图文原创:谭婧
指导专家:鲁蔚征



用户在APP里不是静止的,买买,逛逛,点点,划划就会产生海量行为数据。
很多人可能不知道,手机APP里有很多“埋点”。

你在手机APP里的动作,会触发“埋点”。

后台大数据系统悄咪咪地记录下来。理解成“埋雷”也说得通
那么问题来了,埋雷,不是,埋点的密度有多大?

这是每家互联网公司的商业秘密很难知道。
但是,埋点越密集,越多,你在手机APP里的一举一动,就越会被详细记录。
有了这些记录,大数据系统就得了社交牛逼症。
每天,只要你打开互联网公司的手机APP,就在和大数据系统“打交道”。
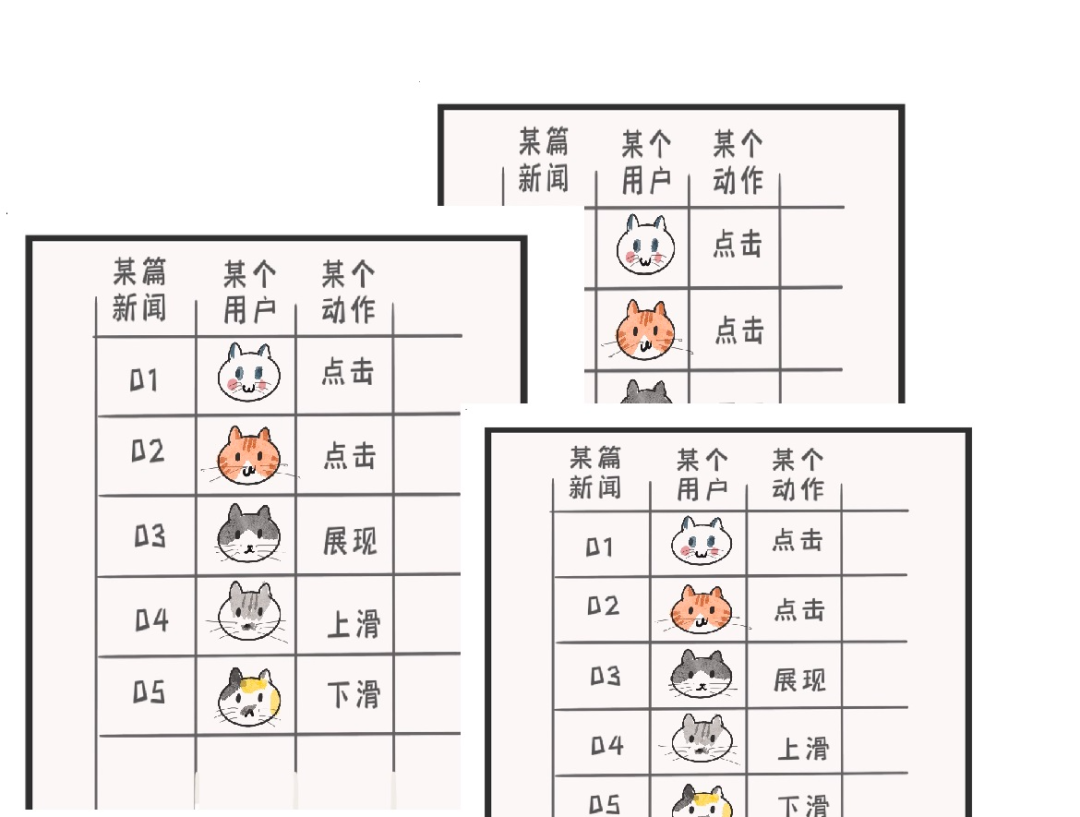
比如,周五的晚上,我点开看了体育新闻,左滑,右滑,上翻,下滑,阅读了新闻,点赞,评论,这些行为,产生了使用记录。
大家的行为,都记在“超大表格”里。
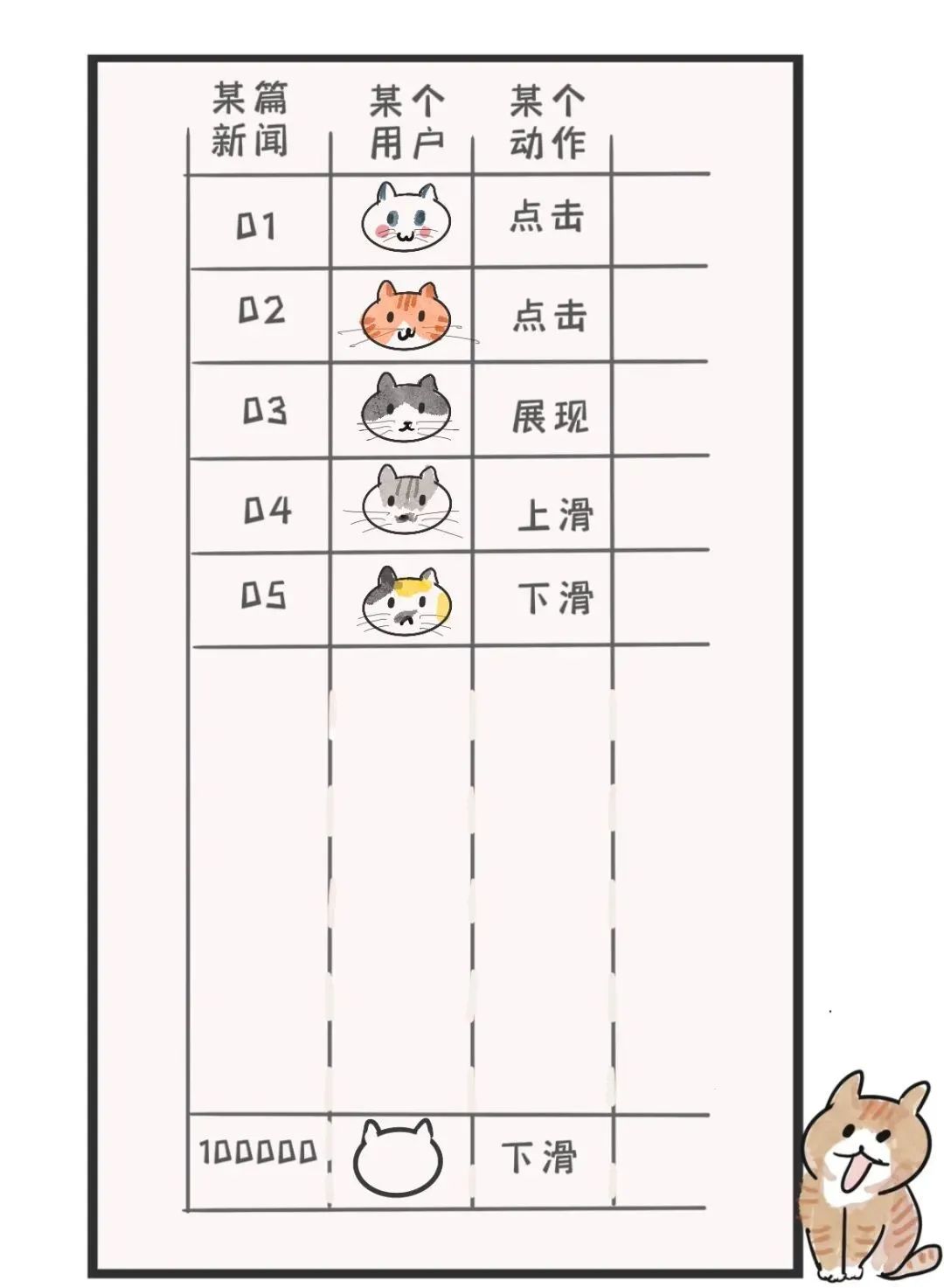
这个超大表格有多大?
假设一个国民级的APP,2亿日活。
