 图文原创:谭婧
图文原创:谭婧
作为很少见的专注于“数据科学团队协作产品”的公司,较早入局的公司,和鲸科技创始人&CEO范向伟,回答了“亲爱的数据”几个问题,讲了讲他的所思所想。

问:数据科学团队协作产品是小众产品,从理念形成到坚定不移,大约在创业的什么时期?
和鲸科技创始人&CEO范向伟:和鲸前身是科赛网,2016年起,和拍拍贷、携程、百度合作过一系列算法比赛。我们看到,算法项目管理很难,不仅业务需求沟通成本很高,开发环境搭建、模型成果复用的难度大,而且,整个链条存在着惊人的浪费。
 一场比赛平均有500人参与,里面不乏顶尖高校的研究生和头部企业的专职数据科学家,选手会提交大约1000个模型,但绝大多数的模型,最终都得不到用的机会。而且从模型开发,模型评价,到模型落地,环节断裂。
一场比赛平均有500人参与,里面不乏顶尖高校的研究生和头部企业的专职数据科学家,选手会提交大约1000个模型,但绝大多数的模型,最终都得不到用的机会。而且从模型开发,模型评价,到模型落地,环节断裂。
总之就是,效率很低。
那时候,我们看到的协同工具组合,普遍是发邮件+FTP+Jupyter+互不兼容的开源框架+难以复现的模型文件+无法访问的数据库环境。
条件如此简陋,我称之为“科学家开拖拉机”的尴尬局面。
看到痛点后,2016年底,很多现象不断验证判断,我内心澎湃。我和团队认为改变的时机到了。
开源工具的发展,已经迈过了替代能力的临界点。互联网公司的数据科学部门,默认建模工具的选项已经是Python,而不是SAS、MATLAB。以前,吴恩达的机器学习在线课程在用MATLAB,2016年之后就改成了Python。
同时,我们观察GitHub、GitLab、Atlassian都进入了发展的快速通道,这三家公司主打的价值主张,都是软件工程的协同化,他们当时一年的收入增速有3倍左右,是很惊人的增长速度。
我们形成了一个很朴素的想法:把数据工具开源化、开发工具协同化这两个趋势结合起来做,也就是GitLab & GitHub for Data Science。
回首那一时期,有很多事情发生。
美国硅谷著名投资机构A16Z对Github下了重注;
Atlassian是增长效率最高的SaaS公司;
Databricks和Dataiku开始进入企业级市场。
国内和北美在数据科学这件事情上有时间差,三年,五年?我不知道。
但是,那时候我们内心笃定:方向很靠谱,很正确。
 问:怎么理解“协作”?
问:怎么理解“协作”?
和鲸科技创始人&CEO范向伟:痛点并不是明摆着的,往往是踩了坑才发现问题。
刚开始创业的时候,因为有数据竞赛社区,令我们较早看到协作的价值。亲眼所见,最为深刻,我们立刻决定往协作这个方向来做数据科学平台。
“协作”是一个新鲜词。
十年前,用微博的时候,很难想象微信的玩法。
十年前,用Outlook、Excel,也很难想象Slack、Airtable。
同样的道理,直到有的人看到Deepnote、Hex、Dataiku的灵魂,观念开始变了。
协同的数据科学平台,可以让企业不同部门的员工,都参与到数据科学的开发工作之中,有人做开发,有人做报表,有人提问题,有人找数据,有人运维算力。
模型规模化生产的时候,截图、开会、打电话都很难解决不了问题,别人也看不到模型问题的前因后果。
而建模工作,恰恰是一个存在着很多疑问和Bug的复杂工作。

“协同”这个词,太抽象,国内还比较少用,常说“业务人员也要参与模型开发”,“模型资产能被不同业务复用”,本质就是业务需求驱动数据协同。
虽然高管都重视,但是,数据和业务部门就是很难合作起来。一个说业务语言,一个说研发语言,语种都不同。
大部分情况下,一个环节出现停摆,整个链条就会卡住。协同就成为了瓶颈。
问:有的机器学习平台厂商,声称也有数据科学团队协作产品功能,你怎么看待这个现象?哪种更有竞争力?
