代理池说明
在进行网络爬虫开发时,我们经常需要使用代理来隐藏我们的真实 IP 地址,防止被目标网站封锁。然而,公共代理 IP 的速度和稳定性往往难以保证,会给我们的爬虫开发带来很大的麻烦。因此,自己搭建一个稳定的爬虫代理池是非常必要的。
Spider-Project 是一个 Python 编写的网络爬虫项目,其中包含了一个自建优质爬虫代理池的实现。通过爬取一些常见的代理网站,该代理池可以自动更新代理 IP,并通过测试筛选出速度快、稳定可靠的代理 IP,供我们的爬虫使用。
该代理池使用了 Flask 框架实现了一个简单的 Web 服务器,可以通过 HTTP 接口获取代理 IP。同时,代理池还支持了多线程和多进程的方式,可以同时处理多个爬虫请求,提高了代理池的并发性能。
除了代理池,Spider-Project 还包含了一些常见网站的爬虫实现,如淘宝、豆瓣、知乎等。这些爬虫的实现方式简单、易懂,适合网络爬虫初学者学习和使用。
总之,Spider-Project 是一个非常实用的网络爬虫项目,尤其是其中的自建优质爬虫代理池功能,可以让我们更加高效地进行爬虫开发。如果您对此感兴趣,可以访问该项目的 Github 主页,了解更多详细信息。
项目地址:https://github.com/w-x-x-w/Spider-Project
如果有帮到你。希望你可以点一个star
以下是爬虫代理池的简要介绍:
程序说明:
项目运行后,
一个进程去爬取网页代理存入redis,
四个进程去随即检测redis中的代理,进行评分(数量可修改,评分规则可修改)
一个进程运行flask框架,提供接口
评分规则说明
初始规则
入库初试分数为50,检测时连接成功直接为100,失败每次减30,分数小于0从数据库中删除,
接口说明
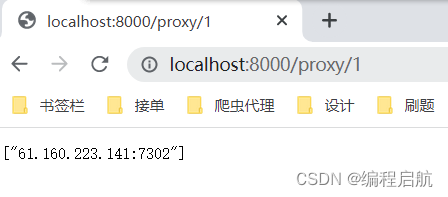
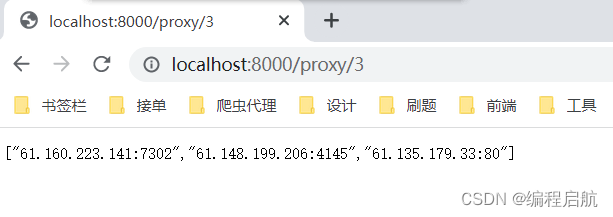
获取前n个100分代理:
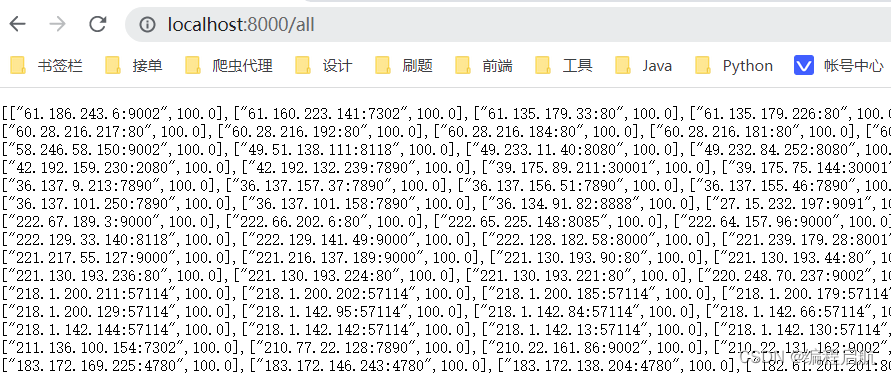
获取所有满分代理:http://localhost:8000/
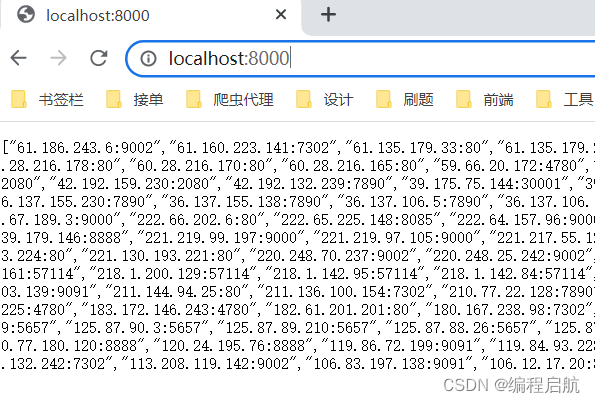
获取所有代理:http://localhost:8000/all