数据科学
数据科学是研究处理大量数据并为预测、规范和规范分析模型提供数据的研究。它有助于使用各种科学方法、算法、工具和流程从大量数据集中区分有用的原始数据/见解。它包括从大量数据集中挖掘、捕获、分析和利用数据。它是各种领域的组合,例如计算机科学、机器学习、人工智能、数学、商业和统计学。
数据科学帮助我们将业务问题转化为研究项目,然后再次将其转化为实用的解决方案。数据科学一词是由于数理统计、数据分析和大数据的发展而出现的。
数据科学的整个工作流程包括:理解商业问题、数据收集、数据清洗和准备、模型构建、评估和部署、结果可视化。
数据科学所需的技能
如果希望在数据科学领域转行,那么必须对数学、统计学、编程和分析工具有深入的了解。以下是在进入该领域之前应该具备的一些重要技能。
·精通 Python、R、SAS 和 Scala编程语言等。
·SQL领域的强大实践知识。
·能够处理各种格式的数据,例如视频、文本、音频等。
·了解各种分析功能。
·机器学习和人工智能的基础知识。

大数据
大数据(big data),或称巨量资料,指的是所涉及的资料量规模巨大到无法透过主流软件工具,在合理时间内达到撷取、管理、处理、并整理成为帮助企业经营决策更积极目的的资讯。
研究机构Gartner是这样定义的:“大数据”是需要新处理模式才能具有更强的决策力、洞察发现力和流程优化能力来适应海量、高增长率和多样化的信息资产。
麦肯锡全球研究所给出的定义是:一种规模大到在获取、存储、管理、分析方面大大超出了传统数据库软件工具能力范围的数据集合。
大数据具有五大特点,称为5V。
1. 多样(Variety)
大数据的多样性是指数据的种类和来源是多样化的,数据可以是结构化的、半结构化的以及非结构化的,数据的呈现形式包括但不仅限于文本,图像,视频,HTML页面等等。
2. 大量(Volume)
大数据的大量性是指数据量的大小,采集、存储和计算的数据量都非常大。
3. 高速(Velocity)
大数据的高速性是指数据增长快速,处理快速,每一天,各行各业的数据都在呈现指数性爆炸增长。在许多场景下,数据都具有时效性,如搜索引擎要在几秒中内呈现出用户所需数据。企业或系统在面对快速增长的海量数据时,必须要高速处理,快速响应。
4. 低价值密度(Value)
大数据的低价值密度性是指在海量的数据源中,真正有价值的数据少之又少,许多数据可能是错误的,是不完整的,是无法利用的。总体而言,有价值的数据占据数据总量的密度极低,提炼数据好比浪里淘沙。
5. 真实性(Veracity)
大数据的真实性是指数据的准确度和可信赖度,代表数据的质量。
大数据技术是继物联网、云计算之后IT产业的有一次颠覆性的技术改革,它包含了几层含义:
①数据价值的利用,包括数据采集、数据储存、数据分析、数据传输、数据挖掘、数据安全等。
②对数据的“加工”能力,比如数据处理的速度。大数据的意义不在于掌握庞大的数据信息,而在于对数据进行专业化处理,通过加工实现数据的价值和增值。
③大数据技术包括大规模并行处理数据库、数据挖掘电网、分布式文件系统、分布式数据库、云计算及平台、物联网和可扩展的存储系统。
大数据的意义不仅仅在于生产和掌握庞大的数据信息,更重要的是对有价值的数据进行专业化处理。
大数据所需的技能
·对机器学习概念有深入的了解
·了解数据库,如 SQL、NoSQL 等。
·深入了解各种编程语言,如Hadoop、Java、Python等。
·了解 Apache Kafka、Scala 和云计算
·熟悉 Hive 等数据库仓库。
人工智能
人工智能(Artificial Intelligence),英文缩写为AI,通俗来讲就是用机器去做在过去只有人能做的事。
人工智能是一门边缘学科,属于自然科学和社会科学的交叉。
研究范畴有自然语言处理,知识表现,智能搜索,推理,规划,机器学习,知识获取,组合调度问题,感知问题,模式识别,逻辑程序设计软计算,不精确和不确定的管理,人工生命,神经网络,复杂系统,遗传算法等。
人工智能所需的技能
·精通编程语言,如Python、C++、Java
·数据建模和评估
·概率和统计
·分布式计算
·机器学习算法
机器学习
机器学习的核心是“使用算法解析数据,从中学习,然后对新数据做出决定或预测”。
也就是说计算机利用以获取的数据得出某一模型,然后利用此模型进行预测的一种方法,这个过程跟人的学习过程有些类似,比如人获取一定的经验,可以对新问题进行预测。
机器学习领域知名学者Tom M.Mitchell曾给机器学习做如下定义:
如果计算机程序针对某类任务T的性能(用P来衡量)能通过经验E来自我改善,则认为关于T和P,程序对E进行了学习。
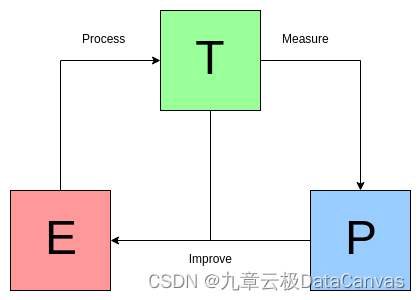
通俗来讲,计算机针对某一任务,从经验中学习,并且能越做越好,这一过程就是机器学习。
一般情况下,“经验”都是以数据的方式存在的,计算机程序从这些数据中学习。学习的关键是模型算法,它可以学习已有的经验数据,用以预测未知数据。
根据是否在人类的监督下进行学习这个问题,机器学习任务可以划分为:监督学习、半监督学习、无监督学习和强化学习。
机器学习(Machine Learning)是人工智能的一个分支,也是人工智能的一种实现方法。
大数据和数据科学的区别与联系

数据科学、人工智能、机器学习之间的关系
机器学习是连接数据科学和 AI 的纽带。这是因为机器学习是从数据中不断学习的过程。因此,AI 是帮助数据科学获得结果和解决用于特定问题的方案的工具。机器学习有助于实现这一目标。

因此确切地说,数据科学涵盖 AI,包括机器学习。机器学习有另一个子技术 ——深度学习。
深度学习是用于建立、模拟人脑进行分析学习的神经网络,并模仿人脑的机制来解释数据的一种机器学习技术,通过运用多层次的分析和计算手段来得到结果,最终目标是让机器能够像人一样具有分析学习能力,能够识别文字、图像和声音等数据。
总结:大数据产生方法,数据科学产生见解,机器学习产生预测,人工智能产生行为,大数据、数据科学、人工智能和机器学习相互重叠,但它们的具体功能不同,并且有各自的应用领域。