年底了模型定制服务比较多,文章更新也比较慢。最近热点是四川省大学生金融科技建模大赛。好几个学生在咨询我如何提升模型性能。当然他们都很优秀,我能帮到的地方很有限,就写篇文章统一答复大家。下面介绍一下模型竞赛内容。
比赛简介
一、赛事背景
新经济建设背景下,成都正加快推进国家西部金融中心建设,着力发展金融科技,提出《成都市金融科技发展规划(2020-2022年)》,建设成为具有国际影响力的区域金融科技中心。在四川省教育厅大力支持下,西南财经大学承办新财经竞赛——第三届“四川省大学生金融科技建模大赛”。
首届“四川省大学生金融科技建模大赛” 共有575名来自西南财经大学、电子科技大学、成都信息工程大学、西南交通大学、四川农业大学、四川大学、西华大学、成都师范学院、西安欧亚学院等11个省内外高校同学报名参赛。初赛排名前100的选手有52名本科生及48名研究生。可见大赛受众群体较为广泛,各阶段学生群体均参与积极。最终经过初赛和复赛激烈竞争,来自西南财经大学、成都信息工程大学、电子科技大学、四川大学、四川农业大学、成都东软学院六个高校的81位参赛选手分获一、二、三等奖。综合排名前10名同学受邀进入决赛答辩,角逐“新网银行特别奖”。
第二届大赛初赛阶段共有502人报名,327人实际提交代码,其中川内高校参赛人数为281人,川外高校参赛人数为46人,继首届大赛以来本届大赛发挥了较好的省际影响力。初赛参赛人数排名前十的高校为西南财经大学、四川农业大学,成都信息工程大学、电子科技大学、吉利学院、西华大学、四川大学、华东师范大学、上海交通大学、重庆邮电大学。初赛排名前50%的选手晋级复赛,覆盖25所高校和54个专业,马天昊等复赛综合成绩前75名的选手分获四川省一等奖、二等奖、三等奖。第二届大赛吸引了省内外众多本科生和研究生参加,均取得了非常优异的成绩。
本届“四川省大学生金融科技建模大赛”面向四川省内外高校全日制本科生及研究生,提出金融行业的风险管控问题,要求参赛选手利用脱敏数据,完成建模过程、呈现解决方案。通过赛事,参赛者能够触摸金融科技行业前沿课题,学以致用,培养解决实际问题的综合能力和知识应用能力。
二、赛题描述
基于客户的申请信息和贷款产品的信息运用统计或机器学习算法有效精准地识别用户的还款行为(是否提前还款)。申请信息包括脱敏的客户基本情况以及客户再该次借贷前的授信信息;贷款产品的信息包括该次借贷的产品的信息。本次比赛提供训练集和测试集。模型建立的最终目标是尽可能使得模型的还款预测接近真实的还款行为,模型的预测能力以测试集上的AUC值表现作为衡量标准。主办方通过未公布的测试集好坏标签计算参赛选手的模型AUC结果并排名。
本次比赛所有数据均为脱敏数据,由四川新网银行提供。
三、赛程安排
大赛主办方将提供结果提交平台,平台语言不限。比赛全过程,选手需将比赛代码和预测后的结果提交至平台。
大赛由报名、初赛、复赛、评审、决赛五个环节组成。
(1)大赛报名:(9月26日—11月13日)
大赛将于9月26日至11月13日开放报名系统,参赛选手于9月26日至11月6日期间需要在比赛平台完成注册,在平台中报名加入本次大赛(注册报名方式具体参照比赛官方交流群文件)。
(2)初赛:(10月25日—11月13日)
大赛正式启动,参赛选手开始比赛进程,从平台获取数据集及赛题。选手需在自有环境中完成建模和计算过程,但均需按平台要求提交比赛代码和建模结果,后台将根据提交的建模结果公布实时排名。初赛期间,选手每天有5次提交结果的机会。
(4)复赛:(11月15日—11月21日)
结果排名前50%参赛选手获得参加复赛的资格,进入复赛的选手需在复赛规定时段完成模型及代码优化并提交比赛平台。
(5)评审:(11月22日—11月24日)
由评委对代码规范性进行评分,并结合建模结果综合评判,评审出一、二、三等奖选手。同时,一等奖选手可获得决赛参与资格,复赛评审结束后,决赛选手名单将及时在平台公布。
(6)决赛:(预计11月26日)