和鲸科技创始人&CEO范向伟:我们认为一个理想的协同工具,还有很长的路要走,和鲸也只是在路上,因为数据科学的业务落地、能力普及,还在很早期的阶段,进度条可能只到了5%。
协同的定位也不是和鲸的原创,这个事儿也远非和鲸当初想得那么直观,我们发现协同的复杂性,比软件工程的协同还要高一个数量级。
SaaS的协同都不好设计,不好实现,因为企业级的工作场景,其协同的流程逻辑是非线性的,没有一个特定的起点,也没有一个特定的终点,其相关的要素是不断延展、不断循环、不断叠加的,很容易变成功能堆积的毛线团,产品团队需要有很强的直觉,来判断协同的边界在哪里、主线在哪里、杠杆在哪里。
企业就是由人、事、物的协同流程构成的,所以协同是刚需,也是痛点。不会有哪个和生产力相关的SaaS或者PaaS,会说协同和自己没关系,这个就像说用户体验和自己没关系。
由于和鲸的社区场景和赛事场景的协同深度是很少见的,和鲸在协同这件事情上,走到了很深的无人区。
在企业场景,任何事儿想要做成SaaS,都很不容易,都深不见底。看似简单的场景,做深了都是在考验产品团队的世界观。
问:数据科学团队协作产品可能有一个痛点,大老板并不是很在乎数据科学家团队的体验,这是一个误解,还是确有此事?有遇到这个情况吗?如何应对?
和鲸科技创始人&CEO范向伟:老板确实不在乎数据科学家的体验,因为老板并不理解“什么叫做数据科学家的体验”,也不需要理解。


当然更多的情况下,我们还是在跟CIO、CDO打交道,我们讨论的主题是,数据团队如果没有好的协同工具,最优秀的人才更容易流失,因为拿不到需要的数据,价值没有被看到。
而且业务部门的管理者也会否定数据团队的价值,因为数据团队很贵。ROI在哪里?离开了协同工具,怎样让业务管理者看到数据团队的ROI?
一个流程有哪些浪费,人们很难意识到,除非体验到了更好的流程。
所以,我们不会做很多的说服工作,而是会培养尽可能多的产品用户,陪伴着他们成长,成为企业数据科学工作的骨干。只要他们开发的模型有价值,就是产品最好的广告。
问:有哪些生意经?
和鲸科技创始人&CEO范向伟:刚刚起步我们就有心理准备,很长的赛道、很厚的场景、很高的天花板,打持久战。想要在这个赛道活下来,和鲸这样的创业公司,必须要构建一套独特的竞争策略。
企业换生产力平台的代价很高,创业公司的产品会被重视吗?
我们的规划是“曲线救国”。
