分类目录:《人工智能与大数据面试指南》总目录
《人工智能与大数据面试指南》系列下的内容会持续更新,有需要的读者可以收藏文章,以及时获取文章的最新内容。
随机梯度下降(Stochastic Gradient Descent, SGD)
随机梯度下降(Stochastic Gradient Descent, SGD)在第 k k k个训练迭代的更新
输入:学习率 ϵ k \epsilon_k ϵk;初始化参数 θ 0 \theta_0 θ0或第 k − 1 k-1 k−1次输出参数 θ k − 1 \theta_{k-1} θk−1
输出:第 k k k次迭代后的参数 θ k \theta_k θk
(1) while 停止准则未满足 \quad\text{停止准则未满足} 停止准则未满足
(2) \quad 从训练集中采包含 m m m个样本 { x ( 1 ) , x ( 2 ) , ⋯ , x ( m ) } \{x^{(1)}, x^{(2)}, \cdots, x^{(m)}\} { x(1),x(2),⋯,x(m)}的小批量,其中 x ( i ) x^{(i)} x(i)对应目标为 y ( i ) y^{(i)} y(i)
(3) \quad 计算梯度估计: g k = 1 m ∇ θ ∑ i L ( f ( x ( i ) ; θ ) , y ( i ) ) g_k = \frac{1}{m}\nabla_\theta\sum_iL(f(x^{(i)}; \theta), y^{(i)}) gk=m1∇θ∑iL(f(x(i);θ),y(i))
(4) θ k = θ k − 1 − ϵ g k \quad\theta_k = \theta_{k-1} - \epsilon g_k θk=θk−1−ϵgk
(5) k = k + 1 \quad k = k + 1 k=k+1
(6) return θ k \theta_k θk
在实践中,有必要随着时间的推移逐渐降低学习率,因此我们将第 k k k步迭代的学习率记作 ϵ k \epsilon_k ϵk。这是因为SGD中梯度估计引入的噪声源( m m m个训练样本的随机采样)并不会在极小点处消失。相比之下,当我们使用批量梯度下降到达极小点时,整个代价函数的真实梯度会变得很小,之后为0,因此批量梯度下降可以使用固定的学习率。保证SGD收敛的一个充分条件是:
∑ k = 1 ∞ ϵ k = ∞ 且 ∑ k = 1 ∞ ϵ k 2 < ∞ \sum_{k=1}^\infty\epsilon_k=\infty\quad\text{且}\quad\sum_{k=1}^\infty\epsilon_k^2<\infty k=1∑∞ϵk=∞且k=1∑∞ϵk2<∞
实践中,一般会线性衰减学习率直到第 τ \tau τ次迭代:
ϵ k = ( 1 − k τ ) ϵ 0 + k τ ϵ τ \epsilon_k=(1-\frac{k}{\tau})\epsilon_0+\frac{k}{\tau}\epsilon_\tau ϵk=(1−τk)ϵ0+τkϵτ
在 τ \tau τ步迭代之后,一般使 ϵ \epsilon ϵ保持常数。使用线性策略时,需要选择的参数为 ϵ 0 \epsilon_0 ϵ0、 ϵ τ \epsilon_\tau ϵτ和 τ \tau τ。通常 τ \tau τ被设为需要反复遍历训练集几百次的迭代次数。通常 ϵ τ \epsilon_\tau ϵτ应设为大约 ϵ 0 \epsilon_0 ϵ0的1%。主要问题是如何设置 ϵ 0 \epsilon_0 ϵ0。若 ϵ 0 \epsilon_0 ϵ0太大,学习曲线将会剧烈振荡,代价函数值通常会明显增加。温和的振荡是良好的,容易在训练随机代价函数(例如使用Dropout的代价函数)时出现。如果学习率太小,那么学习过程会很缓慢。如果初始学习率太低,那么学习可能会卡在一个相当高的代价值。通常,就总训练时间和最终代价值而言,最优初始学习率的效果会好于大约迭代100次后最佳的效果。因此,通常最好是检测最早的几轮迭代,选择一个比在效果上表现最佳的学习率更大的学习率,但又不能太大导致严重的震荡。
