前言:记录了总6w字的面经知识点,文章中的知识点若想深入了解,可以点击链接学习。由于文本太多,按类型分开。这一篇是 网络 常问问题总结,有帮助的可以收藏。
1. TCP与UDP的区别
| 区别 |
UDP |
TCP |
| 是否连接 |
不连接 |
面向连接 |
| 是否可靠 |
不可靠 |
可靠传输(传输过程中会丢失,但会重发)使用流量控制和拥塞控制 |
| 连接对象个数 |
支持一对一,一对多,多对一,多对多交互通信。 |
仅支持一对一通信。 |
| 传输方式 |
面向报文 |
面向字节流 |
| 数据边界 |
保存数据边界 |
不保存数据边界 |
| 速度 |
速度快 |
速度慢 |
| 发送消耗 |
轻量级(因为 UDP 传输的信息中不承担任何间接创造连接,保证交货或秩序的的信息。这也反应在包头大小。) |
重量级 |
| 首部开销 |
首部开销小,仅8个字节 |
首部开销大,最小20字节,最大60字节。 |
| 有序性 |
不提供有序性的保证 |
TCP 保证了消息的有序性,即使到达客户端顺序不同,TCP 也会排序。 |
| 应用场景 |
IP电话,视频会议,直播,以及FPS竞技类的使用UDP帧同步。 |
要求可靠传输的应用例如文件传输,以及MMO类的TCP状态同步。 |
2. 帧同步与状态同步
2.1 帧同步
让每个客户端在相同的时刻发送游戏数据到服务端,服务器广播分发所有客户端的数据,然后客户端根据服务端发来的数据做出相应的逻辑处理,保证每个客户端在同一时刻所有的数据都是一致同步的。客户端做游戏逻辑处理。
核心思想: 相同的输入+相同的时机=相同的表现
同步的实现:
- 同步随机种子
- 客户端上传当前逻辑帧的操作(帧索引+游戏操作)
- 服务器广播客户端操作
帧同步可以说同步的是操作(输入)-服务器收到每个客户端当前的输入,将数据广播到所有客户端,客户端针对其他客户端的操作,做出逻辑处理,使得所有客户端在每一时刻的数据都是一致的。
优点:
- 单次同步数据很小,传输速率快,因为数据的逻辑处理主要是在客户端,服务器只起到分发同步的作用。
- 服务端压力小。
- 更容易实现录像功能,因为是帧同步,每一个时刻的帧序列都有记录,可以很好的还原游戏过程。
- 开发效率高,可以部分当作单机游戏来开发。
- 游戏精准度更高,能呈现更好的打击感、音效、特效等反馈、以及动作的反馈、动作的频率也可以更高。
- 流量消耗小,因为传输的数据量更少。大部分逻辑处理都在客户端处理好了。
缺点:
1.反外挂能力弱。因为主要的数据处理是在客户端。
2.网络要求更高,因为是是实时同步,一旦客户端网络延迟过高,很容易影响用户体验,产生网络抖动。
3.断线重连难度很大,因为一旦掉线,本地数据丢失了,需要从服务器逐帧来读取游戏进度,直到与当前游戏进度一直。如果直接从当前游戏进度开始进行同步,是很容易出现数据错误的。
2.2 状态同步
客户端将数据发送到服务端,服务端根据每个客户端发来的数据做出处理,再将处理完的数据广播发送到所有客户端,客户端根据数据进行数据表现。服务端做游戏逻辑处理。
优点:
- 反外挂能力强,因为大部分数据处理都是在服务端。
- 网络要求不高。
- 玩家可以随时加入到一个开始的战局,只需要同步当前战局内的所有玩家当前的状态即可。
缺点:
- 传输数据大,传输速度慢。因为客户端会将大量数据传输给服务端,再由服务端进行逻辑处理,再分发给所有客户端。
- 服务端压力大
- 回放较难还原
2.3 区别

状态同步:比较多的MMO
帧同步:Dota,红警 RTS(战略)类游戏,Moba类。
3. OSI七层模型有哪些,每一层的作用

应用层:为应用程序提供服务
表示层:数据格式转化,兼容并且适合传输的格式(起到翻译的作用)、 数据加密。
会话层:建立、管理和维护会话,它主要负责数据传输中设置和维护 网络中两台设备之间的通信连接。