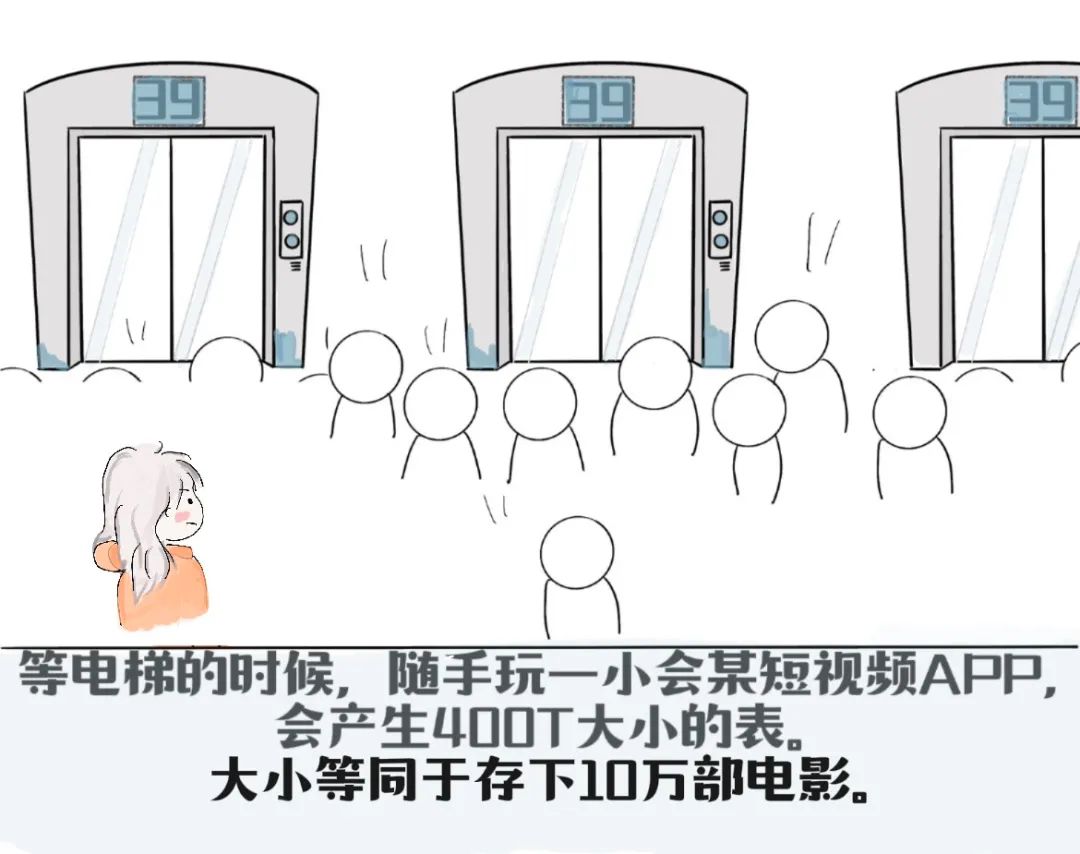
好比2亿人,每天等电梯的时候,随手玩一小会某短视频APP。
所产生的表格,大约将会有400T大小。
400T有多大?
一部电影大约4G,那这个表格的大小等同于存下10万部电影的大小。
一个Word文档4M,就是1亿个Word文件。
再假设2亿人,睡前刷了一小时短视频APP,超大表格会有多大?
一小时产生5万行表格,再X2亿等于一张10万亿行的表格。