参考文章:《随机梯度下降(Stochastic Gradient Descent, SGD)》
Momentum
Momentum旨在加速学习,特别是处理高曲率、小但一致的梯度,或是带噪声的梯度。Momentum 积累了之前梯度指数级衰减的移动平均,并且继续沿该方向移动。Momentum的效果如下图所示所示:
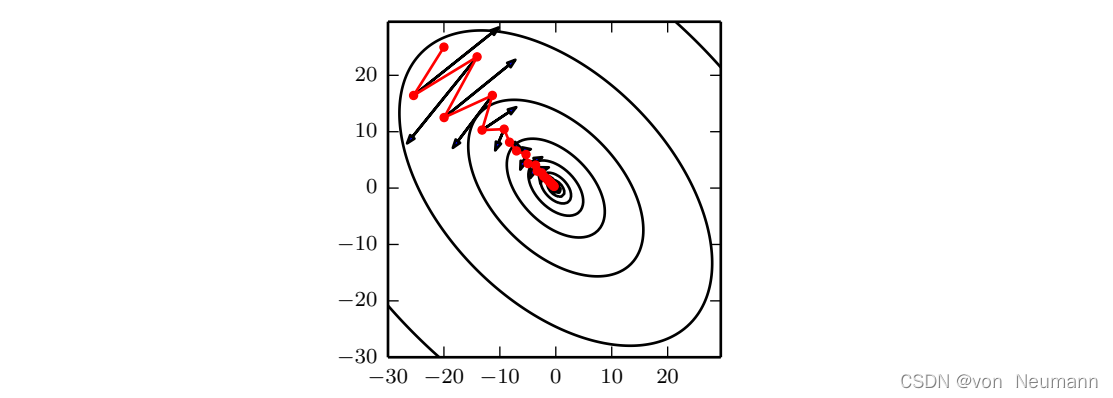
Momentum的主要目的是解决两个问题:Hessian矩阵的病态条件和随机梯度的方差。我们通过此图说明Momentum如何克服这两个问题的第一个。等高线描绘了一个二次损失函数(具有病态条件的Hessian矩阵)。横跨轮廓的红色路径表示Momentum学习规则所遵循的路径,它使该函数最小化。在该路径的每个步骤画一个箭头,表示梯度下降将在该点采取的步骤。可以看到,一个病态条件的二次目标函数看起来像一个长而窄的山谷或具有陡峭边的峡谷。Momentum正确地纵向穿过峡谷,而普通的梯度步骤则会浪费时间在峡谷的窄轴上来回移动。
从形式上看,Momentum引入了变量 v v v充当速度角色——它代表参数在参数空间移动的方向和速率。速度被设为负梯度的指数衰减平均。名称Momentum来自物理类比,根据牛顿运动定律,负梯度是移动参数空间中粒子的力。动量在物理学上定义为质量乘以速度。在Momentum中,我们假设是单位质量,因此速度向量 v v v也可以看作粒子的动量。超参数 α ∈ [ 0 , 1 ) \alpha\in[0,1) α∈[0,1)决定了之前梯度的贡献衰减得有多快。更新规则如下:
v = α v − ϵ ∇ θ ( 1 m ∑ i = 1 m L ( f ( x i ) ) ) θ = θ + v v = \alpha v-\epsilon\nabla_\theta(\frac{1}{m}\sum_{i=1}^mL(f(x^{i})))\\ \theta=\theta+v v=αv−ϵ∇θ(m1i=1∑mL(f(xi)))θ=θ+v
速度 v v v累积了梯度元素 ∇ θ ( 1 m ∑ i = 1 m L ( f ( x i ) ) ) \nabla_\theta(\frac{1}{m}\sum_{i=1}^mL(f(x^{i}))) ∇θ(m1∑i=1mL(f(xi)))。相对于 ϵ \epsilon ϵ, α \alpha α越大,之前梯度对现在方向的影响也越大。
Momentum(Gradient Descent with Momentum, GDM)第 k k k次迭代
输入:学习率 ϵ \epsilon ϵ;初始化参数 θ 0 \theta_0 θ0或第 k − 1 k-1 k−1次输出参数 θ k − 1 \theta_{k-1} θk−1;动量参数 α \alpha α;第 k − 1 k-1 k−1次输出速度 v k − 1 v_{k-1} vk−1
输出:第 k k k次迭代后的参数 θ k \theta_k θk
(1) while 停止准则未满足 \quad\text{停止准则未满足} 停止准则未满足
(2) \quad 从训练集中采包含 m m m个样本 { x ( 1 ) , x ( 2 ) , ⋯ , x ( m ) } \{x^{(1)}, x^{(2)}, \cdots, x^{(m)}\} { x(1),x(2),⋯,x(m)}的小批量,其中 x ( i ) x^{(i)} x(i)对应目标为 y ( i ) y^{(i)} y(i)
(3) \quad 计算梯度估计: g k = 1 m ∇ θ ∑ i L ( f ( x ( i ) ; θ ) , y ( i ) ) g_k = \frac{1}{m}\nabla_\theta\sum_iL(f(x^{(i)}; \theta), y^{(i)}) gk=m1∇θ∑iL(f(x(i);θ),y(i))
(4) v k = α v k − 1 − ϵ g k \quad v_k = \alpha v_{k-1} - \epsilon g_k vk=αvk−1−ϵgk
