ECANet笔记
ECANet的贡献
发新问题、分析问题、解决问题
1、发现问题:
分析SENet,经过全连接层进行降维,破坏了通道与注意力之间的直接对应关系。(研究表明,降维会给通道注意力预测带来副作用,并且捕获所有通道之间的依存关系效率不高且不必要。)
2、分析问题
设立3种对比实验进行验证;
第一种变体Var1,添加通道注意力机制,但删除了全连接层。对特征图进行全局平均池化,然后进行Sigmoid激活,作为特征图的的权重信息,如下图(粘贴自B站大佬渣渣的熊猫潘)。

第二种变体Var2,改变SE模块中的两层全连接层,仅使用 C C C个参数,将 1 ∗ 1 ∗ C 1*1*C 1∗1∗C的特征权重处理成 1 ∗ 1 ∗ C 1*1*C 1∗1∗C的特征权重,然后再经过Sigmoid激活。如下图(粘贴自B站大佬渣渣的熊猫潘)。

这一步可以通过很多种方式去实现,可以利用卷积核为 1 ∗ 1 1*1 1∗1的深度卷积实现。
第三种变体Var3,利用一层全连接层实现特征权重之间的跨通道交互。如下图(粘贴自B站大佬渣渣的熊猫潘)。

通过上述3种变体方式进行对比实验,分析不同变体对模型性能的提升。

通过实验结果可以看出,变体Var1仅使用了池化后的特征作为权重信息,效果要优于未添加注意力的时候,因此,可以证明,添加注意力机制对模型性能提升是有作用的。但效果没有SE效果好。变体Var2添加了一一对应的参数,让通道与特征权重之间保持了一一对应的关系,效果要优于SE模块的两层全连接层,证明了通道与特征权重之间的直接对应关系,SE模块中通过降维实现的非线性关系会破坏通道与特征之间的对应关系,影响注意力模块的效果。
注意
通过Var2与Var3比较,证明了有通道交互效果要优于Var2无通道交互的情况。

通过上图可以看出,Var2中无通道交互,参数量少,仅有 C C C个参数,Var3中有通道交互,但参数量多 C 2 C^2 C2个参数。且有通道交互时,对模型提升更大。
Var2与Var3中和效果实验

作者提出,能否有一种可能的方式既能实现通道交互,又能实现参数量减少呢。于是作者考虑到用深度可分离卷积或者分组卷积的方式去进行实验。

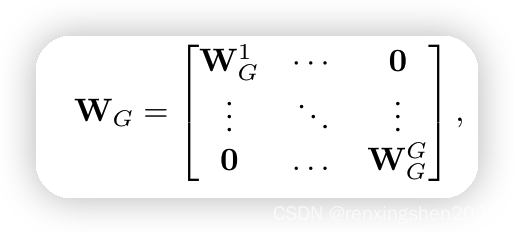
首先利用分组卷积的方式将 C C C个通道进行分组,原文中分成了16组,也就是 G = 16 G=16 G=16,每一组,这个每个组有 ( C / G ) 2 (C/G)^2 (C/G)2个参数,然后有 G G G个组,因此,参数量为 ( C / G ) 2 ∗ G = (C/G)^2*G= (C/G)2∗G= C 2 / G C^2/G C2/G。这样大大减少了参数量。
但这种方式并没有表现出比Var2更好的效果,因此,通过分组卷积的方法并没有带来很好的通道交互效果。(组内通道交互,但组之间没有通道交互。)(为什么不好?)
第二种方法:
提出一种跨通道交互的带状矩阵。每组K个神经元,依次往后移动一个。

分析:带状矩阵的运算是不是类似于一位卷积,那如果用一维卷积是不是参数量更少?
参数量削减了,也有了通道交互
但一维卷积的大小还没有确定…………
确定卷积核大小
卷积神经网络随着深度的增加,特征图通道数也成2的幂次方增长,如果卷积核大小是一个固定的值,貌似也不合理。于是:


然而,特征图通道数通常为2的幂次方,所以:

因此,K值可以通过以下公式求得:

论文中,作者给出了gamma=2,b=1。最后K取奇数值。代码如下:
代码

最后
ECANet从发现问题,分析问题,解决问题的角度出发,提供了非常好的研究思路值得学习。
ECA模块也是即插即用的模块,且在使用时一般都可以提点。
如有错误,请大家指正。