Gartner是全球最具权威的IT研究公司,在IT研究领域可以说是无人不知、无人不晓。它每年都会发布各种IT产业评测报告,分析未来技术发展,帮助客户进行市场分析、技术选择、投资决策,我也会经常地去看一看。
最近看到了Gartner发的云数据库魔力象限报告,这也是业内最严苛的厂商综合能力评估,能进入这个名单的就是实力的体现。
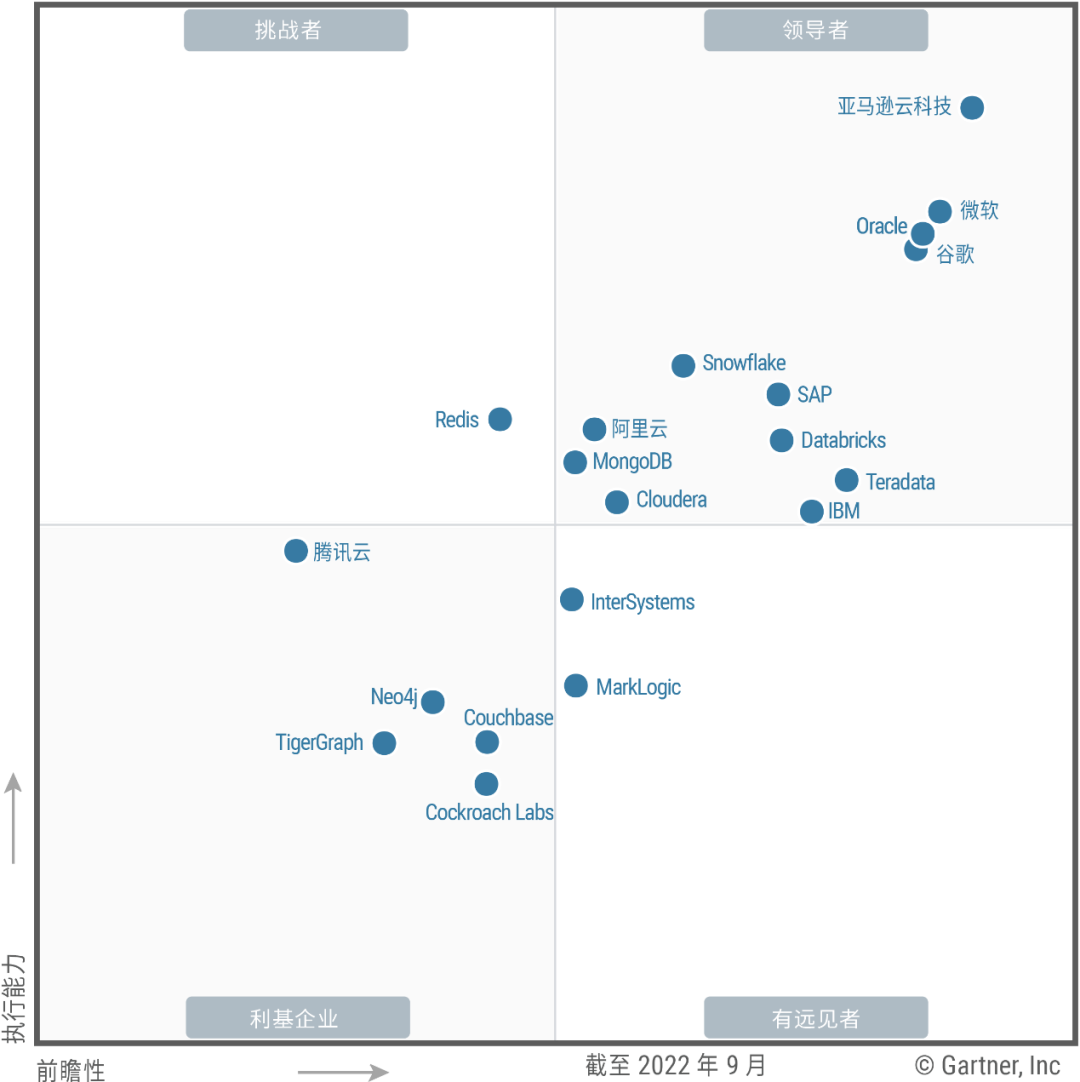
不出所料,亚马逊云科技又是一骑绝尘,这也是它连续八年当领导者了。
这我并不惊讶,因为亚马逊云科技的云数据库确实有很多领先行业的特性,我之前的文章也介绍过,例如实现极致弹性,随需而变的Serverless,都是亚马逊云科技率先提出来并实现的。
值得注意的是,相比前几年的报告,亚马逊云科技的位置又“向上”,“向右”挪动了不小,也就是变得更有远见,执行力更强,说遥遥领先一点儿也不为过。
有远见说明站得高,看得远,执行力强说明能把想法落地,而不是停留在PPT上。
这么说太抽象,我给大家举两个例子就明白了,一个是“真正的极致高可用数据库”,另外一个是 “与底层硬件集成优化的数据库”。