(5) θ k = θ k − 1 + v \quad\theta_k = \theta_{k-1}+ v θk=θk−1+v
(6) k = k + 1 \quad k = k + 1 k=k+1
(7) return θ k \theta_k θk
之前,步长只是梯度范数乘以学习率。现在,步长取决于梯度序列的大小和排列。当许多连续的梯度指向相同的方向时,步长最大。如果Momentum总是观测到梯度 g g g,那么它会在方向 − g -g −g上不停加速,直到达到最终速度,其中步长大小为:
ϵ ∣ ∣ g ∣ ∣ 1 − α \frac{\epsilon||g||}{1-\alpha} 1−αϵ∣∣g∣∣
因此将Momentum的超参数视为 1 1 − α \frac{1}{1-\alpha} 1−α1有助于理解。例如, α = 0.9 \alpha=0.9 α=0.9对应着最大速度10倍于梯度下降算法。在实践中, α \alpha α的一般取值为0.5、0.9和0.99。和学习率一样, α \alpha α也会随着时间不断调整。一般初始值是一个较小的值,随后会慢慢变大。随着时间推移调整 α \alpha α没有收缩 ϵ \epsilon ϵ重要。根据上面所述,我们就可以看到,在梯度下降的过程中,来回震荡的方向就会由于历史梯度而被抵消,真正需要迅速下降的方向就会被加强。
参考文章:《Momentum(Gradient Descent with Momentum, GDM)》
Nesterov Momentum
受Nesterov Accelerated Gradient算法的启发,Sutskever提出了动量算法的一个变种。这种情况的更新规则如下:
v = α v − ϵ ∇ θ [ 1 m ∑ i = 1 m L ( f ( x ( i ) ) ; θ + α v ) , y ( i ) ] θ = θ + v v=\alpha v-\epsilon\nabla_\theta[\frac{1}{m}\sum_{i=1}^mL(f(x^{(i)});\theta+\alpha v), y^{(i)}]\\ \quad\\ \theta=\theta+v v=αv−ϵ∇θ[m1i=1∑mL(f(x(i));θ+αv),y(i)]θ=θ+v
其中参数 α \alpha α和 ϵ \epsilon ϵ发挥了和标准动量方法中类似的作用。Nesterov动量和标准动量之间的区别体现在梯度计算上。Nesterov动量中,梯度计算在施加当前速度之后。因此,Nesterov动量可以解释为往标准动量方法中添加了一个校正因子。
Nesterov Momentum第 k k k次迭代
输入:学习率 ϵ \epsilon ϵ;初始化参数 θ 0 \theta_0 θ0或第 k − 1 k-1 k−1次输出参数 θ k − 1 \theta_{k-1} θk−1;动量参数 α \alpha α;第 k − 1 k-1 k−1次输出速度 v k − 1 v_{k-1} vk−1
输出:第 k k k次迭代后的参数 θ k \theta_k θk
(1) while 停止准则为满足 \quad\text{停止准则为满足} 停止准则为满足
(2) \quad 从训练集中采包含 m m m个样本 { x ( 1 ) , x ( 2 ) , ⋯ , x ( m ) } \{x^{(1)}, x^{(2)}, \cdots, x^{(m)}\} { x(1),x(2),⋯,x(m)}的小批量,其中 x ( i ) x^{(i)} x(i)对应目标为 y ( i ) y^{(i)} y(i)
(3) \quad 计算梯度估计: g k = 1 m ∇ θ + α v ∑ i L ( f ( x ( i ) ; θ + α v ) , y ( i ) ) g_k = \frac{1}{m}\nabla_{\theta+\alpha v}\sum_iL(f(x^{(i)}; \theta+\alpha v), y^{(i)}) gk=m1∇θ+αv∑iL(f(x(i);θ+αv),y(i))
