文章目录
Paper: Attention-guided Network for Ghost-free High Dynamic Range Imaging
Code: https://github.com/liuzhen03/AHDRNet
一、背景
目前,高动态范围成像算法面临的主要挑战是:用于合成HDR图像的多帧LDR图像之间存在物体位移,大幅度运动的对齐比较困难,从而导致合成后的HDR中存在伪影。提出AHDRNet的主要目的就是利用注意力机制引导合成,避免HDR中出现伪影。
二、模型架构
模型整体结构由input、Attention network、Merging network、output四部分组成,如下图所示(标注的红色数字为通道数):
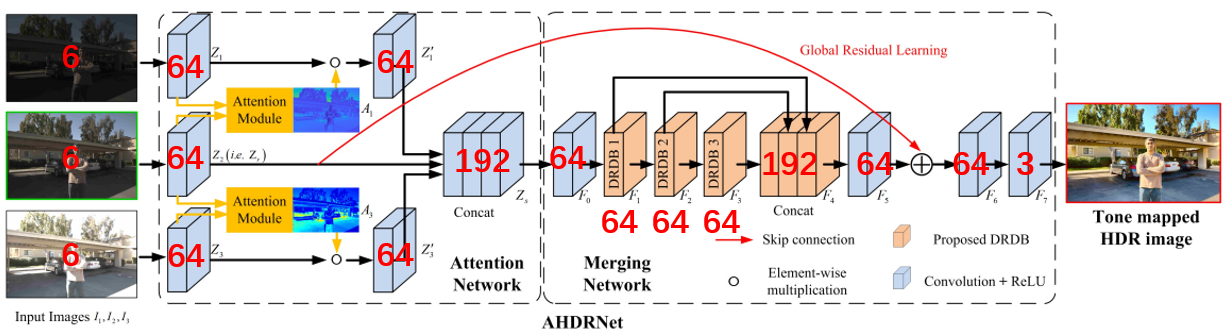
- 输入为什么是6通道?
文献[1]中提出:LDR图像有助于鉴别有噪声和饱和区域,在HDR domain的LDR图像则有助于检测对齐。其实比较好理解,对于前者,三张LDR图像的曝光时间不同,短帧由于曝光时间短因此噪声水平高,同时长帧由于曝光时间长很容易出现饱和区域,在以中间帧为参考帧的情况下,可以识别出噪声和饱和区域;对于后者,将LDR通过下式(gamma变换并除以曝光时间)转换至HDR domain,此时三张LDR的亮度基本一致,因此有助于检测是否对齐。

那么网络最终的输入就是不同曝光下的LDR ( I i I_i Ii) 与对应的HDR domain ( H i H_i Hi)在通道维度上的concat,文中表示为 X i X_i Xi,因此为6通道。

2.1 Attention Module
注意力模块是AHDRNet的核心之一,其输入为参考帧与短帧或长帧经过卷积后的features,分别记为 Z r ∈ R C × H × W Z_r\in \mathbb {R}^{C \times H \times W} Zr∈RC×H×W和 Z i ∈ R C × H × W Z_i\in \mathbb {R}^{C \times H \times W} Zi∈RC×H×W,经过concat后的通道数为2C,通过两个卷积和sigmoid输出attention map A i ∈ R C × H × W A_i\in \mathbb {R}^{C \times H \times W} Ai∈RC×H×W,最终的输出 Z i ′ = Z i ⊙ A i Z_i^{\prime}=Z_i\odot A_i Zi′=Zi⊙Ai

由于 Z i Z_i Zi可以是短帧或长帧的features,因此得到的attention map的作用也不同,这里分情况讨论:
- Z i Z_i Zi为短帧:直觉上来说,在合成HDR时,需要短帧中的亮区来弥补参考帧和长帧的饱和区域中的细节,那么attention map中对应短帧亮区的激活值应该较大
- Z i Z_i Zi为长帧:同理,在合成HDR时,需要长帧中的暗区来弥补参考帧和短帧的暗区中的细节,英雌attention map中对应长帧暗区的激活值应该较大
以上两种情况在论文中给出了相应的示例:

另外,注意力模块还能抑制非参考帧中与参考帧不一致的区域,从而缓解HDR中的伪影现象,文中也给出了示例:

2.2 DRDB
考虑到局部区域存在移动物体的遮挡或者饱和,无法从LDR图像获取足够的细节信息来合成HDR,合成网络需要更大的感受野来产生细节信息。
为了扩大感受野,将RDB模块中卷积替换为空洞卷积,形成DRDB模块,通过特征复用能够保留更多的细节信息,有利于丰富HDR中的细节。

2.3 Global residual learning
全局残差学习基本上是image to image任务的标配。在HDR合成任务中,输出的HDR图像与参考帧高度相关,使用全局残差连接使网络学习两者的残差,能够降低学习难度。
2.4 Training loss
文献[1]中提出:由于HDR图像通常在tonemapping之后显示,在经过tonemapping后的图像上训练网络比直接在HDR域训练更有效。因此,论文中的loss不是直接对HDR图像计算L1,而是通过u-law压缩动态范围后再计算L1。


三、实验
3.1 消融实验

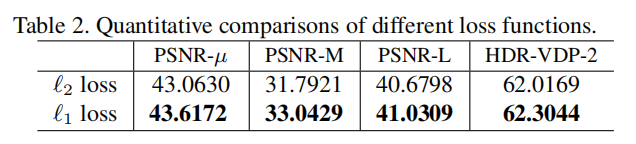
3.2 L1 / L2 loss
文献[2]中指出L1 loss比L2 loss更具有保留细节的能力,论文中也做了对比试验,可以看到使用L1 loss训练的模型在各项指标上均优于L2 loss
四、参考文献
[1] Deep high dynamic range imaging of dynamic scenes(基于深度学习的HDR成像算法开山之作)
[2] Loss functions for image restoration with neural networks
[3] Attention-guided Network for Ghost-free High Dynamic Range Imaging