1
真正的极致高可用数据库
大家知道云计算为了描述数据中心的位置,一般会分成区域(Region)和可用区(AZ,Availability Zone)。
Region是为了方便用户就近接入,降低网络延迟,比如我的应用部署在北京Region,那肯定方便国内客户,部署在美国Region,那就是方便美国用户访问。
在一个Region内有多个AZ,AZ简单说就是一个/多个物理数据中心的集合,AZ之间一般相距100公里之内,有高速网络相连。
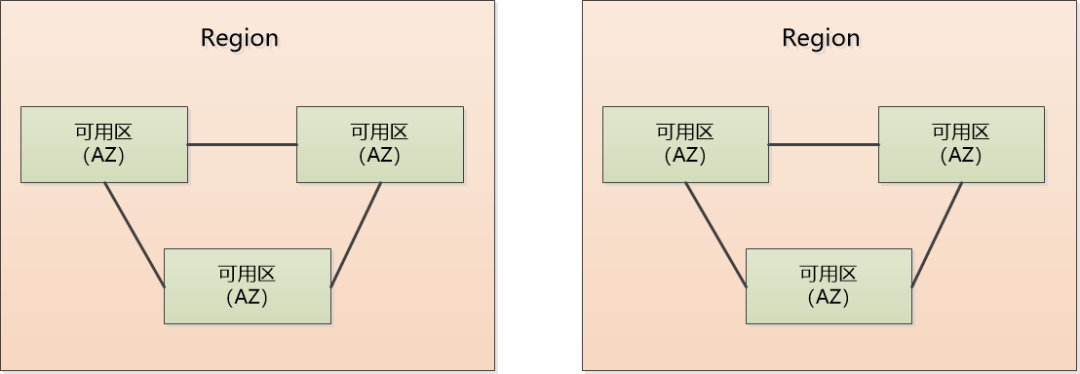
为了提高可用性,应用程序和数据库可以部署在一个Region的多个AZ中。这样一个AZ突然断电了,还有别的AZ可以工作,应用程序还能运行,高可用性能做到这一步已经不错了。
假如我的生意做大了,要跑到全球去做买卖,为了让全球用户都有良好的访问体验,也为了容灾(万一某个Region地震了……),应用程序和数据库也得部署到全球不同Region当中。现在问题来了,这些在不同Region中的数据库怎么保持一致呢?怎么实现一写多读呢?