决赛将采用答辩的方式对参赛选手进行问答,具体形式另行通知。评委将针对选手的代码及模型进行专业提问。答辩过程考察选手建模思维和模型运用能力,综合考量后确定获特等奖名单。最终的评分将由复赛评审得分、答辩得分两部分加权得出。
(以上时间若有变动,以官方最新公布为准)
四、参赛规则
(1)参赛群体:四川省内外高校全日制本科生及研究生。
(2)报名方式:参赛选手需在比赛平台(https://match.creditscoring.cn)完成注册并报名加入比赛。
(3)参赛方式:
1)本次比赛为个人参赛。
2)参赛选手需填写学校、年级、学号、姓名、手机号等信息报名比赛,报名成功后可参与比赛。
五、评选规则
(1)评审过程中以作品的科学性、先进性、现实意义和实用价值为基本评判标准。
(2)评审中综合考虑本(专)科生、硕士研究生在学识水平和科研能力上的差异。
(3)所有符合资格的参赛选手在大赛各环节截止日期前所提交的作品将会得到评审。对于任何在截止日期之后提交的作品大赛组织方将不予以评审,同时,主办方不对任何因电脑、互联网、移动网络故障而造成的参赛作品损坏、缺失、提交延时等后果承担责任。
(4)初赛阶段根据选手排名经正态变换后的值计算成绩。
进入复赛阶段的选手,评委根据评审要求对其提交的代码进行评分,复赛成绩为:80%复赛排名成绩+20%代码成绩,复赛排名成绩计算方式与初赛阶段计算方式相同。
获一等奖的参赛选手中排名靠前者受邀进入决赛进行答辩,竞争“新网银行特别奖”。
对于进入决赛阶段的选手,评委将在决赛现场根据决赛评审规则评定得出答辩成绩,决赛成绩为:60%复赛成绩 + 40%答辩成绩,其中答辩成绩由各评委打分的平均数得出。
(5)评委对作品的评审结果一旦给出则为最终结果,评审将不对作品给出反馈意见。
(6)以大赛专用数据的成果为主要评分标准,解释权归大赛组委会所有。
六、奖项设置
(1)基础奖项
一等奖:复赛成绩前15%,颁发获奖证书
二等奖:复赛成绩前15-30%,颁发获奖证书
三等奖:复赛成绩前30-50%,颁发获奖证书
(2)“新网银行”特别奖
新网银行特等奖:第一名,奖金6000元
新网银行杰出奖:第二名,奖金4000元
新网银行荣誉奖:第三名,奖金3000元
新网银行优胜奖:第四至十名,奖金1000元
七、参赛协议
1.参赛作品必须保证其原创性,作品不得违反任何中华人民共和国的有关法律,不侵犯任何第三方知识产权或者其他权利;一经发现或经权利人提出并查证,大赛组织方将取消其参赛资格。
2.有其他以下情况的,大赛组织方可以取消参赛者参赛资格及成绩:
(1)提交的应用内容不完整,或提交任何虚假信息;
(2)违背中华人民共和国相关法律法规;
(3)涉嫌作弊行为,侵犯他人知识产权;
(4)提交的作品包含不健康、淫秽、色情或诽谤任何第三方的内容;
(5)提交的作品包含其他赛事组委会认为不适当的内容;
八、主办方权利
(1)大赛组织方保留修改比赛各环节时间包括但不限于作品提交截止日期、线下活动日期的权利。大赛组织方有权随时暂停或终止比赛。
(2)大赛组织方保留调整比赛各阶段入选团队数量的权利(包含决赛),以及调整奖项设置及奖金数额的权利。
(3)大赛组织方保留收回或拒绝授予某个特定团队奖项的权利。
九、组委会
主办单位:四川省教育厅
承办单位:西南财经大学
协办单位:
西南财经大学金融学院
西南财经大学教务处
西南财经大学金融建模协会
支持单位:四川新网银行
十一、其他相关消息
主办方将在竞赛信息群内发布指导手册以及解答竞赛相关问题。指导手册内包含一些基本问题的回答以及相关培训课程。
十二、赛题数据
数据提交:参赛者需提交为格式为.xlsx(excel格式)的预测结果,包含测试集的ID(列名指定为ID)和预测分数(列名指定为LABEL)
本次提供数据分为以下几部分:
训练集:trainX.xlsx
训练集标签:trainY.xlsx
测试集:testX.xlsx
提交样例:
ID LABEL
1 0.475614509
2 0.126453848
3 0.523678444
4 0.475614509
5 0.126453848
6 0.523678444
… ...