传输层:建立、管理和维护端到端的连接,
网络层:IP选址和路由选择
数据链路层:分帧,确定mac地址
物理层:真正的物理设备传输数据,物理层将2进制数据利用电脉冲 在物理媒介上实现比特流的传输。
4. TCP/IP协议栈各个层次及分别的功能

应用层: 用来处理特定的应用,针对不同的应用提供了不同的协议, 例如进行文件传输时用到的FTP协议,发送email用到的 SMTP等。对应协议:FTP、HTTP、SMTP、DNS等。
传输层: 主要功能是提供应用程序之间的通信,这一层主要是 TCP/UDP协议。
网络层: 处理分组在网络中的活动,例如路由选择和转发等,这一 层主要包括IP协议、ARP、ICMP协议等。
网络接口层:这是协议栈的最低层,对应OSI的物理层和数据链路层, 主要完成数据帧的实际发送和接收。
5. TCP的三握四挥
5.1 三次握手
5.1.1 概念
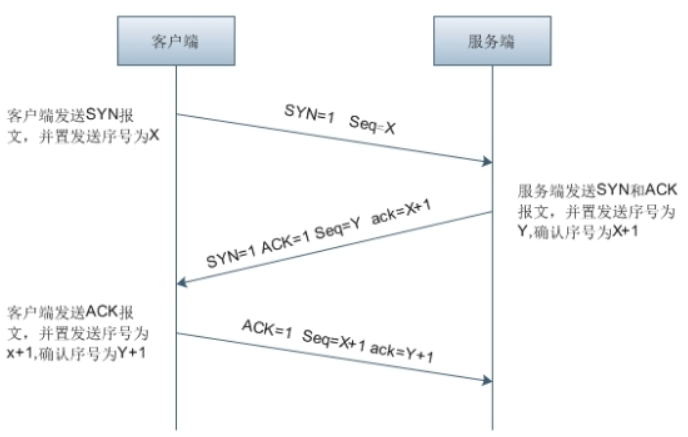
- 首先 Client 端发送连接请求报文。
- Server 段接收链接后回复ACK 报文,并为这次连接分配资源。
- Client 端接收到 ACK 报文后也向 Server 段发生 ACK 报文,并分配资源,这样 TCP 连接就建立了。
小结:
三次握手的关键是要确认对方收到了自己的数据包,这个目标就是通过 “确认号(Ack)”字段实现的。计算机会记录下自己发送的数据包序号 Seq,待收到对方的数据包后,检测 “确认号(Ack)字段”,看 Ack = Seq + 1 是否成立,如果成立说明对方 正确收到了自己的数据包。
5.1.2 为什么要三次握手(常问)
1. 如果只有一次握手,Client不能确定与Server的单向连接,更加不能确定Server与Client单向连接;
2. 如果只有两次握手,Client确定与Server的单向连接,但是Sevrer不能确定与Client的单向连接;
3. 只有三次握手,Client与Server才能相互确认双向连接,实现双方的数据传输。
5.2 四次挥手
5.2.1 概念

- Client 发送一个 FIN,用来关闭 Client 到 Server 的数据传送, Client 进行 FIN_WAIT_1 状态。
- Server 收到FIN 后,发送一个 ACK 到 Client,Server 进入CLOSE_WAIT 状态,Client收到ACK,进入FIN_WAIT_2 状态。
- Server 发送一个 FIN,用来关闭 Server 到Client 的数据传送,Server 进入 LAST_ACK 状态。
- Client 收到 FIN 后,Client 进入 TIM_WAIT 状态,发送 ACK 给Server,Server 进入 CLOSED 状态,TIME-WAIT一般为2个MSL(报文最长寿命),如果在这个时间段内没有收到服务端的超时重发,说明客户端发过去的ACK服务端收到了并且已经关闭连接,客户端才进入CLOSED状态。完成四次握手。
5.2.2 为什么要四次挥手(常问)
服务端在收到客户端的释放报文时,可能自己的数据报还没有发完,所以不会直接返回FIN+ACK,而只先返回一个ACK,表示自己收到了客户端的释放请求(第二次挥手)。等到服务端报文发完以后,在返回FIN(第三次挥手)。
那么,我们是否可以在服务器端数据传送完成后,再返回FIN+ACK呢?中间就可以省略一次ACK了?(省略第二次挥手)
试想一下,如果服务端还有很多数据需要传送,耗时长,客户端在发送释放报文后,一直没有收到反馈,那么他会认为服务端没有收到我的FIN,因此就会不停的重发FIN。(第一次挥手)
