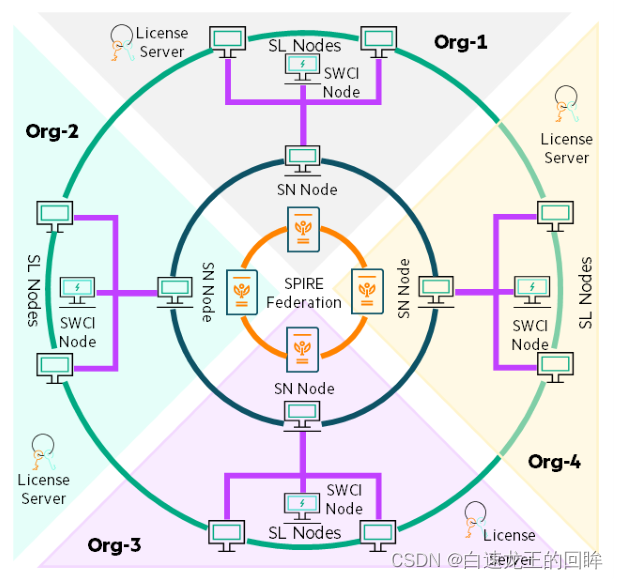
先上一幅Swarm Learning 的架构图镇楼
引文114 An Incentive Compatible Reputation Mechanism(worker直接博弈)
我们想干什么?
我们希望实现激励的可协调,也就是让每个节点可以可信地分享reputation的信息
我们引进可转移支付方案,让节点可信地共享reputation信息
我们还通过密码学的方法整合reputation信息
目前的一些问题
1.如果节点报告reputation信息,别人就会掌握有利的信息,从而对自己不利
2.如果反馈真实的正反馈reputation,节点会由于其余节点的average降低自己的reputation,同时也造成了对稀缺资源的更多需求(我的理解是:reputation比较高的话,别人会认为这个节点可靠,从而向其进行交易需求等)
3.如果反馈虚假的负反馈,节点可以增加自己的reputation,同时减少对稀有资源的需求,所以大家倾向提供虚假信息
我们的目标
我们希望设计一个博弈论模型来让一个理性的节点愿意去分享真实的reputation信息
模型设计
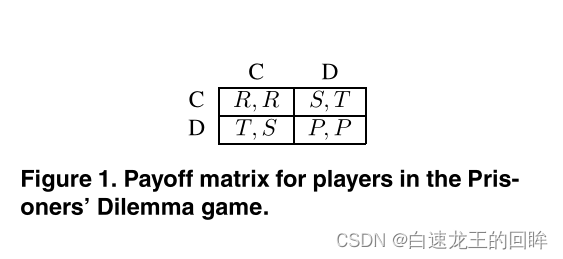
祭上一个囚徒困境的图
我们希望让每一个节点觉得报告真实的信息是有利益的
在我们的机制中,我们引入一个R-agents,负责购买和销售reputation 信息
在博弈游戏中,两个节点要么选择合作要么选择欺骗
游戏双方开始游戏前可以协商合同,但合同不具备强制性
一个节点的行为预测怎么量化?
1.先验类型(固定的概率) =》 innate
2.这个节点的前k次动作 =》 mood
DEF 1
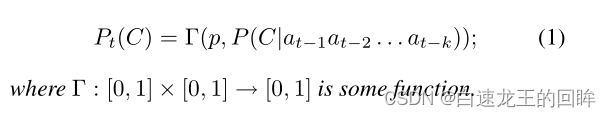
这里的意思是在时间t某个节点何合作的可能性公式
关于R-agent
每个节点可以从R-agent处以F的价格买reputation信息,也可以以F‘的价格卖reputation信息
节点只能够卖出一些它们买入的其他节点的reputation信息
当两个节点要开始游戏前,它们需要支付给R-agent钱来询问对方的reputation
注意,买reputation的钱和游戏中获得的钱不通用
如果一个node用完了它买reputation的钱,就不能再买
完整的流程
1.两个节点随机组合
2.通过R-agent询问reputation
3.决定是否玩游戏
4.若同意玩,进入协商合约阶段
5.若同意合约,开始玩游戏
6.游戏中,可以记录对方的信用,从而生成报告给R-agent
为什么说是激励可协调的呢?