(4) v k = α v k − 1 − ϵ g k \quad v_k = \alpha v_{k-1} - \epsilon g_k vk=αvk−1−ϵgk
(5) θ k = θ k − 1 + v \quad\theta_k = \theta_{k-1}+ v θk=θk−1+v
(6) k = k + 1 \quad k = k + 1 k=k+1
(7) return θ k \theta_k θk
在凸批量梯度的情况下,Nesterov Momentum将额外误差收敛率从 O ( 1 k ) O(\frac{1}{k}) O(k1)(k步后)改进到 O ( 1 k 2 ) O(\frac{1}{k^2}) O(k21)。可惜,在随机梯度的情况下,Nesterov Momentum没有改进收敛率。
参考文章:《Nesterov Momentum》
AdaGrad
AdaGrad算法独立地适应所有模型参数的学习率,缩放每个参数反比于其所有梯度历史平方值总和的平方根。具有损失最大偏导的参数相应地有一个快速下降的学习率,而具有小偏导的参数在学习率上有相对较小的下降。净效果是在参数空间中更为平缓的倾斜方向会取得更大的进步。
在凸优化背景中,AdaGrad算法具有一些令人满意的理论性质。然而,经验上已经发现,对于训练深度神经网络模型而言,从训练开始时积累梯度平方会导致有效学习率过早和过量的减小。其是想就是对于每个参数,初始化一个变量 r r r为0,然后每次将该参数的梯度平方求和累加到这个变量 r r r上,然后在更新这个参数的时候,学习率就变为 ϵ δ + + r \frac{\epsilon}{\delta++\sqrt{r}} δ++rϵ,这里的 δ \delta δ是为了数值稳定性而加上的,因为有可能 r r r的值为0。AdaGrad在某些深度学习模型上效果不错,但不是全部。
AdaGrad算法
输入:全局学习率 ϵ \epsilon ϵ;初始参数 θ \theta θ;小常数 δ \delta δ(为了数值稳定大约设为 1 0 − 7 10^{-7} 10−7;)
输出:神经网络参数 θ \theta θ
(1) 初始化梯度累积变量 r = 0 r=0 r=0
(2) while 停止准则未满足 \quad\text{停止准则未满足} 停止准则未满足
(1) \quad 从训练集中采包含 m m m个样本 { x ( 1 ) , x ( 2 ) , ⋯ , x ( m ) } \{x^{(1)}, x^{(2)}, \cdots, x^{(m)}\} { x(1),x(2),⋯,x(m)}的小批量,其中 x ( i ) x^{(i)} x(i)对应目标为 y ( i ) y^{(i)} y(i)
(2) \quad 计算梯度估计: g = 1 m ∇ θ ∑ i L ( f ( x ( i ) ; θ ) , y ( i ) ) g = \frac{1}{m}\nabla_\theta\sum_iL(f(x^{(i)}; \theta), y^{(i)}) g=m1∇θ∑iL(f(x(i);θ),y(i))
(3) \quad 累积平方梯度: r = r + g ⊙ g r=r+g\odot g r=r+g⊙g
(4) \quad 更新参数: θ = θ − ϵ δ + + r ⊙ g \theta=\theta-\frac{\epsilon}{\delta++\sqrt{r}}\odot g θ=θ−δ++rϵ⊙g
(5) return θ \theta θ
参考文章:《AdaGrad》
RMSProp
RMSProp算法修改AdaGrad以在非凸设定下效果更好,改变梯度积累为指数加权的移动平均。AdaGrad旨在应用于凸问题时快速收敛。当应用于非凸函数训练神经网络时,学习轨迹可能穿过了很多不同的结构,最终到达一个局部凸的区域。AdaGrad根据平方梯度的整个历史收缩学习率,可能使得学习率在达到这样的凸结构前就变得太小了。RMSProp使用指数衰减平均以丢弃遥远过去的历史,使其能够在找到凸碗状结构后快速收敛,它就像一个初始化于该碗状结构的AdaGrad算法实例。相比于AdaGrad,使用移动平均引入了一个新的超参数 ρ \rho ρ,用来控制移动平均的长度范围。
