背景
随着金融科技初创企业的兴起,过去 5 年中出现了许多新的消费信贷机构,与传统银行展开竞争。他们通常瞄准银行认为规模太小或因金融危机期间发生的后期损失而不得不削减贷款的细分市场。通俗的讲就是消费金融公司瞄准了银行的次贷市场。
这些新的消费金融公司的主要竞争优势之一是技术,包括IT技术和机器学习建模技术,AI人脸识别和语音识别技术。
大型银行相对传统,保守,技术变革动力小。银行主要客户是信用较好客户,大力推动的是信用卡来鼓励用户超前消费。
例如,英国商业贷款机构 iwoca使用来自关联公司账户、增值税申报表甚至 ebay 或亚马逊上的销售交易的信息来确定新贷款。英国消费贷款公司 lendable以在几分钟内完成个人信用贷款,而不是传统银行需要几天或几周漫长审批的时间。
英国商业贷款机构 iwoca和 lendable,国内消费金融公司例如招联,兴业消金,借呗,微粒贷,拍拍贷都会使用类似下面的风控系统,实现对大部分客户自动化审批贷款。

凭借快速和自动决策引擎,他们使用自动和快速的信用风险模型来评估风险。
什么是信用评分卡

我们大多数人都熟悉信用评分的概念,这是一个代表个人信用度的数值。像银行这样的所有信贷机构都有复杂的信用模型。这些模型会读取用户的各种信息,如工资、信用历史记录,年龄,性别和多头借贷等因素,然后训练模型,最后通过复杂数学计算输出客户的信用评分。信用评分卡模型可以输出用户信用分或违约概率。
信用评分卡就是其中一种信用模型,它是最常见的信用模型之一。信用评分卡是基于逻辑回归算法。它对大家来说相对容易理解,而且它已经存在了几十年,因此开发过程是标准的,广为人知。
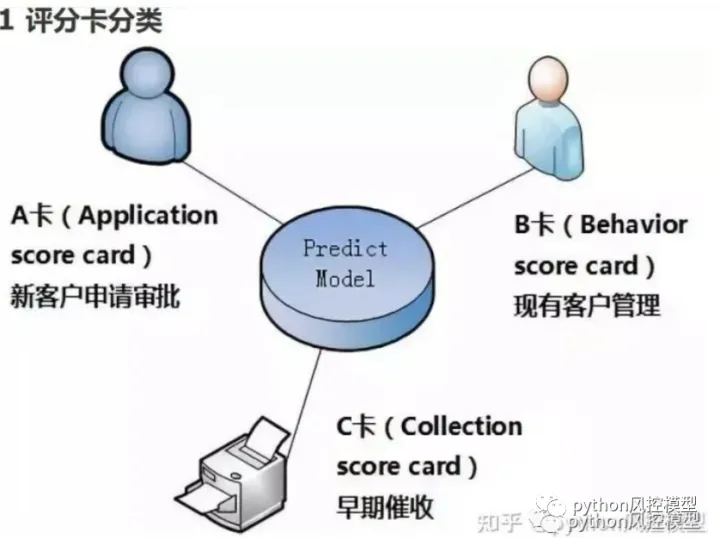
信用评分卡也有几个子类模型,常见的有A,B,C卡。
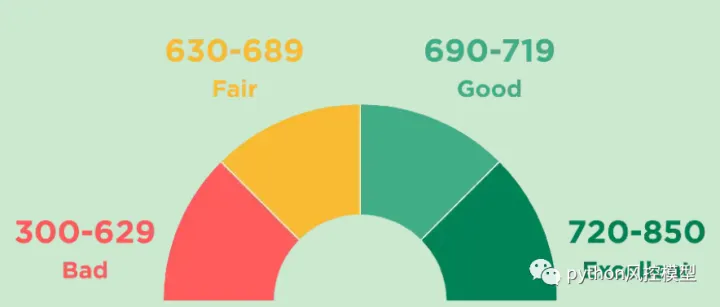
但需要注意的是,不同机构的分数范围可能不同,较低分数的拒绝申请的截止点因贷款人而异,甚至可能在同一贷款人但不同产品中有所不同.
建立信用记分卡
目标变量通常采用二进制形式,根据数据的不同,可以为 0 表示好客户(放贷客户),可以为 1 表示违约客户或逾期 90 天付款的客户(拒绝放贷客户)。
第 1 步:数据探索和清理
所有模型拟合中的必要步骤,但由于它不是特定于构建信用评分卡模型,因此我们将跳过此部分。不要忘记将数据集也分成训练和测试数据集,即train和test数据集。
第 2 步:数据转换——证据权重法
然后我们需要使用证据权重 (WoE) 方法转换所有自变量(如年龄、收入等)。该方法根据每个组级别的好申请人与差申请人的比例,衡量分组区分好坏风险的“强度”,并试图找到自变量与目标变量之间的单调关系。
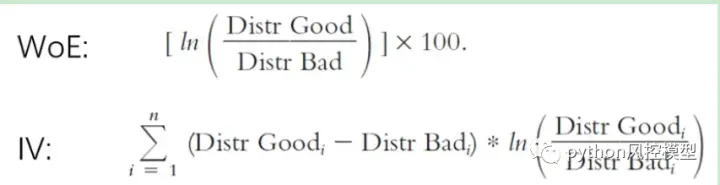
连续变量的转换步骤:
- 将数据分成 bin,通常大约 10 个,最多 20 个(bin箱数并非越多越好,也并非越少越好,根据数据集特征决定分箱数量)
- 计算好事件的百分比和坏事件的百分比
- 取自然对数计算WOE
- 用计算出的 WOE 值替换原始数据
如果自变量是分类变量,则跳过上面的 1,然后执行其余步骤。
Python 中的示例:
在将您的数据放入箱子中,并对每个箱子的好坏计数进行分组后,您的数据可能看起来类似于下面的方框。WoE 可以使用下面的代码为每个 bin 组计算。负值表示特定分组中不良申请人的比例高于良好申请人。
import pandas as pd
import numpy as np
# dummy data as example
age = ['18 to 25','26 to 35','36 to 45','46 to 60','>= 60']
df = pd.DataFrame(age, columns=['Age Group'])
df['counts'] = [31234, 30293, 29384, 30192, 27394]
df['bad'] = [4920, 4123, 3784, 2608, 1479]
df['good'] = df.counts - df.bad
# calculate WOE
df['total_distri'] = df.counts/sum(df.counts)
df['bad_distri'] = df.bad/sum(df.bad)
df['good_distri'] = df.good/sum(df.good)
df['WOE'] = np.log(df.good_distri / df.bad_distri)
df['WOE%'] = df.WOE * 100
在转换结束时,如果您有 20 个自变量开始,那么您现在将有 20 个 WOE_variablename 列可用于下一步。
使用 WoE 转换的好处:
- 它有助于与逻辑回归中使用的对数几率建立严格的线性关系
- 它可以处理缺失值,因为它们可以合并在一起
- 可以处理异常值或极值,因为它们也被分箱,并且输入模型拟合的值是 WoE 转换值而不是原始极值
- 它还处理分类值,因此不需要虚拟变量
第 3 步:使用信息值进行特征选择
Information Value (IV) 来自信息论,它衡量自变量的预测能力,这对特征选择很有用。执行特征选择以确定是否有必要在模型中包含所有特征是一种很好的做法,大多数时候我们希望消除弱特征,因为通常首选更简单的模型。
根据 Siddiqi (2006),按照惯例,信用评分中 IV 统计量的值可以解释如下

根据Toby老师多年建模经验,A卡中iv>0.5变量很少见,但在B卡和C卡中,常出现iv值大于0.5变量,当然我们也要审核这些强变量的合理性。
Python 中的示例:

继续前面的示例,这里我们计算“年龄”的 IV 约为 0.15,这意味着年龄具有“中等预测能力”,因此我们将继续进行模型拟合。IV 分数小于 0.02 的变量应该被删除。
备注:根据Toby老师多年建模经验年龄变量在不同数据集会有不同iv值。在很多数据集年龄变量iv值非常低。这里只是举例说明,同学不要死记硬背。
第 4 步:模型拟合和解释结果
现在我们使用我们新转换的训练数据集的 WoE 来拟合逻辑回归模型。
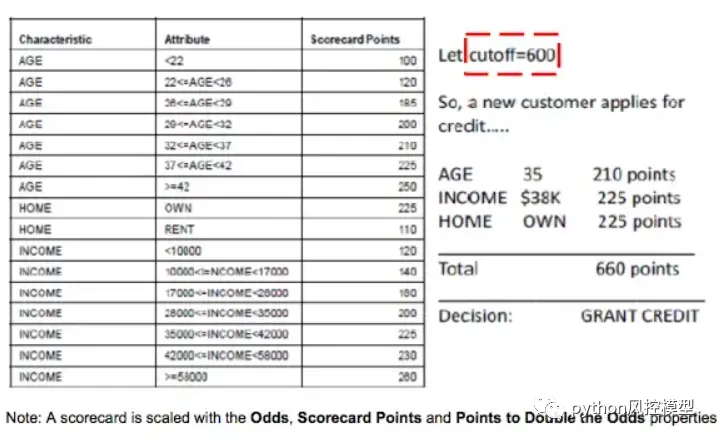
将模型缩放为记分卡时,我们需要模型拟合的逻辑回归系数以及转换后的 WoE 值。我们还需要将模型的分数从对数赔率单位转换为积分系统。
对于每个自变量Xi,其对应的得分为:
Score_i= (βi × WoE_i + α/n) × Factor + Offset/n
其中:
βi — 变量 Xi 的逻辑回归系数
α — 逻辑回归截距
WoE — 变量 Xi 的证据权重
n — 模型中自变量 Xi 的数量
Factor,Offset — 称为缩放参数,其中
- factor = pdo/ln(2)
- Offset = Target Score — (Factor × ln(Target Odds))

对于上面的示例,我们选择将目标分数设置为 600,这意味着好客户与坏客户的赔率是 50 比 1 ,而增加 20 意味着赔率翻倍。请注意,缩放比例的选择不会影响记分卡的预测强度。
最终的总分是基于自变量输入值的所有分数的总和。然后,贷方将根据建模的总分和截止点(根据其他信用违约模型设置)评估收到的申请。
Total Score = Σ Score_i
信用评分分卡简介就谈到这里,实际上,信用评分卡模型细节非常多,由于篇幅有限,我只能简单概述。真实模型开发并非线性,而是一个复杂迭代过程。
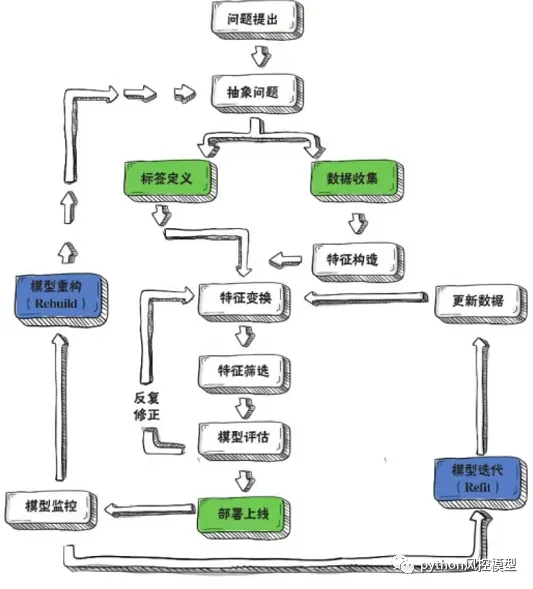
如果大家对信用评分卡各种细节感兴趣,欢迎大家收藏《python信用评分卡建模(附代码)》,会满足你对信用评分卡所有好奇和疑问。
信用评分卡模型分析(基于Python)
版权声明:文章来自公众号(python风控模型),未经许可,不得抄袭。遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。