先在比赛和社区的场景打磨产品,形成领先的用户体验。
先面向高校与科研机构销售产品,把协同的能力打磨透,成为市面上最好的协同产品后,再进入政府机构和主流企业,实现可复制的产品销售收入。
也就是和鲸的三级火箭策略:社区&比赛→高校&科研→政府&企业。
可以这样归纳和鲸的发展模式:
为了把高度复杂的协同产品做好,和鲸运营的社区业务,成为了产品研发的高保真度的实验室,从而能够高强度、高频率地验证用户需求和产品设计,和鲸顺着协同产品成熟度的发展,借助社区业务的用户触达优势,逐步进入更高门槛、更高复杂度的细分市场。
后来证明,这是复杂但是行之有效的策略。
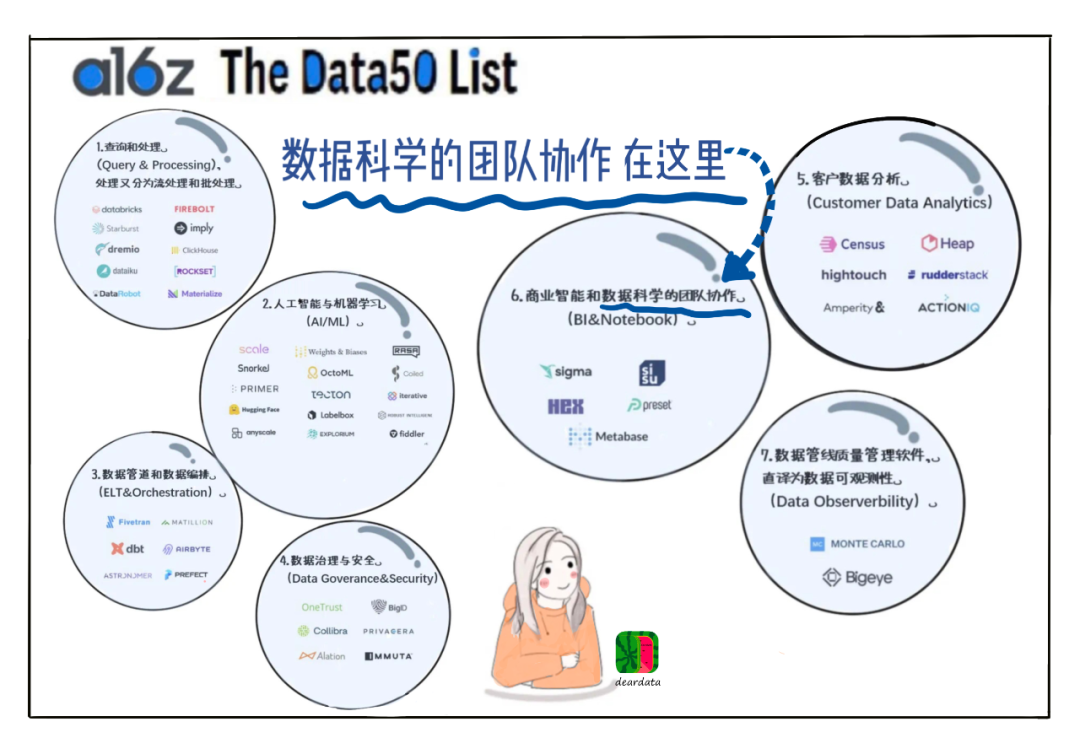
除了和鲸之外,国内并没有第二家公司,能够拿出一个“协同的数据科学平台”。
和鲸同时卡住了一个生产力工具的三个核心变量:用户基数、迭代效率和标杆客户。
这三个变量构成了环环相扣、互为因果的增强回路。
和鲸尝试封锁住协同这个赛道:高频的赛事→高活跃的社区→高强度的迭代→良好的协同产品体验→头部客户的最佳实践→社区用户的普及。
回过头看,这就是精益创业的原则和复利效应的原则的结合,尊重用户,敬畏无常,日拱一卒,水滴石穿,这个过程确实很辛苦,我们也没有想到,还真的能够坚持下来。
2020年,在某国家部委的竞标中,客户比选了国内几乎所有的供应商,经过极其严格的多轮论证,最终选择了和鲸的产品。在此之后我们意识到,我们的路可能走通了。
 问:在数据科学团队协作产品这个细分赛道里,中美差异是什么?
问:在数据科学团队协作产品这个细分赛道里,中美差异是什么?
和鲸科技创始人&CEO范向伟:技术形态上没有差异,但是,在客户需求上,有很大的差异。
中国的数字化环境很复杂,CBD、城乡结合部、地铁,同时开工,是一个大型施工现场。
企业目前是信息化、数字化、智能化三个周期的叠加,这个对于产品的定位、研发的节奏、市场的拓展,都是很大的考验,一不小心就会变成一个定制化开发的公司,自己也不知道自己到底在做什么。
具体到数据科学协同上,北美企业的综合能力,目前在全球范围还是遥遥领先的。
Databricks和Dataiku的营收规模、产品能力都在很高的水平,北美有足够大的市场需求、资本规模和IT生态系统,这个飞轮的运转速度惊人。
