上一篇文章其实已经详述了模型训练到部署的整个流程,但是数据集到模型都是用的官方的coco数据集,这里为了记录开发板的模型训练到部署的整个流程,重新开了一篇文章进行记录。
首先准备数据集和rockchip官方推荐的yolov5源代码

这里需要注意的是数据集中的标签文件内容 一行只能有5个数,分别是类别和(x,y,w,h)
但是我平时用的labelimg.exe 生成的xml文件转化为txt标签文本文件后 一行有6个数,分别为类别,(x,y,w,h),以及置信度,这里需要做一下转换。
然后需要将coco/yaml128.yaml配置文件中的部分参数做一下修改 主要是训练类别数和训练类别名称

一般做目标检测(比如我)只做一类检测,这里需要将类别数改为1,并将类别标签改为实际的标签名。
接下来就是训练模型,在yolov5-master路径下,键入命令
python3 train.py --data coco128.yaml --weights '' --cfg yolov5s.yaml --img 64
该命令的意思是读取coco128.yaml配置文件里面的数据集路径和类别数、类别名,模型架构为yolov5s,也就是small版本的模型,考虑到开发板的性能,所以这里选择的是small版本的模型,然后重新训练模型。训练模型完成后,需要将模型进行转换,转换为onnx模型。
这里需要将model/yolo.py文件某个部分进行修改,才能正确的将pt模型导出为onnx模型。
注:训练时不需要修改该部分代码 导出模型时需要修改该部分代码
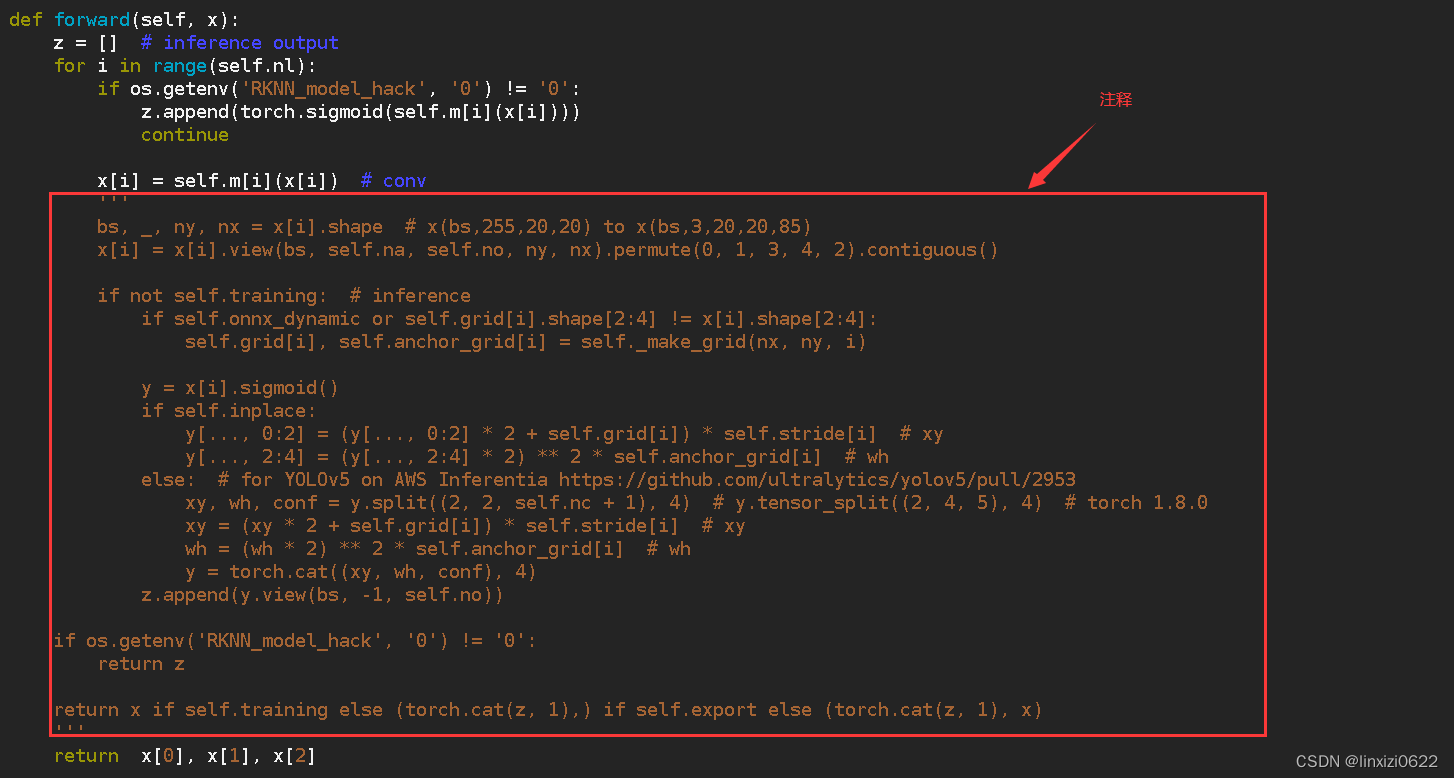
椭圆处是需要注释的部分。
在yolov5-master 主目录下,键入命令
python3 export.py --weights yolov5s.pt --img 640 --batch 1 --opset 12 --include onnx
可以将pt模型转化为onnx模型。将转化后的onnx模型拷贝出来。
接下来在已经安装rknn-toolkit的虚拟机上,对onnx模型进行转换。
首先采用Netron.exe软件打开转化好的onnx模型查看其网络结构
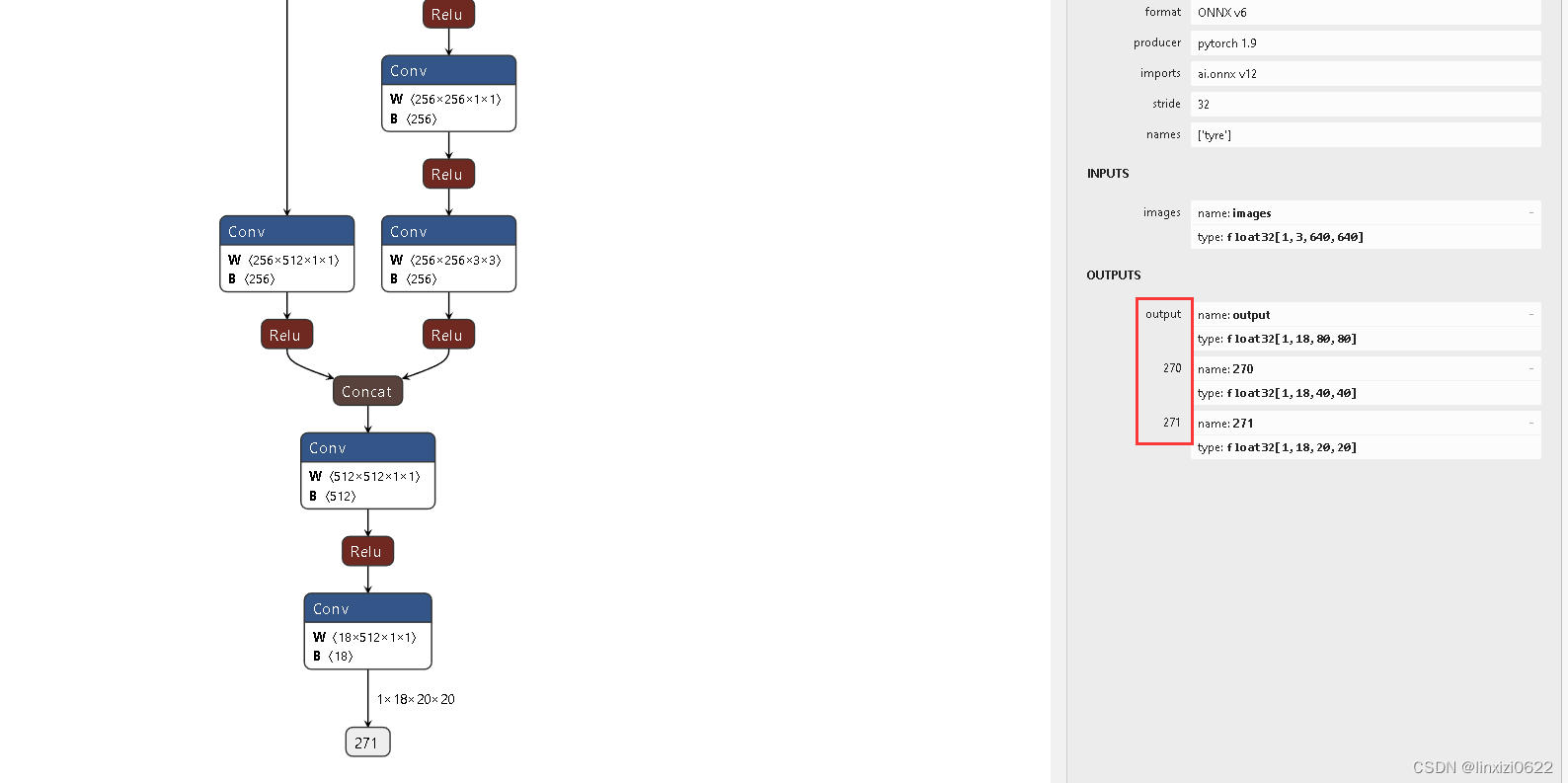
并记下其三个输出的标号。
然后将onnx模型拷贝到/home/rock/workspace/rknn-toolkit2-1.4.0/examples/onnx/yolov5 这个目录下。
该目录下的test.py是瑞芯微官方已经写好的demo文件。
我在这里类比test.py写了一个onnx2rknn.py ,功能与test.py差不多,只是少了连板推理部分。
注意需要在onnx2rknn.py文件中做部分修改