当然可以让自家技术团队去实现一致性,但是技术挑战很大,后续的运维想想就头大。
亚马逊云科技很早就意识到了这个问题,在三四年前开发了一个Global Database的功能把它解决了。
使用Global Database,只需要在控制台配置一下,就可以自动地在多个Region之间复制数据,保持数据几乎实时同步(延迟小于1秒)。
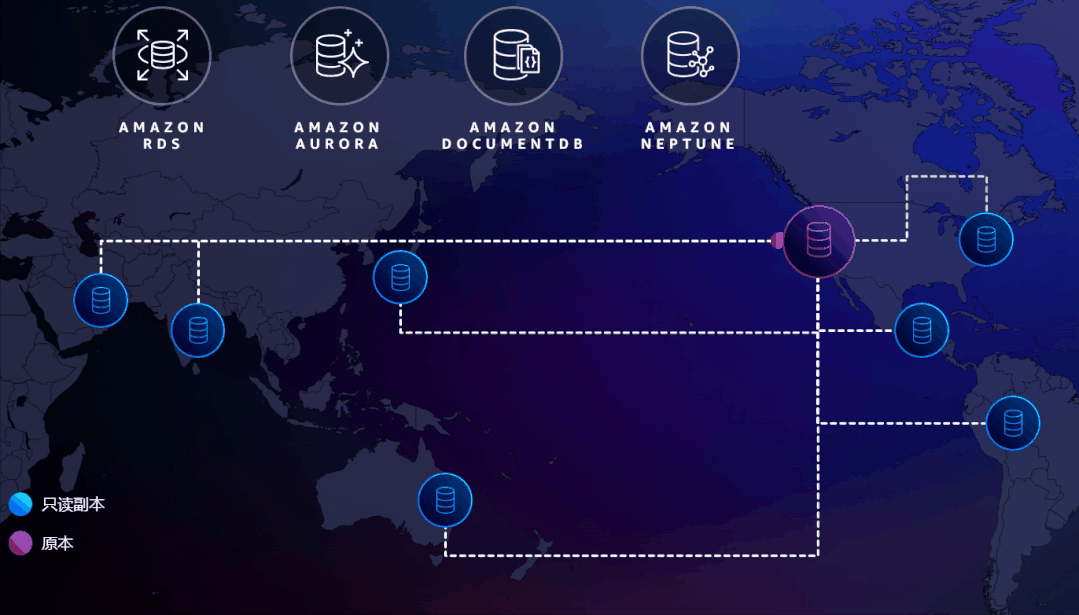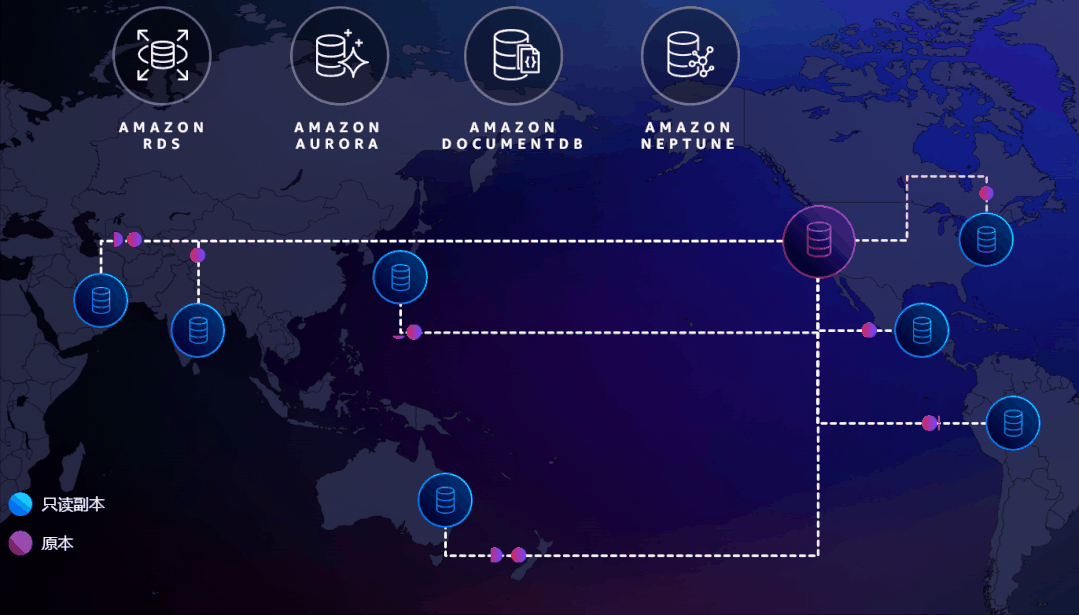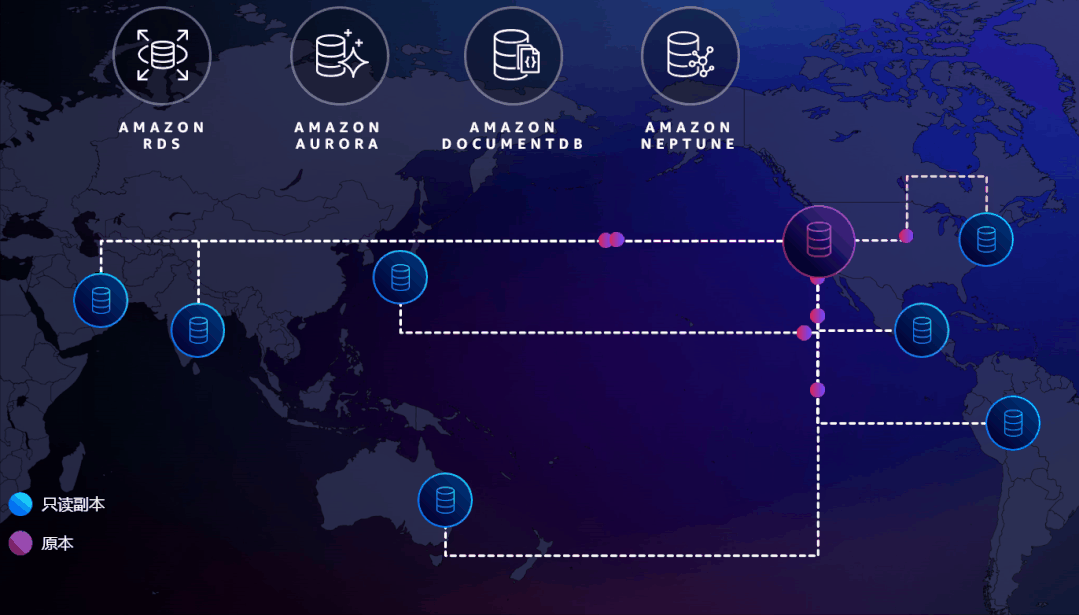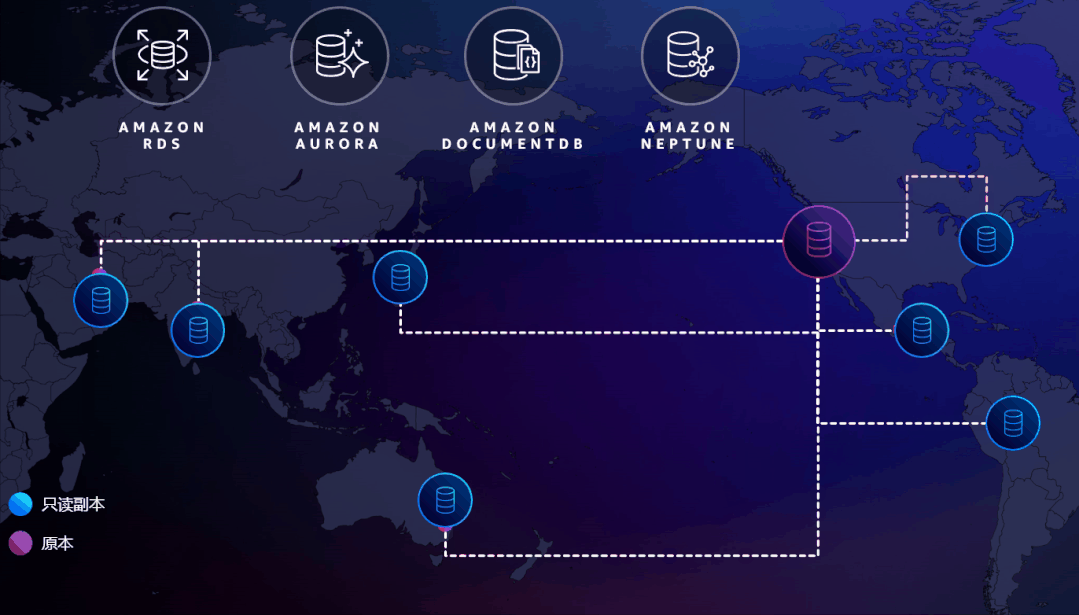
图中数据库被部署在全球的各个Region,红色的为主数据库,可读可写。蓝色的是部署在其他Region的只读副本。如果主数据库挂掉了,可以轻松地把其中一个提升为主数据库。
这其实就是个跨越全球的读写分离,除非整个地球都完了,否则总会有一个数据库是活着,应用总是可以提供服务的,这才是真正的极致高可用!
2
与底层硬件集成优化的数据库