排名
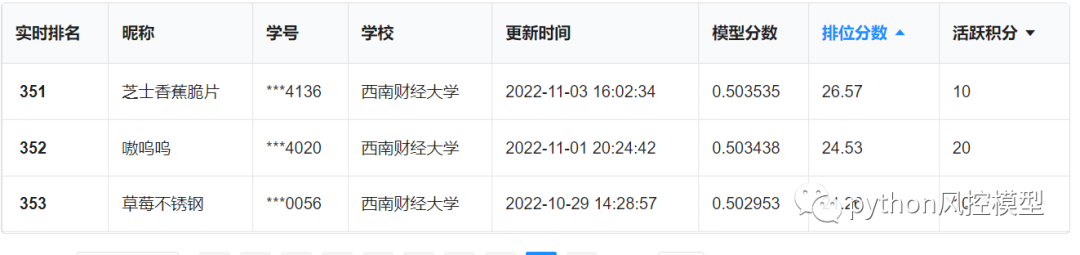
目前有353支团队参赛,第一名是电子科技大学的洛天依,AUC=0.84,活跃积分270,看来提交次数不是最多的。第二名是西南财经大学的lz不给,AUC=0.839,活跃积分720分。看来第二名实验次数比第一名多,但仍然没有超越第一名,祝再接再厉,再创新高!最后批次参赛者AUC只有0.5左右,看来是初步接触机器学习,还没有经验,打酱油玩。

。。。。。。。。。。。。。
看到学生们如此优异成绩,不禁感叹长江后浪推前浪,希望大家再接再厉,再创辉煌!
上述就是官方对模型的介绍,接下来,我用半个小时实验初步复现了模型。实验的模型性能是线下,没有线上提交。根据和几个同学交流,线上线下差异不大,差异在百分之一到千分之二左右。
关于模型AUC提升,我有以下建议:
1.描述性统计
古人云知己知彼百战百胜。大家在描述性统计多花时间,观察变量分布和特征,针对不同变量采用不同数据预处理方法,可以提升模型性能。
2.衍生变量
此数据集有205个变量,是非常适合做衍生变量的。新的衍生变量比原来变量可能更具有区分能力。

3.变量选择
此数据集有205个变量,但110个变量是多余的,没有价值意义。因此这些变量没有必要入模型训练。下图可见右边大量变量重要性接近0.

我之前负责过公司模型验证和审批,对变量降维特别严格,对冗余的模型特别厌恶。这和模型竞赛思路有很大差异。
例如下述变量,删除后,模型性能既不会下降,还可减少模型过度拟合。
jieju_subj_num
jieju_dubil_bal
jieju_mbank_prin
jieju_co_bank_prin
jieju_asset_flow_trans_bal
jieju_claim_bal
jieju_amc_bal
jieju_partner_int_rate_val
jieju_loan_oper_mode_cd
jieju_asset_tran_status_cd
jieju_transfr_resrc_pool_num
jieju_guarnt_num
jieju_adv_money_bal
jieju_normal_prin
jieju_ovdue_prin
jieju_ovdue_int_bal
jieju_ovdue_punish_int_amt
jieju_ovdue_comp_int_amt
jieju_cgb_ovdue_prin_bal
jieju_cgb_ovdue_int_bal
jieju_cgb_ovdue_punish_int_amt
jieju_cgb_ovdue_comp_int_amt
jieju_prin_ovdue_days
jieju_int_ovdue_days
jieju_curr_ovdue_term
jieju_cust_dubil_bal
jieju_cust_ovdue_prin
jieju_cust_ovdue_int_bal
jieju_cust_ovdue_punish_int_amt
jieju_cust_ovdue_comp_int_amt
jieju_expd_term
jieju_reorg_ind
jieju_brw_rpay_ind
jieju_repay_freq_cd
jieju_clear_int_period_cd
jieju_pay_mode_cd
jieju_today_init_elev_level_class_cd
jieju_int_rate_adj_mode_cd
jieju_int_rate_float_mode_cd
jieju_int_rate_float_ratio
jieju_comp_ind
jieju_non_accrued_cate_cd
jieju_non_accrued_ind
jieju_impairmt_ind
jieju_wrtoff_ind
jieju_wrtoff_cate_cd
jieju_wrtoff_prin_amt
