AIGC 行业最大的两个竞争对手:ChatGPT vs Google Bard! 本文介绍这两个人工智能引擎之间的技术差异。

截至目前Google Bard和ChatGPT之间最大的区别是:Bard知道ChatGPT,但ChatGPT却对Bard懵然不知。虽然我们可以玩转ChatGPT,而Bard对我们大多数人来说仍然遥不可及。
ChatGPT与Google Bard之战的开始
ChatGPT和Google Bard都是人工智能聊天机器人。人工智能的简易版本已经可以在手机上使用了,当你输入 "good"时,手机就可以预测下一个词是 “morning”。
ChatGPT最初是由OpenAI开发的,然后由微软以令人瞠目结舌的100亿美元(除了早先的10亿美元投资外)进行投资。谷歌方面,对他们的搜索垄断可能要结束而略感恐慌,因此推出了Bard,但这个版本仍然存在一些缺陷。在第一次现场演示中,Bard犯了几个事实性错误,让谷歌感到很尴尬。
ChatGPT和Google Bard比智能手机的预测文本功能要更加复杂,如果说要了解这两款智能机器人之间的差异,下面的内容你就不能错过了。
什么是ChatGPT?
ChatGPT于2022年11月30日突然出现在舞台上。到2022年12月4日,该服务每天有超过一百万的用户。2023年1月,这个数字膨胀到1亿多用户。
它突然这么受欢迎其基本原因是,它能以一种听起来几乎是人类的方式,为你提供许多主题的靠谱回答,而且任何能够上网的人都可以使用它。
ChatGPT是OpenAI创建的,OpenAI是一家位于旧金山的人工智能实验室,专注于创造友好的人工智能方案。该聊天机器人是基于GPT-3.5开发的,GPT-3.5是一个大型语言模型,当给定文本时,可以持续给请求者提供回复。
ChatGPT在此基础上增加了一些额外的训练–人类培训师通过与模型的互动改进了模型,并通过"奖励 "的方式让模型具备提供高质量答案的能力。
训练数据
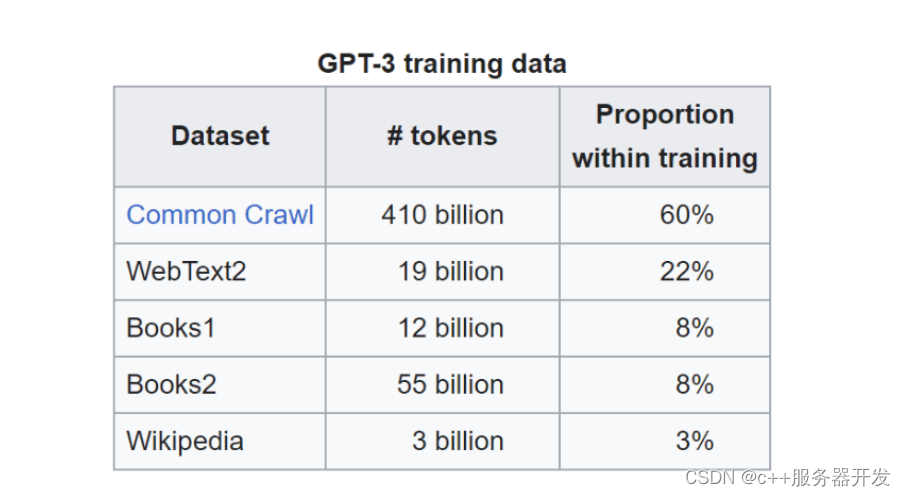
GPT-3.5是在一个巨大的网络文本数据集上训练的,包括一个叫做Common Crawl的流行数据集。Common Crawl包含PB级的网络数据,包括原始网页数据、元数据提取和文本提取。例如,它包括来自StrataScratch的URLs集合。想想ChatGPT使用训练的数据来自网友在ChatGPT的输入,这是不是很疯狂?
Common Crawl负责60%的训练数据,但GPT-3.5也有其他数据来源。
什么是Google Bard?