现在数据库有个重要的发展方向就是和硬件紧密集成,比如TeraData的大数据一体机,在硬件,操作系统,存储等方面专门为数据分析做了优化,性能自然强大。
这些专有硬件必须得单独购买才行,有没有一种方式把它变成云平台的服务,成为一种普遍的能力,让所有人都受益呢?
这里不得不提一下Amazon Nitro系统。大家可以想想,虚拟机是怎么实现的,本来只有一套硬件,怎么能在上面模拟出多套隔离的虚拟机呢?
魔法就是实现虚拟化的软件,例如VMWare, Xen,这些“大管家”软件可以把底层的硬件资源进行分割,让各个虚拟机使用。
但是既然“大管家”也是软件,那运行起来必然也有开销,也需要占用CPU、内存、硬盘,相当于自己占用了一部分物理资源,它占用得多了,各个虚拟机能分的就少了。并且虚拟机访问存储、访问网络的时候也得通过Xen这样的“大管家”中转,效率很低。
Amazon Nitro系统实现了一个非常非常轻量级的“大管家”软件,然后把其他的事情都用专有芯片给硬件化了,例如负责网络的VPC卡、远程存储EBS卡、本地存储卡、控制器卡和安全芯片等。这样一来,原来需要耗费资源的软件开销都被卸载到了硬件平台,用户可以获得全部底层物理机的资源。不仅如此,专用的 Nitro 卡可实现高速联网、高速 EBS 和 I/O 加速,可以做的事情就太多了。