RMSProp算法
输入:全局学习率 ϵ \epsilon ϵ;衰减速率 ρ \rho ρ;初始参数 θ \theta θ;小常数 δ \delta δ(为了数值稳定大约设为 1 0 − 6 10^{-6} 10−6;
输出:神经网络参数 θ \theta θ
(1) 初始化梯度累积变量 r = 0 r=0 r=0
(2) while 停止准则未满足 \quad\text{停止准则未满足} 停止准则未满足
(1) \quad 从训练集中采包含 m m m个样本 { x ( 1 ) , x ( 2 ) , ⋯ , x ( m ) } \{x^{(1)}, x^{(2)}, \cdots, x^{(m)}\} { x(1),x(2),⋯,x(m)}的小批量,其中 x ( i ) x^{(i)} x(i)对应目标为 y ( i ) y^{(i)} y(i)
(2) \quad 计算梯度估计: g = 1 m ∇ θ ∑ i L ( f ( x ( i ) ; θ ) , y ( i ) ) g = \frac{1}{m}\nabla_\theta\sum_iL(f(x^{(i)}; \theta), y^{(i)}) g=m1∇θ∑iL(f(x(i);θ),y(i))
(3) \quad 累积平方梯度: r = ρ r + ( 1 − ρ ) g ⊙ g r=\rho r+(1-\rho)g\odot g r=ρr+(1−ρ)g⊙g
(4) \quad 更新参数: θ = θ − ϵ δ + t ⊙ g \theta=\theta-\frac{\epsilon}{\delta+t}\odot g θ=θ−δ+tϵ⊙g
(5) return θ \theta θ
以及使用Nesterov Momentum的RMSProp算法:
使用Nesterov Momentum的RMSProp算法
输入:全局学习率 ϵ \epsilon ϵ;衰减速率 ρ \rho ρ;初始参数 θ \theta θ;小常数 δ \delta δ(为了数值稳定大约设为 1 0 − 6 10^{-6} 10−6;动量系数 α \alpha α; v v v
输出:神经网络参数 θ \theta θ
(1) 初始化梯度累积变量 r = 0 r=0 r=0
(2) while 停止准则未满足 \quad\text{停止准则未满足} 停止准则未满足
(1) \quad 从训练集中采包含 m m m个样本 { x ( 1 ) , x ( 2 ) , ⋯ , x ( m ) } \{x^{(1)}, x^{(2)}, \cdots, x^{(m)}\} { x(1),x(2),⋯,x(m)}的小批量,其中 x ( i ) x^{(i)} x(i)对应目标为 y ( i ) y^{(i)} y(i)
(2) \quad 计算梯度估计: g k = 1 m ∇ θ + α v ∑ i L ( f ( x ( i ) ; θ + α v ) , y ( i ) ) g_k = \frac{1}{m}\nabla_{\theta+\alpha v}\sum_iL(f(x^{(i)}; \theta+\alpha v), y^{(i)}) gk=m1∇θ+αv∑iL(f(x(i);θ+αv),y(i))
(3) \quad 累积平方梯度: r = ρ r + ( 1 − ρ ) g ⊙ g r=\rho r+(1-\rho)g\odot g r=ρr+(1−ρ)g⊙g
(4) \quad 计算速度更新: v = α v − ϵ r ⊙ g v=\alpha v-\frac{\epsilon}{\sqrt{r}}\odot g v=αv−rϵ⊙g
(4) \quad 更新参数: θ = θ − ϵ δ + t ⊙ g \theta=\theta-\frac{\epsilon}{\delta+t}\odot g θ=θ−δ+tϵ⊙g