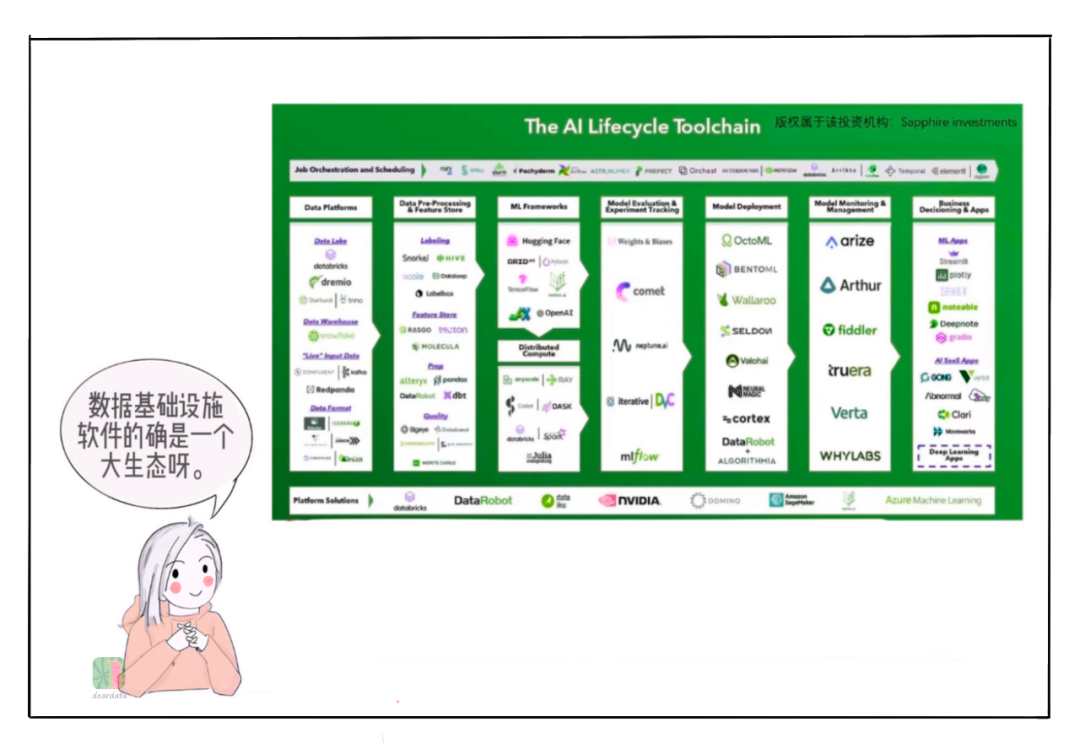
而且,美国的数据工具生态系统,分工的精细化堪比清明上河图,几十个生态位,有的位置有几十家企业。中国不少企业把开源技术直接拿来打包,产品形态高度雷同,缺少分工,缺少定位,缺少积累,突然出现了巨大的市场需求,只能眉毛胡子一把抓。
中国几乎没有细分定位的生存土壤,这也给了中国的数据工具一个独特机会,一旦能够顶住中国市场的巨大压力,就能跑通标准化产品在中国企业市场的PMF(这在中国非常困难)。
个人认为海外的竞品未来很难达到同样的生存能力。2B(企业级服务)软件的本质,还是效率和ROI。
虽然中国的2B市场环境很折磨人,但是,磨炼了中国企业。九死一生,厚积薄发。经历磨难可能是中国数据工具企业在这个时代的命运。
问:对你来说,相对 “恒久不变”的产品力是什么?
和鲸科技创始人&CEO范向伟:对于企业来说,软件的速度、功能,这些当然都很重要。然而,数据科学的实质不是只一个技术问题、业务问题,还是一个管理问题、经营问题。
怎样借助数字化能力,帮助公司实现更好的生存?
数据科学的协同产品的实质,就是一个关于企业的ROI和竞争力的问题。
这些年,很多商学院会新建数据科学专业,计算机学院则更多会建人工智能专业。这两个学科的课程内容有些接近,但是定位不同。一个关注经济效益,一个关注工程效率。
领先的企业是把数据科学当做一个杠杆、一个枢纽来看待的,是能够用数据科学的关联能力,把整个企业的资产、流程、指标串联起来,构建起一个经营效率爬坡的良性循环。这是一个很难实现的转变。
苦尽甘来,得到的效果是很惊人的。

问:数据科学团队协作产品令投资人最不理解的地方是什么?
和鲸科技创始人&CEO范向伟:常被投资人问到,数据科学到底是什么,和BI、AI、数据中台是什么关系?协同这个事儿有什么壁垒,为什么只有和鲸一家公司在做,阿里、百度、华为做不出来吗?
创业中,我们逐渐发现,很多科技公司,尤其是资源多的团队,反而没有耐心。指标的考核与约束太多,很难长期锚定一个“不收敛的复杂问题”,短期做不出结果,项目可能就会被砍掉,精力要放在快速见效的地方。
竞争很激烈,但是有效的竞争并不多,多数的竞争对手只是顺带做做,目的是给一个大型集成平台增加一个组件。
(完)
ONE MORE THING

(完)
更多阅读
AI框架系列:
DPU系列:
2. 永远不要投资DPU?