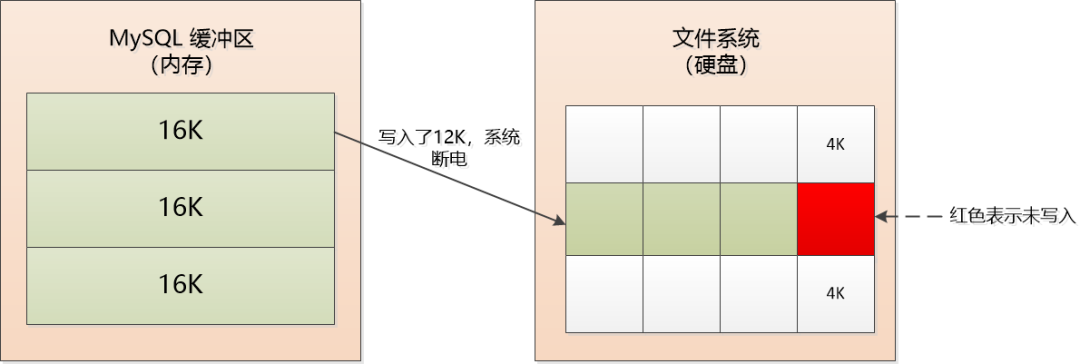
回到我们正在聊的数据库,MySQL有个经典的面试题:Double Write Buffer, 说的是MySQL缓冲区的数据页是16 Kb,文件系统的页通常是4 Kb,它们两个不匹配。
当MySQL缓冲区的16 Kb的页需要写入文件系统时,需要分4次才行,那自然会出现类似这样的问题:写了3次以后掉电了,那最后4 Kb的数据就丢失了。
MySQL的解决办法很粗暴,在硬盘上开辟一个2M的文件缓冲区,内存中缓冲区的数据在写入真正的数据文件之前,先写入这个文件缓冲区,写成功了,再往真正的数据文件去写。
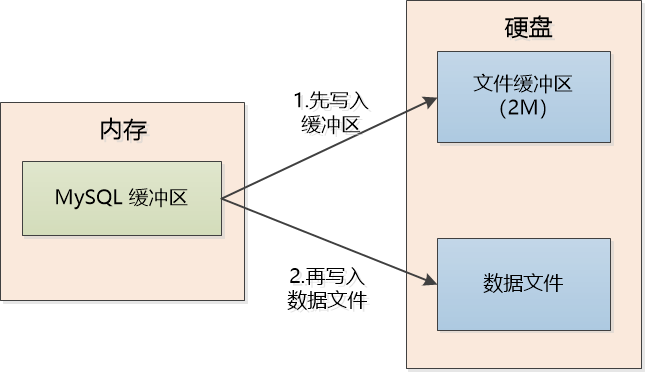
(简化的示意图,实际上在内存中还有一个缓冲区)
这样再出现写入12 Kb就断电,真正的数据文件中虽然还是有4Kb是丢失的,但是可以从那个2M的文件缓冲区找到原始数据进行恢复,因为那里写成功了,是完整的。