(5) return θ \theta θ
经验上,RMSProp已被证明是一种有效且实用的深度神经网络优化算法。目前它是深度学习从业者经常采用的优化方法之一。
参考文章:《RMSProp》
Adam
Adam是另一种学习率自适应的优化算法:
Adam算法
输入:步长 ϵ \epsilon ϵ(建议默认为0.001);矩估计的指数衰减速率 ρ 1 , ρ 2 ∈ [ 0 , 1 ) \rho_1, \rho_2\in[0, 1) ρ1,ρ2∈[0,1)(建议默认为: ρ 1 = 0.9 , ρ 2 = 0.999 \rho_1=0.9,\rho_2=0.999 ρ1=0.9,ρ2=0.999);初始参数 θ \theta θ;小用于数值稳定的小常数 δ \delta δ(为了数值稳定大约设为 1 0 − 8 10^{-8} 10−8;
输出:神经网络参数 θ \theta θ
(1) 初始化一阶和二阶矩变量 s = 0 , r = 0 s=0, r=0 s=0,r=0
(2) 初始化时间步 t = 0 t=0 t=0
(3) while 停止准则未满足 \quad\text{停止准则未满足} 停止准则未满足
(4) \quad 从训练集中采包含 m m m个样本 { x ( 1 ) , x ( 2 ) , ⋯ , x ( m ) } \{x^{(1)}, x^{(2)}, \cdots, x^{(m)}\} { x(1),x(2),⋯,x(m)}的小批量,其中 x ( i ) x^{(i)} x(i)对应目标为 y ( i ) y^{(i)} y(i)
(5) \quad 计算梯度估计: g = 1 m ∇ θ ∑ i L ( f ( x ( i ) ; θ ) , y ( i ) ) g = \frac{1}{m}\nabla_\theta\sum_iL(f(x^{(i)}; \theta), y^{(i)}) g=m1∇θ∑iL(f(x(i);θ),y(i))
(6) \quad 更新时间步: t = t + 1 \quad t = t + 1 t=t+1
(7) \quad 更新有偏一阶矩估计: s = ρ 1 s + ( 1 − ρ 1 ) g s=\rho_1 s +(1-\rho_1)g s=ρ1s+(1−ρ1)g
(8) \quad 更新有偏二阶矩估计: r = ρ 2 r + ( 1 − ρ 2 ) g ⊙ g r=\rho_2 r +(1-\rho_2)g\odot g r=ρ2r+(1−ρ2)g⊙g
(9) \quad 修正一阶矩的偏差: s ^ = s 1 − ρ 1 2 \hat{s}=\frac{s}{1-\rho_1^2} s^=1−ρ12s
(10) \quad 修正二阶矩的偏差: r ^ = r 1 − ρ 2 2 \hat{r}=\frac{r}{1-\rho_2^2} r^=1−ρ22r
(11) \quad 更新参数: θ = θ − ϵ s ^ δ + r ^ ⊙ g \theta=\theta-\epsilon\frac{\hat{s}}{\delta+\sqrt{\hat{r}}}\odot g θ=θ−ϵδ+r^s^⊙g
(12) return θ \theta θ
“Adam”这个名字派生自短语“Adaptive Moments”。早期算法背景下,它也许最好被看作结合RMSProp和具有一些重要区别的Momentum的变种。首先,在Adam中,Momentum直接并入了梯度一阶矩(指数加权)的估计。将Momentum加入RMSProp最直观的方法是将Momentum应用于缩放后的梯度。结合缩放的Momentum使用没有明确的理论动机。其次,Adam包括偏置修正,修正从原点初始化的一阶矩(Momentum项)和(非中心的)二阶矩的估计。RMSProp也采用了(非中心的)二阶矩估计,然而缺失了修正因子。因此,不像Adam, RMSProp二阶矩估计可能在训练初期有很高的偏置。Adam通常被认为对超参数的选择相当鲁棒,尽管学习率有时需要从建议的默认修改。