所以最好的办法就是,客户端发送FIN,服务端回复ACK,表示我已经收到了,但是我在忙,你等等,我处理完成后联系你。服务端数据传送完成后,发送FIN给客户端,客户端再回复ACK。
详细请看:
5.2.3 为什么不能直接CLOSE状态,必须要先设置TIME_WAIT(2个MSL)状态
理论上,四个报文都发送完毕,就可以直接进入CLOSE状态了,但是可能网络是不可靠的,有可能客户端发送给服务的的最后一个ACK丢失。一段时间后,服务端收不到最后的ACK,认为客户端没有收到FIN请求(第三次挥手),进行超时重发,但是客户端已经关闭了,不会给响应。(理论上来说 服务器超时重发5次后,就会主动断开连接,这样数据既不会丢失也不会错乱,是可以的,但是这样不符合可靠连接。)
此时若旧的客户端直接CLOSE没有TIME_WAIT状态,新的客户端建立与服务端之间的连接,如果新连接和老连接的端口是一样的。假设老连接还有一些数据,因为网络或者其他原因,一直滞留没有发送成功,新连接建立后,就直接发送到新连接里面去了,造成数据的紊乱,因此,我们需要2*MSL的TIMEWAIT状态,让滞留在网络中的报文失效,再去建立新的连接。
所以简单来说TIME_WAIT状态中的2个MSL(TIME_WAIT状态作用)
- 用来重发可能丢失(第四次挥手)的ACK报文
- 避免服务器有了新的数据需要发送给客户端。
6. TCP为什么稳定
与 乱序重排、应答确认、报文重传 和 流量控制 四种机制有关。
6.1 乱序重排
由于网络或“多线程”等因素,接收方收到的数据段很可能是乱序的,不过因为每个 TCP 封装都有序号,接收方重组起来非常容易。
6.2 应答确认
计算机会记录下自己发送的数据包序号 Seq,待收到对方的数据包后,检测 “确认号(Ack)字段”,看 Ack = Seq + 1 是否成立,如果成立说明对方正确收到了自己的数据包。
不过为了提高效率,客户端一次有可能发送上千条数据,根据服务端返回客户端的确认号,判断是否为这上千条中最后一条的序列号+1,即发送5000条数据包,判断服务器发送给客户端的Ack是否为5001,等式成立即为接受完整。
6.3 报文重传
TCP 的报文重传有两种独立的办法。一种是超时重传,一种是快速重传。
6.3.1 超时重传
因为网速 并不是稳定的,传输时的每个报文的延时也不一样。TCP 会根据报文的往返时间(RTT)自动调整超时重传时间(RTO)。发送方每发一个报文段都会开始计时,如果时间超过 RTO 还没收到这个报文段的确认,就重传该报文段。
6.3.2 快速重传
接收方收到序号X 后,回复X+1的确认号,希望收到X+1序号报文,但没有收到,却收到了比X+1还要大的报文,就连续发出确认号X+1的报文,如果发送方连续三次收到重复的确认号,立即重发该报文段,而不管是否超时。
6.4 流量控制
首先要明白一点,应用程序不论发送还是接收数据,都会先把数 据放入缓冲区,再从缓冲区中发出或读取数据。这个缓冲区大小,反映了应用程序一次能处理数据的能力。如果接收方应用程序处理速度比发送方的发送速度慢,就会造成接 收方缓冲区“溢出”。实际上,发送方发送速度和接收方处理速度很难一致。 这就需要 window 来调整了。 TCP 在三次握手建立连接时,会协商双方缓冲区 window 大小。如果因为接收方处理速度较慢,接收方会通过 window 告知发送方,实现动态调整,避免“溢出”。
所谓流量控制就是让发送发送速率不要过快,让接收方来得及接 收。利用滑动窗口机制就可以实施流量控制。原理这就是运用 TCP 报文段中的窗口大小字段来控制,发送方的发送窗口不可以大于接收方发回的窗口大小。