因为我们的支付函数可以诱使节点公布诚实的reputation信息
由于我们不能保证从R-agent那里获取的reputation的正确性,我们的支付函数依赖于未来的情况
payment function的定义

小s是A对B的report
大S是后续其他节点的B的reports
他可以证明,如果A说真话(真实的s)可以使得它的收益最大化
TH1
若节点的gamma函数不依赖于之前的actions,那么没有支付函数可以有效诱使诚实的行为
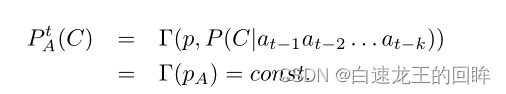
由于A的诚实概率(reputation)不受之前行为的影响,所以是恒定的
所以它的大S(未来的reports)可以认为和目前是完全一致的S = Sc = Sd
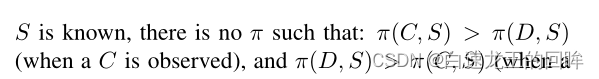
因此说真话肯定不可能总是有好处
这个要看pi(C,S) and pi(D,S)的大小决定~
这个结果令人震惊,因为很多reputation系统都是只关注先验类型对行为的影响
我们的一个想法
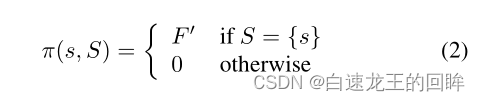
R-agent只有当下一次关于B的report:S和之前A的report:s相同的时候,才会支付给A报酬F’
TH2
如果满足Def1和Eq2,那么报告真实的reputation信息就是一个纳什均衡
which means, 如果下一个节点讲真话, ‘我’也最好讲真话
概率证明:B在连续两次动作中采用相同的概率大于等于0.5
这个Eq2只能保证系统前期交互的安全的
还有一些问题:Eq2中的支付函数需要引入一些节点行为参数才可以保证长期稳定~~
Th3
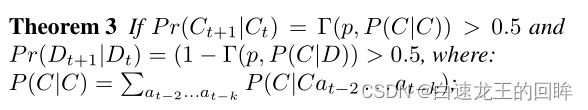
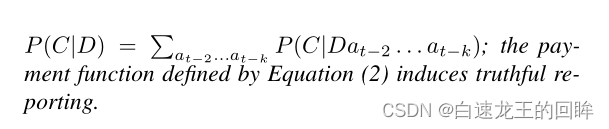
两个概率指的是假设连续在t时间干了X行为的条件下t+1时间还是保持X行为的概率是大于5成的话
Eq2总会诱使它们交出真实的reputation报告

条件:A观察到B是正常的合作
如果它诚实报告1的收益期望就是E[pi(1,S)]
然后根据B下一次可能的行为展开条件概率求和就可以得到一头一尾
注意:我们假设下一个汇报B者是诚实的
小结:让节点都倾向说真话
我们这里采用两阶段假设和证明,表明了在模型的前期和后期都会让各个节点倾向于说真话
引文114的一些问题
R-agent变成blockchain node可行吗?(负责买卖?不能以明文记录reputation)
分开game 的money 和reputation的money有什么好处?