这个量级用excel肯定是处理不了的。

这张“用户行为表”只是其中之一而已。

之后,这些记录去哪里了?
手机产生的用户行为记录,也就是“超大表”里一行一行的数据,通过网络不断流入数据中心,进入数据中心的服务器集群。
数据中心的服务器集群里有什么?
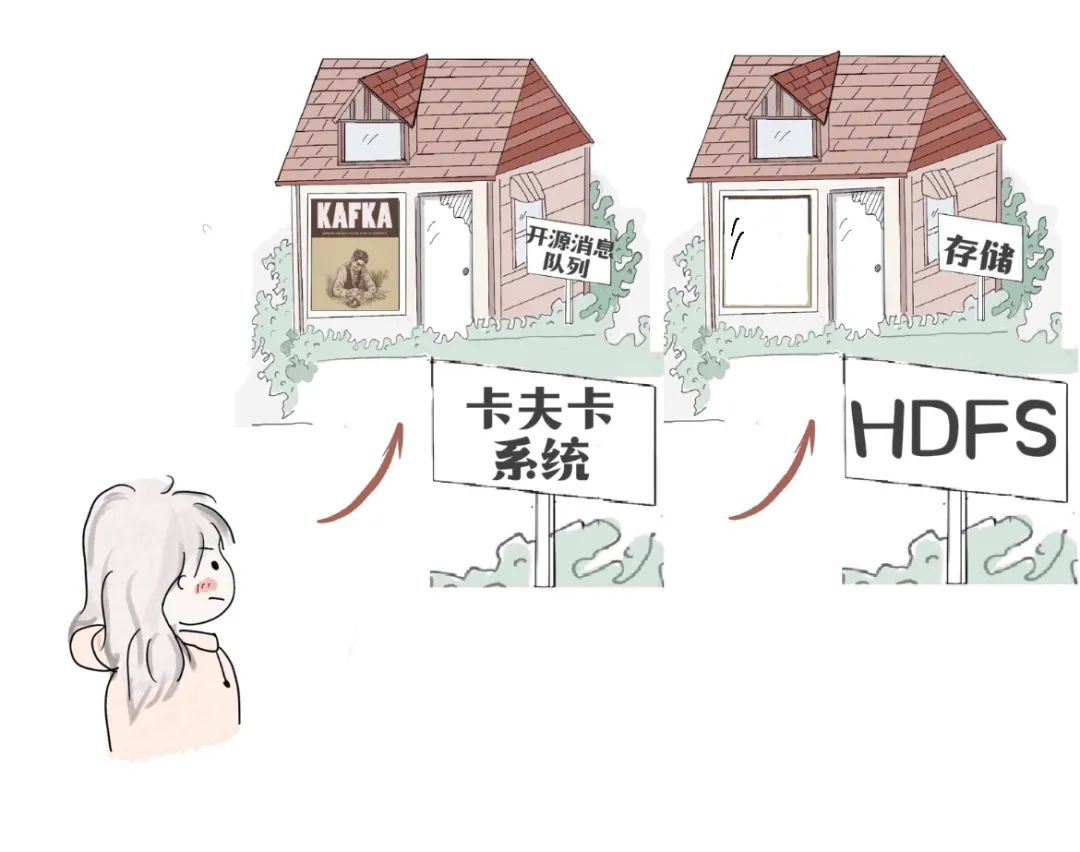
安装了一个卡夫卡(Kafka)系统。
对,就是小说家卡夫卡。
卡夫卡的作者们认为,数据日夜不停“写入”存储,像一位作家,于是,致敬自己喜欢的作家,以其名字来命名。