考虑一种特殊的情况,就是接收方若没有缓存足够使用,就会发送零窗口大小的报文,此时发送放将发送窗口设置为0,停止发送数据。之后接收方有足够的缓存,发送了非零窗口大小的报文,但是这个报文在中途丢失的,那么发送方的发送窗口就一直为零导致死锁。解决这个问题,TCP 为每一个连接设置一个持续计时(persistence timer)。只要 TCP 的一方收到对方的零窗口通知,就启动该计时器,周期性的发送一个零窗口探测报文段。对方就在确认这个报文的时候给出现在的窗口大小。
7. TCP 拥塞控制
拥塞的发生是因为路由器缓存溢出,拥塞会导致丢包,但丢包不一定触发拥塞。拥塞控制是快速传输的基础。一个拥塞控制算法一般包括慢启动算法、拥塞避免算法、快速重传算法、快速恢复算法四部分。
8. 断线重连
当检测到客户端断线时,断开当前客户端 Socket;重新根据IP和 端口号重建新的 Socket。当连接上服务器网关后,携带 token,向服务器发送断线重连协议。
9. 进程和线程
进程:一个应用程序相当于一个进程,是操作系统资源分配的基本单位。 一个进程拥有多个线程。更安全。
线程:是程序的实际执行者。线程是操作系统能够进行运算调度的最小单位。它被包含在进程之中,一个线程只有一个进程。效率高。
线程是进程的一个实体,是CPU调度和分派的基本单位,它是比进程更小的能独立运行的基本单位.线程自己基本上不拥有系统资源,只拥有一点在运行中必不可少的资源(如程序计数器,一组寄存器和栈),但是它可与同属一个进程的其他的线程共享进程所拥有的全部资源.
9.1 什么是线程争用
因为进程中可存在多个线程,线程间均可访问主线程资源。所以若线程间争抢资源,可能导致数据混乱。
9.2 如何解决线程争用
只要避免同一时间只有一个线程来访问共享数据就OK了。
1.Monitor(监控器)
2.Lock,是对Monitor的封装,简单易用。
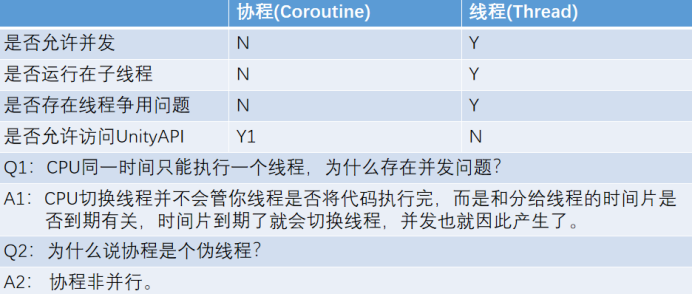
9.3 线程和协程的区别是什么
9.4 前台线程 和 后台线程
一:线程有两种:前台线程和后台线程。
区别是:应用程序必须运行完所有的前台线程才可以退出;
而对于后台线程,应用程序则可以不考虑其是否已经运行完毕而直接退出,所有的后台线程在应用程序退出时都会自动结束。
二:.net环境使用Thread建立的线程默认情况下是前台线程,即线程属性IsBackground=false
在进程中,只要有一个前台线程未退出,进程就不会终止。主线程就是一个前台线程。
而后台线程不管线程是否结束,只要所有的前台线程都退出(包括正常退出和异常退出)后,进程就会自动终止。
三:使用方法
一般后台线程用于处理时间较短的任务,如在一个Web服务器中可以利用后台线程来处理客户端发过来的请求信息。
而前台线程一般用于处理需要长时间等待的任务,如在Web服务器中的监听客户端请求的程序,或是定时对某些系统资源进行扫描的程序。
四:注意
在调用Start方法之前设置线程的类型,否则一但线程运行,将无法改变其类型。
9.5 针对于效率与安全方面,两者区别
线程执行开销小,但是不利于资源的管理和保护。线程适合在SMP机器(双CPU系统)上运行。
进程执行开销大,但是能够很好的进行资源管理和保护。进程 可以跨机器前移。
使用场景:
- 对资源的管理和保护要求高,不限制开销和效率时,使用多进程。对算力要求高的使用多进程,因为 大量计算用进程,因为操作系统分配的算力是按进程分配的,一个进程的内即使有再多的线程,也只能得到一个CPU核心的算力
- 要求效率高,频繁切换时,资源的保护管理要求不是很高时,使用多线程。
10. 序列化与反序列化(xml、json、protobuf)
序列化 :将对象状态转化为可保持或者可传输的格式的过程。
反序列化 :将已经序列化过后的数据恢复成原先对象的过程。
扩展:序列化的多种方案
XML
指可扩展标记语言(eXtensible Markup Language)。是一种通用和重量级的数据交换格式。以文本结构存储。