修改完成后,键入命令 python3 onnx2rknn.py文件,正常情况下会生成一个rknn结尾的文件。
接下来将该rknn文件拷贝到开发板上的对应目录下,我这里是
/home/rock/software/rknpu2-main/examples/rknn_yolov5_demo/install/rknn_yolov5_demo_Linux
相对于原始文件,这里我们需要修改如下几个部分:
- 需要在源代码中修改类别数
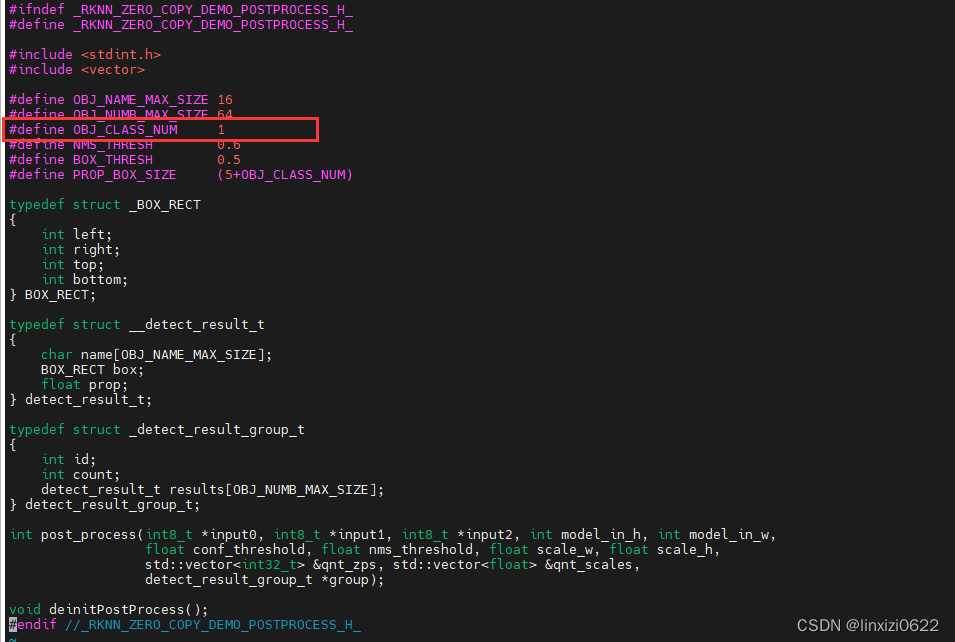
- 需要在配置文件中修改类别数

配置文件一共有两个,如上图所示。
我这里将配置文件里面的类别数修改为我自己的类别数

然后在开发板重新编译,键入命令
sh build-linux_RK356X.sh
然后进入 install/rknn_yolov5_demo_Linux/ 路径下,去执行可执行文件
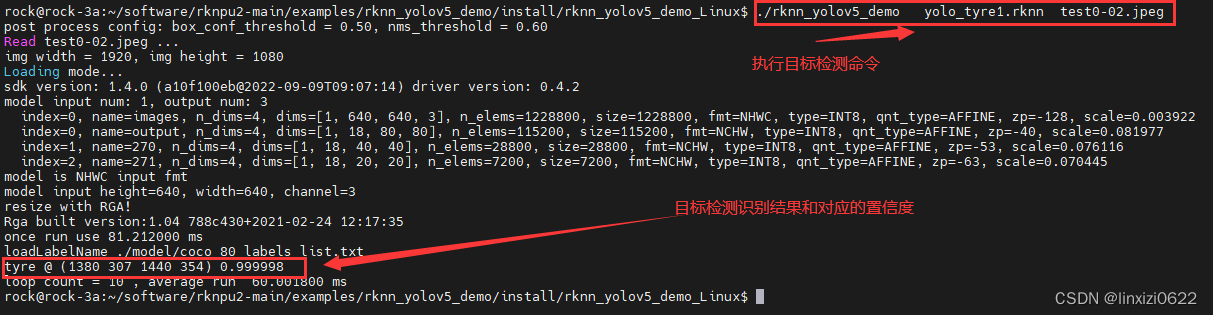
这里说一句:
模型训练初期和模型多次迭代后,其运行速度是不一样的。
实测,当模型开始迭代时,运行一次目标检测耗时大约120ms,当模型迭代300个epoch时,运行一次目标检测耗时60ms,这其中的原因不得而知,如果有大佬知道的欢迎讨论
到此为止,基于自建数据集的模型训练到模型转化,模型部署已经搭建完毕。