“卡夫卡”是一种大数据领域的开源消息队列框架(一种接收消息并发送消息的技术,功能之一是把数据写入持久化存储里)。

消息队列,顾名思义,很多消息在排队。
“超大表格”经过“卡夫卡”,写入Hadoop分布式文件系统(HDFS)里。
如果是一台服务器坏了,很有可能是多个文件包部分受损。
但是,HDFS“狡兔三窟”(有3份冗余,一个文件写了三份)。
公有云计算厂商提供的大数据系统服务很多,比如一键创建HDFS。
数据仿佛一条河流,简称数据流。
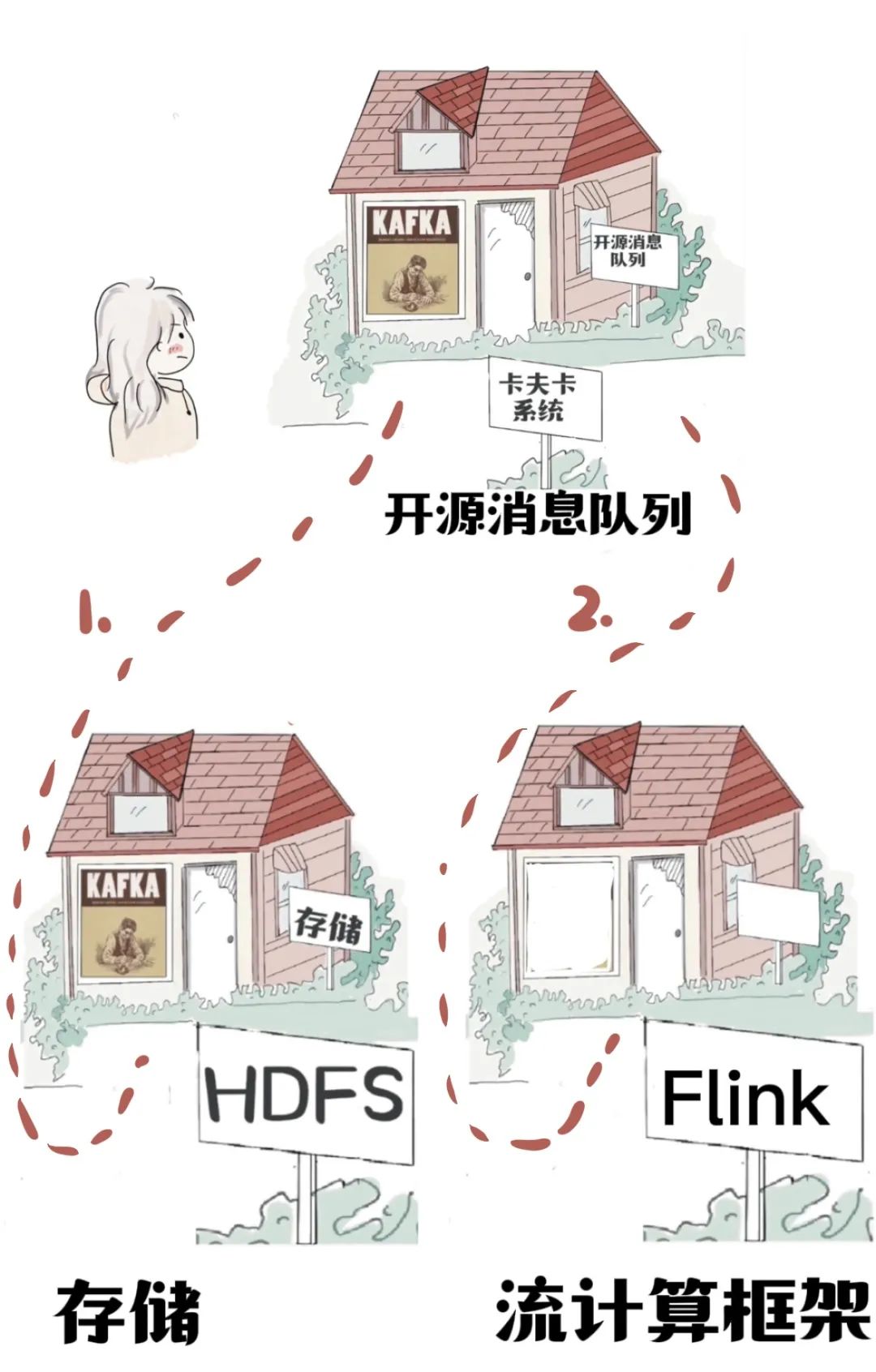
数据流来了,经过卡夫卡开始“有序排队”。
先往HDFS里面写一份,相当于备份,为其他工作准备材料。
消息队列还有另一个功能“分流”,把数据分发给不同的地方,存储,还是计算。
一份数据流向存储。
另一份数据流向,流计算框架Flink,直接计算。
"超大表格"里还可以记录时间,用表里的时间来精确计算使用APP的时长,几点几分进入APP,几点几分退出APP。
这取决于“埋点”的密度。
“你看的新闻”和“你购买的商品”背后是有一套标签体系。
“经常阅读”和”反复购买“,这些行为就会成为用户的一部分标签,日积月累,成为用户画像。

标签是怎么被打上的?
被大数据计算系统计算出来的。
有两种计算方法:
第一,批处理。
一段时间,计算一下。每小时启动一个定时任务。这就是典型的批处理。启动定时任务的时间由工程师来定,也可以追求一分钟计算一次的“极致”,但是,这样程序员和系统可能都要重新投胎。
批处理,可以一个小时计算一次。那么,就一个小时计算一下标签。