优点:
- 格式更为标准和统一
- 更容易和其它系统进行远程交互
- 数据共享比较方便
缺点:
相比于JSON,由于需要成对的数据标签,数据更加的冗余。 而JSON使用键值对,压缩了数据空间并且更加可读。
JSON
是一种通用和轻量级的数据交换格式。以文本结构存储。
优点:
1 简单易用开发成本低
2 跨语言
3 轻量级数据交换
4 非冗长性(对比xml标签简单括号闭环)
缺点:
1 体积大,影响高并发
2 无版本检查,自己做兼容
3 片段的创建和验证过程比一般的XML复杂
4 缺乏命名空间导致信息混合
5 没有XML格式这么推广的深入人心和使用广泛,没有XML那么通用性
总结:最简单最通用的应用协议,使用广泛,开发效率高,性能相对较低,维护成本较高。
Protobuf
protocol buffer是Google的一种独立和轻量级的数据交换格式。以二进制结构进行存储。
Protobuf是一种以有效并可扩展的格式编码结构化数据的方式。
优点
1 跨平台多语言,可自定义数据结构。
2 字段被编号,新添加的字段不影响老结构。解决了向后兼容问题。
3 序列化后体积相比json和xml很小,适合网络传输。
4 序列化反序列化速度很快,快于Json的处理速度。
5 自动化生成代码,简单易用。
6 二进制消息,效率高,性能高。
7 Netty等框架集成了该协议,提供了编×××提高开发效率。
缺点
1 二进制格式,可读性差(抓包dump后的数据很难看懂)
2 对象冗余,字段很多,生成的类较大,占用空间。
3 默认不具备动态特性(可以通过动态定义生成消息类型或者动态编译支持)
总结:简单快速上手,高效兼容性强,维护成本较高。
三者比较:
1、json:一般的web项目中,最流行的主要还是json。因为浏览器对于json数据支持非常好,有很多内建的函数支持。
2、xml:在webservice中应用最为广泛,但是相比于json,它的数据更加冗余,因为需要成对的闭合标签。json使用了键值对的方式,不仅压缩了一定的数据空间,同时也具有可读性。
3、protobuf:是后起之秀,是谷歌开源的一种数据格式,适合高性能,对响应速度有要求的数据传输场景。因为profobuf是二进制数据格式,需要编码和解码。数据本身不具有可读性。因此只能反序列化之后得到真正可读的数据。
11. 黏包
11.1 概念
多个独立的包黏在一块
11.2 考虑时机
Tcp连续发送消息的时候,会出现消息一起发送过来的问题。
11.3 产生原因
1.发送端需要等缓冲区满才发送出去,造成粘包(发送端出现粘包)
2.接收端没有及时接收缓冲区包数据,造成一次性接收多个包,出现粘包(接收端出现粘包)
11.4 如何解决
1.缓冲区过大造成了粘包,所以在发送/接收消息时先将消息的长度作为消息的一部分发出去,这样接收方就可以根据接收到的消息长度来动态定义缓冲区的大小。(这种方法就是所谓的自定义协议,这种方法是最常用的)
2.对发送的数据进行处理,每条消息的首尾加上特殊字符,然后再把要发送的所有消息放入一个字符串中,最后将这个字符串发送出去,接收方接收到这个字符串之后,再通过特殊标记操作字符串,把每条消息截出来。(这种方法只适合数据量较小的情况)
12. Socket的封包、拆包
12.1 基于TCP的通信程序需要封包、拆包的原因
TCP是流协议,所谓流,就是没有界限的一串数据。但是程序中却有多种不同的数据包,那就很可能会出现如上所说的粘包问题,所以就需要在发送端封包,在接收端拆包。
12.2 那么如何封包、拆包
答:封包就是给一段数据加上包头或者包尾。比如说我们上面为解决粘包所使用的两种方法,其实就是封包与拆包的具体实现。
13. 并发/并行/异步/同步
13.1 并发
一个处理器“同时”处理多个任务,CPU通过时间片切换轮流执行不同的任务。