Google Bard 是在ChatGPT大受追捧的情况下,由Google推出的智能聊天机器人。与ChatGPT不同,Bard是由Google自己的模型LaMDA驱动。LaMDA是对话应用语言模型的简称,与ChatGPT不同的是,它没有那么惊艳,原因很简单,大多数人还不能访问它。尽管Google在2月初确实搞了一个充满尴尬的Bard演示,但目前Bard只对少数人开放。

Google Bard的主要优势是它对互联网开放。问ChatGPT“现在谁是总统?”,它是不知道的。这是因为训练数据在2021年中期左右被切断了。而Bard则是借鉴了今天互联网上的信息。从理论上讲,Bard应该能够从今天互联网上的数据中提取,告诉你现在谁是总统。
很容易看出Bard在几个关键方面是如何从ChatGPT中脱颖而出的。
训练数据
首先,LaMDA是在对话中训练的,专门用于对话,而不是像GPT-n模型那样只产生文本。虽然ChatGPT对其训练数据不加掩饰,但我们对Bard所训练的数据还不甚了解,可以通过查看LaMDA的研究论文来推断。谷歌的研究人员说,12.5%的训练数据来自Common Crawl,比如GPT-n模型。另外12.5%来自维基百科。而根据研究论文,他们使用了1.56万亿字的 “公共对话数据和网络文本”。
以下是完整的分类:
12.5%基于C4的数据(Common Crawl数据的衍生品)。
12.5%的英语维基百科
12.5%来自编程问答网站、教程和其他的代码文档
6.25%的英文网络文档
6.25%的非英语网络文档
50%来自公共论坛的对话数据
从上面的信息可以知道两者共同利用的数据,显然有维基百科。其余的数据明显是Google故意隐藏的,大概是为了保护Bard(和LaMDA)不被模仿。
LaMDA是通过微调Transformer的神经语言模型而形成的,它是一个最初由谷歌开发的开源神经网络架构。
ChatGPT存在一些壁垒,以防止它让人生厌或者说一些废话,但谷歌强调如何保证质量,以使Bard变成更好、更安全的聊天机器人。Bard经过微调,变得"高质量、接地气和安全"。
谷歌对此有很多说法,我建议阅读他们的相关博文,但如果你时间不多,基本上可以分成如下几个方面:
Bard应该给出有意义的回应–没有荒谬的内容,没有矛盾的内容
Bard应作出有见地、诙谐或出人意料的回应。
Bard应该避免任何有可能对用户造成伤害的东西–血腥、偏见、可憎的刻板印象等
Bard不胡编乱造
众所周知,由于一次错误的发布,谷歌还没有完全弄清楚底层需求。但值得注意的是,谷歌对设计要求说得很清楚,而ChatGPT没有说的那么清楚–至少目前是这样。
ChatGPT与Google Bard对比:模型参数为什么很重要?
ChatGPT确实比Bard拥有更多的模型参数–1750亿对1370亿。你可以把参数看作是模型调整的旋钮或杠杆,以适应它所训练的数据。更多的参数通常意味着模型有更多的能力来捕捉语言中的复杂关系,但也有过度拟合的风险。与ChatGPT相比,Google Bard可能不那么灵活,但也可能因为新的语言用例使其更加强大。
ChatGPT与Google Bard:共同点?
值得强调的是,Bard和ChatGPT的模型(分别是LaMDA和GPT-3.5)都位于基于Transformer的深度学习神经网络。
例如,Transformer可以使一个经过训练的模型来阅读一个句子或段落,注意这些词之间的关系,然后预测它认为接下来会出现什么词–类似前面提到的智能手机预测性文本的功能。
这里就不展开讨论了,但你需要知道的是,这意味着在其核心部分,Bard和ChatGPT彼此之间没有太大区别。
ChatGPT与Google Bard:所有权
虽然所有权并不完全是一个技术上的差异,但它是值得记住的。
Google Bard是由Google制作并完全拥有的,在LaMDA之上,LaMDA也是由Google创建的。
ChatGPT是由OpenAI开发的,这是一家位于旧金山的人工智能研究实验室。OpenAI最初是非营利性的,但它在2019年创建了一个营利性的子公司。OpenAI也是Dall-E的幕后推手,你可能玩过的人工智能文本到图像的生成。
虽然微软在OpenAI上投入了大量资金,但就目前而言,它是一个独立的研究机构。
ChatGPT和谷歌 Bard哪个好?
这个问题很难给出公平的回答,因为两者相似的地方很多,但也有不同的地方。首先,现在几乎没有人可以访问Google Bard。另外,ChatGPT的训练数据几乎在两年前就被切断了。
两者都是文本生成器–你提供一个提示,Google Bard和ChatGPT都能回答。两者都有数十亿的参数来微调模型。两者都有重叠的训练数据源,并且都建立在Transformer上,即同一个神经网络模型。
它们的设计目的也不同,Bard将帮助你浏览谷歌搜索,它被设计为对话式的。ChatGPT可以生成整个博客文章。它的设计是为了输出有意义的文本。
即便说了ChatGPT和Google Bard之间的差异,那也只能证明人工智能驱动的文本生成技术已经取得了多大进展。虽然它们都有一段路要走,而且都面临着版权和道德方面的争议,但这两个生成器都是现代人工智能模型发展的有力证明。