jieju_wrtoff_int_amt
jieju_wrtoff_punish_int_amt
jieju_unite_bank_wrtoff_prin_amt
jieju_unite_bank_wrtoff_int_amt
jieju_unite_bank_wrtoff_pnsh_int_amt
jieju_belong_org_num
jieju_dubil_lvl_cd
jieju_margn_rule_num
jieju_mercht_num
jieju_int_subj_num
jieju_oper_teller
jieju_memo
kehu_cust_nm_pny
kehu_cust_region_cd
kehu_city_cls_cd
kehu_cert_cate_cd
kehu_nation_cd
kehu_sch_local_region_county_cd
kehu_rsdnt_ind
kehu_emp_ind
kehu_rel_pty_ind
kehu_cust_stat_cd
kehu_cust_mgr_id
shouxin_belong_org_num
shouxin_circl_ind
shouxin_limit_ctrl_ind
shouxin_use_shared_ind
shouxin_lmt_lvl_cd
4.多算法比较
不同算法得到模型性能是不一样的。大家多算法比较,择优选择建模算法。
用集成树算法,模型AUC在0.8093260496988347。
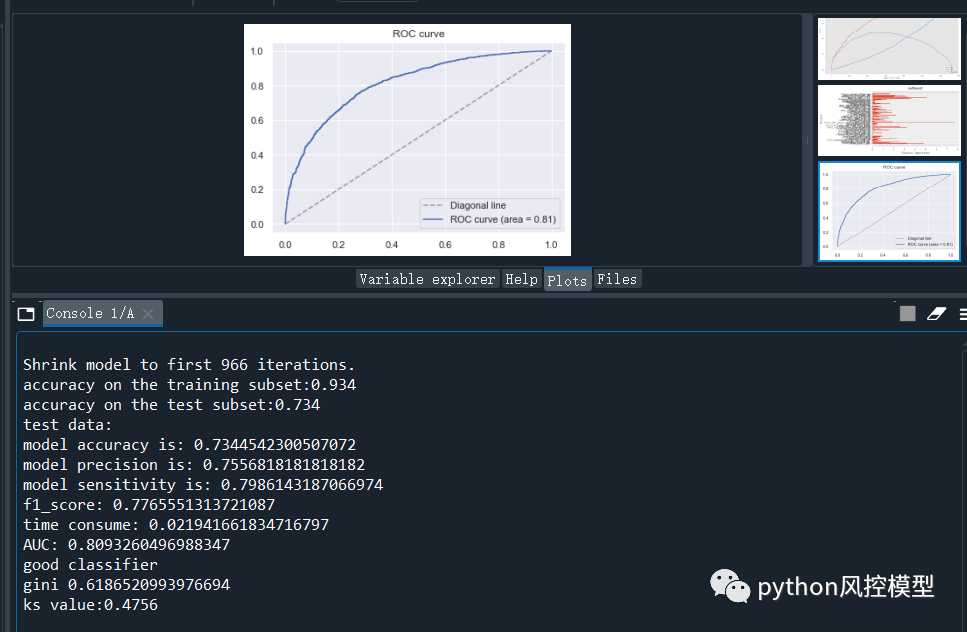
用逻辑回归评分卡算法,模型AUC在0.8129137554999519左右。

4.调参
调参上多做功夫。之前有同学调参参数太少,还用的gridsearchcv。gridsearchcv比较耗时间,大家可以尝试其他高效率工具。参数也多测试几个,模型提升空间更大。
以集成树算法为例,模型AUC在0.8093260496988347,模型调参后,AUC可达到0.8117677801362324。树的深度一般在6-8之间;学习率不要太高,在0-0.1之间实验就好。
调参给模型AUC提升非常有限,我建议大家在数据清洗,数据预处理,衍生变量,变量筛选等基础环节做好工作。
对于主办方建议
1.公开变量名
我们可以看出新网银行可能出于合规考虑,把变量真实业务名称都屏蔽了。其实这不利于模型竞赛,不方便大家衍生变量处理。lending club,home credit数据集都展示了真实变量。作者认为我们通过建模和数据挖掘就是为了挖掘重要变量,然后反馈业务线。如果变量名被屏蔽了,模型竞赛没有太大真实意义,期待主办方可以有更开放行为。
2.模型竞赛评选规则优化
模型的预测能力以测试集上的AUC值表现作为衡量标准。这样衡量标准太单一。我建议在AUC基础上加上模型预测时间,模型维度另外两个指标,让模型更有实际意义。如果仅参考AUC,那么选手可以制造大量衍生变量提升模型AUC。高纬度模型对企业来说难以应用。变量太多,模型在部署环节和验证环节是个灾难。如果线上线下模型分数不一致,模型变量成千上万,找出模型故障原因犹如大海捞针。这都是我们工作中亲身的经历和教训!
今年最新的四川省大学生金融科技建模大赛就为大家介绍到这里,如果大家对消费金融的风控模型技术感兴趣,想在这次竞赛中提升模型性能,欢迎了解系列课
。《python金融风控评分卡模型和数据分析微专业课(加强版)》课程对描述性统计,变量选择,衍生变量,调参,stacking融合模型,非平衡数据处理,评分卡,xgboost,lightgbm,catboost建模都有详细描述。在模型竞赛时候可以提升模型性能。
如果大家以后期望在金融行业工作,下述课程也会带来很多帮助,节省大量自我探索时间。
版权声明:文章来自公众号(python风控模型),未经许可,不得抄袭。遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。