引文74 结合reputation和契约理论的中心化激励(reputation由task publisher整合)
主要工作
1.worker selection based on reputation可防止不可靠的模型更新
2.使用多权重主观逻辑模型计算reputation然后用联盟链存reputation
3.基于契约理论的激励机制促进高reputation的worker拥有高quality数据来参与训练防止攻击
4.实验表明这个方案很好很精确。。。
基于联盟链的可信联邦学习模型图
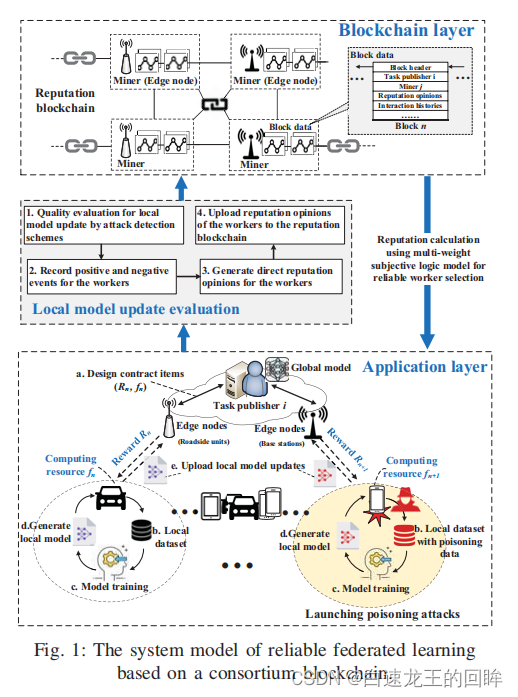
worker:本地数据集、本地模型训练、生成本地模型、计算资源Fn
task publisher:分配task、计算每个worker提供的模型质量、生成reputation、reputation上链
reputation是评估worker可靠性的重要因素:综合direct reputation和在链上记录的最近几次的indirect reputation计算
step1: task publishers发布FL的任务和合约条款,有相关的数据类型、大小和精确度、时间和CPUT的要求。如果workers觉得可以满足就加入任务,然后给予回应给task publisher
step2:基于direct的reputation和存在链上的indirect的reputation得到综合的reputation;reputation的计算是某种加权平均(交互的效果、交互的新鲜度 =》 direct)(跟其他recommender的worker相似度 =》 indirect)
step3:选出reputation大于某个阈值的作为worker,worker根据他们的条件选择一个最优的合同项进行签署
step4:开始进行FL,然后评估各个worker更新的本地模型
通过两个攻击检测算法评估模型
1.Reject on Negative Influence(RONI)投毒检测方案(IID),通过比较包含和剔除某个本地模型,如果加入这个本地模型后,总体表现下降超过一定阈值,则拒绝这个本地模型
2.FoolsGold方案(non IID)通过某个本地模型的梯度更新差异来识别不可靠的worker,由于non-IID 的梯度变化遵循一定的分布函数,如果worker重复上传相似度高的梯度就会被检测出来
基于上述两个方案,task publishers可以移除不可靠节点,然后用联邦平均更新模型
训练完成后,每个可靠的worker根据之前签订合约中的内容,获取与资源贡献和模型训练行为对等的奖励
恶意节点的交互会被task publishers记录下来
step5:更新联盟链中的reputation,task publishers更新direct的reputation,这些reputation会被workers数字签名从而不可抵赖(应该是合约中签订的),然后这些reputation提供给以后的task publishers作为indirect参考
对可靠的FL的激励机制
原则:鼓励high-reputation high-quality data的worker加入模型训练
task publisher 发放 reward 的困难
1.task publisher 由于缺乏先验知识并不知道哪些worker希望加入到训练中
2.对于task publisher而言,worker的reputation和data quality是未知的
3.task publisher也不知道worker的可用计算资源和数据量
1、2、3 =》 task publisher在给worker激励的时候会有太多的消耗
因此,本文设计了基于契约理论的激励机制
A:worker在一次迭代中的CPU消耗
B:worker在一次迭代中的通信消耗
C:worker按照数据质量进行分级
D:task publisher对type-n worker一次迭代花费时间的满意度函数
因此,由于有了契约理论,恶意节点是不会签署比他等级要高的合约的(否则拿不到奖励)
从而也可以激励高质量的节点加入FL中
引文74的一些问题
reward min?max?sum?(worker应该怎么选择合同签署,具体奖励如何分配?)
pre-set reward 放到 smart contract可行吗?(pre-set reward指的是契约中约定的奖励)
合约里面包括digital signature?(让reputation绑定具体的worker)
每个等级的合同的钱怎么设计?(不同数据质量的奖励梯度如何划分?)
一开始的reputation不确定,worker selection都是基于一定的reputation基础的(初始阶段怎么判断?)