由于需要往硬盘写入两次,所以叫做Double Write,这个办法虽然可以工作,但是说实话,挺别扭的,因为断电这种极端情况很罕见,绝大部分时间这个2M的文件缓冲区没用,白白多写了一次硬盘,要知道硬盘速度可比内存访问慢多了。
我们很容易就会想到:就不能把MySQL缓冲区的16 Kb数据一次性地写入硬盘吗?这样不就省事了吗?
通过使用Amazon Nitro系统中的Torn Write Prevention技术,亚马逊云数据库实现了优化写入数据,只需一步即可安全写入 16Kb 数据页,完全不用复杂的Double Write了。
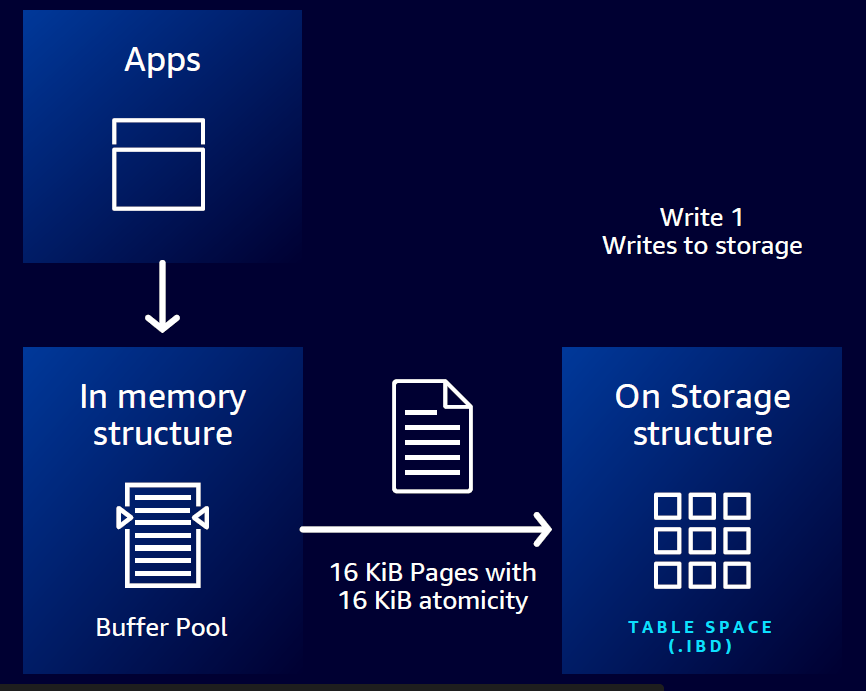
简洁的系统必然带来更高的效率,优化写入让写入事务吞吐量提高多达 2 倍,且无需额外费用,非常适合写入密集型应用,比如数字支付,金融交易,在线游戏等等。
这就是软件和硬件结合带来的威力。
有了优化写入,自然有对应的 “优化读取”。
在云数据库中,计算节点和存储节点一般是分离的。我们在做数据分析的时候经常需要很复杂的查询,涉及的数据会有上千万条,还需要分组,计算,排序等,这时候MySQL就会形成临时对象,当临时对象大到一定程度,就需要形成临时的表空间,移到硬盘上来存储了。
