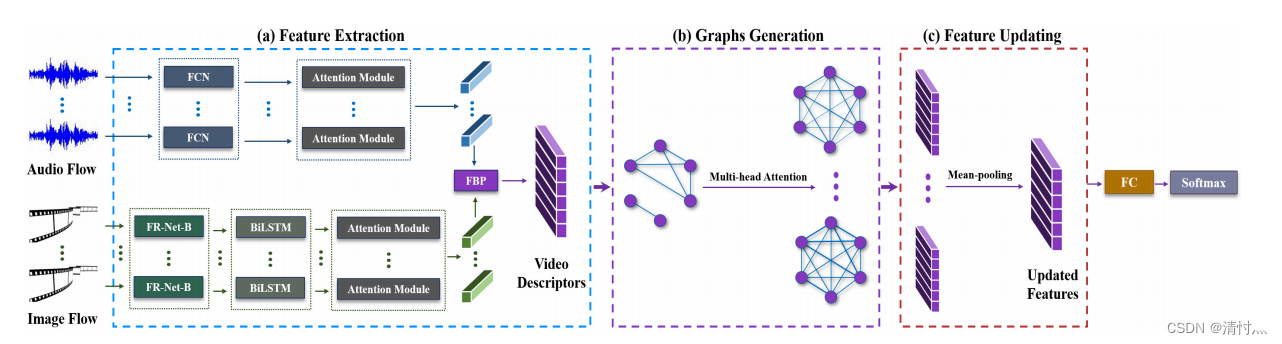
Fig. 2. Overview of the correlation based graph convolutional network. The audio and visual signals are fifirst preprocessed and then fed to different networksfor the feature extraction. The extracted features are fused to obtain the video descriptors, as shown in (a). Then, the video descriptors are used as nodes to construct the graph model and multi-head attention is employed to exploit the correlations among the videos in (b). Finally, in (c), the node features are updated by graph embedding technique. To obtain an unique feature vector for each video, the updated node features from multiple graphs are integrated by the mean-pooling operation to obtain the fifinal updated features for the emotion classifification.
C-GCN的整体架构。如(a)所示,声音和视觉信号首先被预处理然后放在不同的网络中用于特征提取。然后,视频描述符作为节点来构造图网络并且多头注意力被运用来挖掘视频中的相互关系。最终,节点特征通过图嵌入技术不断更新。为了获得每一个视频的独有特征,多重图的节点特征通过平均池化被整合以获得最终的特征用于情感分类。

Fig. 3. Illustration of the feature extraction process on the audio flow.
音频数据的特征提取

Fig. 4. Illustration of the feature extraction process on the image flflow.
图片数据的特征提取

Fig. 5. Illustration of the factorized bilinear pooling operation.
因子化双线性池
五、Conclusion
We introduce the novel multimodal method correlation based graph convolutional network (C-GCN) for audio-video emotion recognition. Experimental results show that C-GCN achieves state-of-the-art results on two public datasets. Unlike previous approaches, C-GCN employs graph structure and multi-head attention mechanism to mine the intra-class and inter-class correlation among the videos for feature learning. By utilizing this correlation information, C-GCN improvesthe discrimination of video descriptors to boost performance. There are multiple venues(场景) for future work. Because mul timodal information and graph convolutional networks are important for this work, it is natural that we will try to model the interaction and capture the correlation between different modalities by employing graph convolutional networks in the emotion recognition task.
我们介绍了用于音频-视频情感识别的C-GCN。实验结果表明C-GCN在两个公开数据集上获得了SOTA结果。不同于前面的方法,C-GCN运用图结构和多头注意力机制来挖掘内在类别和用于特征学习的视频内在相关性。通过利用这种相关信息,C-GCN改善了视频表示符的分歧性以加强表征。今后的工作会用于多个场景。因为多模态信息和图卷积网络在此任务中十分重要,所以我们将会在情感识别任务中运用图卷积网络来捕捉不同模态的相关性。