其他:
3. 隐私计算:消失的人工智能 “法外之地”
4. 售前,航空母舰,交付,皮划艇:银行的AI模型上线有多难?
5. AI芯片公司:拿下“超级石油”,助力地质模拟和人工智能
6. 两大榜单揭晓啦,2021年中国高性能计算机性能TOP100+国际人工智能性能排行榜AIPerf500
7. “重型卡车自动驾驶,无量产,则无意义”赢彻科技CTO杨睿刚博士观点
漫画系列
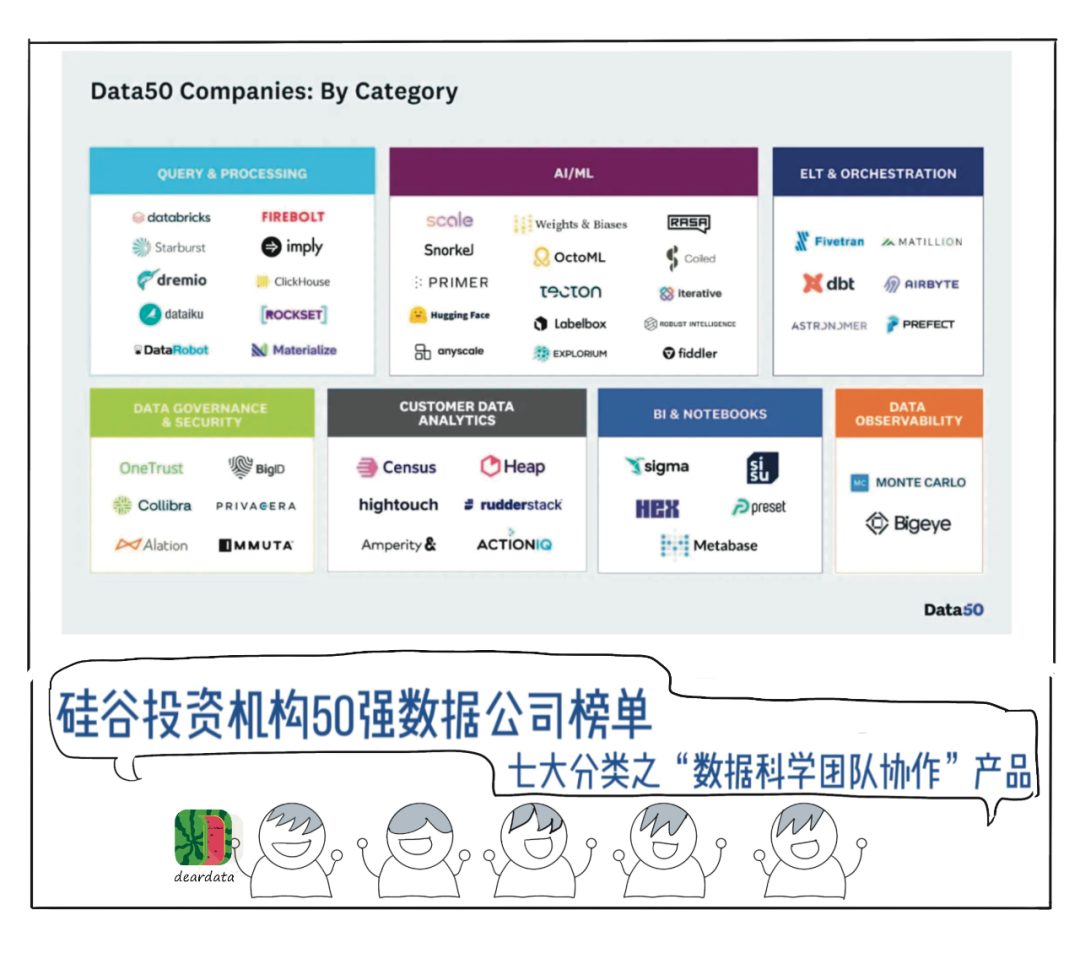
1. 万字大稿深度解读硅谷风投A16Z“50强”数据公司榜单
4. AI for Science这事,到底“科学不科学”?

最后,再介绍一下主编自己吧,
我是谭婧,科技和科普题材作者。
为了在时代中发现故事,
我围追科技大神,堵截科技公司。
偶尔写小说,画漫画。
生命短暂,不走捷径。
个人微信:18611208992。
还想看我的文章,就关注“亲爱的数据”。