第二,流处理。来一个就计算一个。
换句话说,批处理是让子弹飞一会。
流处理是,拉出去,就地枪决。
也可以用扫雪来理解。
新数据像雪片一样飞来。
批处理,一小时,扫雪一次(Spark)。
流处理,落一片,扫一片(Flink) 。
数据从卡夫卡系统出门,立刻进入Flink系统的大门,开始进行比如推荐场景下的“用户画像”之类的计算。
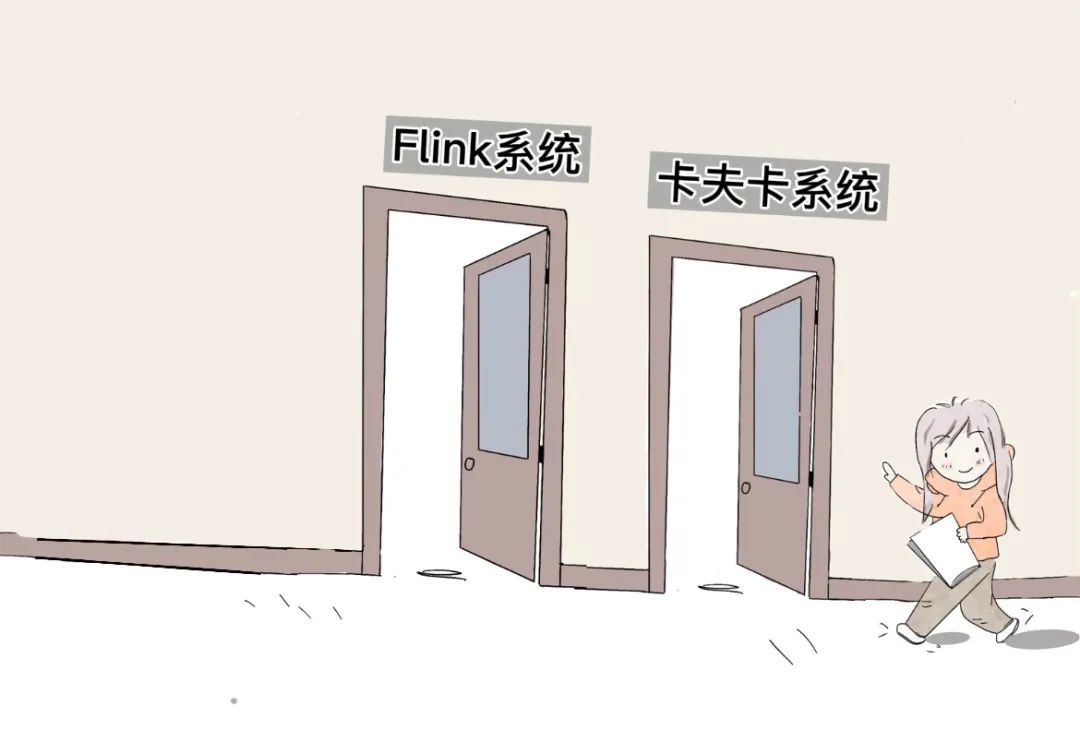
公司既会使用Spark,也会使用Flink。以Flink为代表的是流处理。以Spark为代表的是批处理。
Flink和Spark这扇门里走出来的“用户画像”其实是一种“用户特征”。
还有其他各种特征,特征喂给“人工智能模型”,模型可以预测你下一条,看什么样的信息,选购什么样的商品。
这就是大数据社交牛逼症的底气。


2022年3月1日,《互联网信息服务算法推荐管理规定》,规范算法提供方的行为。不得利用算法屏蔽信息、过度推荐和操纵榜单。
(完)
致谢:感谢鲁蔚征老师,他耐心地回答了我的很多个问题,使这篇文章成为可能。


更多阅读
AI框架系列:
DPU系列:
2. 永远不要投资DPU?
其他:
3. 隐私计算:消失的人工智能 “法外之地”
4. 售前,航空母舰,交付,皮划艇:银行的AI模型上线有多难?
6. 两大榜单揭晓啦,2021年中国高性能计算机性能TOP100+国际人工智能性能排行榜AIPerf500
7. “重型卡车自动驾驶,无量产,则无意义”赢彻科技CTO杨睿刚博士观点
8. AI芯片公司:拿下“超级石油”,助力地质模拟和人工智能

最后,再介绍一下主编自己吧,
我是谭婧,科技和科普题材作者。
为了在时代中发现故事,
我围追科技大神,堵截科技公司。
偶尔写小说,画漫画。
生命短暂,不走捷径。
个人微信:18611208992。
还想看我的文章,就关注“亲爱的数据”。