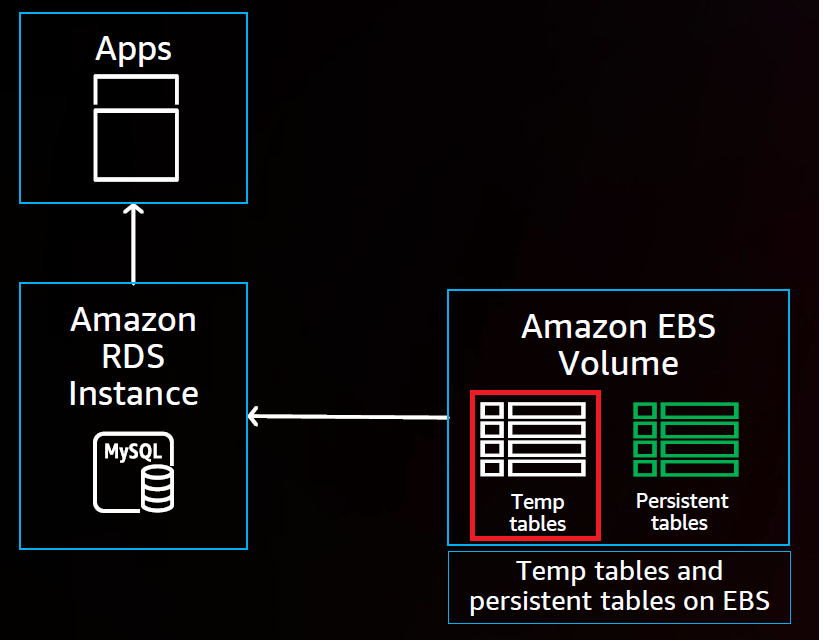
上图中,Amazon RDS实例是计算节点,Amazon Elastic Block Store(Amazon EBS)是存储节点,这个临时的表空间(上图红框所示)是存储在Amazon EBS上,由于是分布式的存储,访问就会有一定的延迟。
现在通过软硬一体化,在Amazon RDS实例上挂载一张NVMe的SSD存储,它针对低延迟、高随机 I/O 性能和高顺序读取吞吐量进行了优化。
在软件层面,让临时表空间转移到这个SSD存储卡中,计算节点直接访问本地存储,这速度立刻飞起。
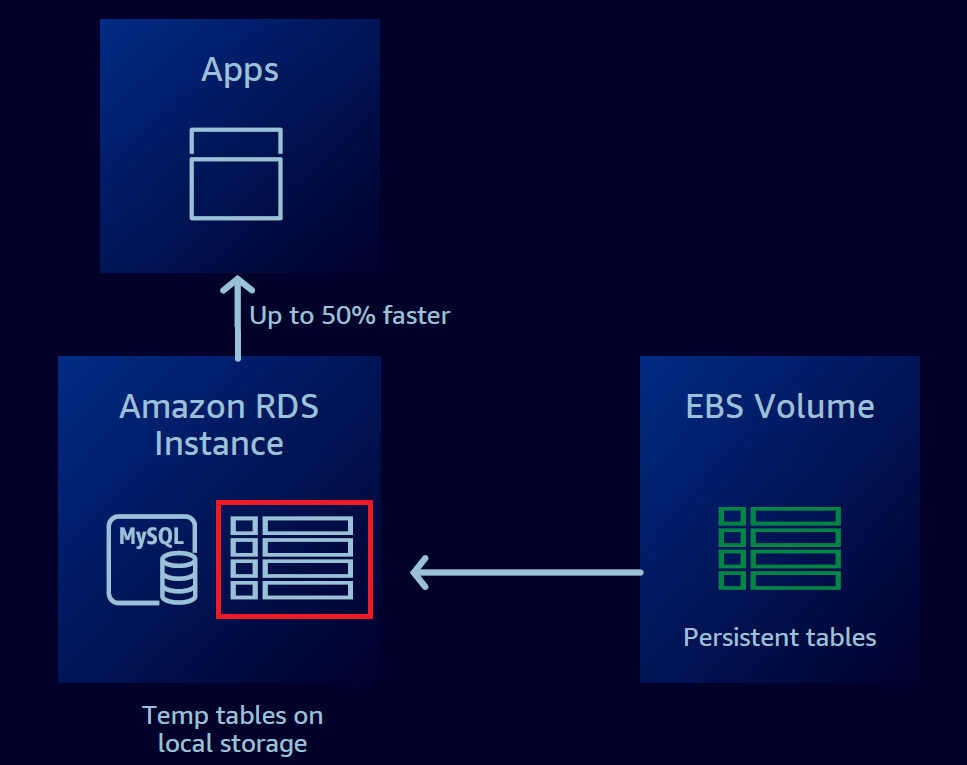
对于复杂查询,“优化读取”的加速效应非常明显,可以提升50%, 查询越大越复杂,优化效果越好。
“优化写入”和“优化读取”需要RDS MySQL 8及以上的版本,这里正好提醒大家一下, MySQL 8已经发布快5年了,迭代了30多个版本,非常稳定,如果你还在用较低的版本,是时候做升级了!
MySQL 8性能强劲,全内存访问可以轻易跑到200万QPS,I/O极端高负载场景跑到16万QPS,此外还支持“DDL原子化”、“不可见索引”、“窗口函数”、“通用表表达式”等一系列新特性,对于新应用,直接上MySQL 8吧!
数据库和底层硬件紧密集成,这是云数据库发展的方向,是云服务厂商必须要修炼的内功。
亚马逊云科技不仅看到了这一点,而且率先在它的云数据库中实现了软硬件的一体化,我想这就是它能在执行力和远见层面都排名第一的原因吧!
“优化写入”的功能是在2022年11月的亚马逊云科技 re:Invent上正式发布的,仅仅3个月以后,就在中国区上线了,这是个非常快的速度,毕竟这是基于硬件层面的优化,再次展示了亚马逊云科技的执行力,相信“优化读取”和“跨Region的数据库集群”在中国区也会很快推出。
随着云计算的普及,数据库市场发生了根本改变,云原生数据库已经逐渐走向了舞台的正中央。Gartner的报告显示,2023年,整个数据库管理系统市场规模将达到1000亿美元,作为云数据库的领导者,目前已经有80多万个数据库迁移到了亚马逊云科技上,期待亚马逊云原生数据库继续创新,推出新功能,引领行业前进,更好地满足客户的需求。