进程的调度实际上就是实现了并发,相当于吃饭吃一半,停下来去接电话,接完再吃饭,只是过程很快,做到了像同时运行。
13.2 并行
“多个”处理器或者多核处理器同时处理多个任务,两个线程互不抢占CPU资源,可以同时执行任务。
13.3 异步
比如我上手机店买手机,服务员去仓库拿手机,要花一分钟,我趁这一分钟才去买水喝,然后回来刚好拿到手机。
这个过程就是当程序遇到阻塞,需要等待的时候,程序会先执行其他任务,完成任务后回来,刚好上个任务也已经完成,可以提高效率。
13.4 同步
比如我上手机店买手机,服务员去仓库拿手机,要花一分钟,我等了一分钟后拿到手机才去买水喝。这个过程就是当程序遇到阻塞,需要等待的时候,程序会一直等待阻塞解除或者运行完后才进行下一步执行。
14. 找到unity中卡顿的点
用unity中的unity profiler 去定位,开启deep操作,开启后非常消耗性能,可以找到一个大致的范围,然后关闭deep,自己编写一个costume profiler 去缩小范围。
15. Protobuf
protobuf是一种可序列化的数据交换格式。于此相同的还有json,xml。
用途:
用于通讯协议、存储数据。网络信息的传输,游戏数据的存储。
优点:
- 传输数据量小,扩展性很好
- 解包封包更小。序列化后的大小是json的1/10是xml1/20;
- 不限制─种语言或一个平台,高效;因为protobuf数据交换格式的代码是开源的
- 且传输数据可空(如果一个字段没有传值,会自动跳过该字段)。
- 性能好,效率高-存储消耗小,转化效率高。
- 预生产代码,无需编写解析代码。同行json/xml,在一个平台使用时,需要使用解析包,解析完后还需要通过反射实例化出对应的类,消耗特别大;而protobuf,如果项目使用c#进行编码,则会生成对应的c#代码,其转化生成都是protobuf自己去完成,不需要专门的去编写。
- 兼容性很好。如果生产的协议文件已经更新了,而本地的文件没有更新,依旧不影响使用,只不过碰到新的字段会自动跳过。
缺点:
- 相对于json数据交换格式,protobuf没有json更容易读和调试。
- 对象冗余,字段多,生成类较大,占用空间,且维护成本高。
性能解析:
JSON数据传输的数据格式:{"id":1," name":"liu ", "age":18, "level":9}有很多冗余数据:如{} id一样的字段名符等,而真正需要传输的数据其实就是1,liu,18,9;如果进行优化,不传字段名,则需要用分隔符将每个字段分割开进行传输,但是一旦两个字段名的数据数据格式一样,一旦一个字段没有传值就会出问题。而本来不用传值的字段这个时候也需要传入null或者0来避免问题的出现而导致资源的浪费。
protobuf的独特之举:
- tag技术
将编号左移3位|(或运算)数据类型编码(int32-0 double-1 string/byte/repeated-2)。
(编号右边)
如果用一个字节来存储字段-则最大编码只能到15:00001111>>3:01111000(第一位一般不占值),大于15了就需要两个宇节来存储字段了。
2. Varint编码:
普通整型4字节:00000000 00000000 00000000 00000000
如果发现其中一个字节没有占用,则会自动省略,最少使用一个字节表示。127是一个字节表示的最大整型数值。
protobuf的底层原理:
- protobuf传输数据的格式是tag以及对应tag的value值,而且数据value是可空的;对于value数据tag的生成:在定义协议字段时,需要明确字段的变量类型,以及编号,而tag的值就是编号左移3位|(或)数据类型编码。
- Varint编码:当传输的数据为int型时,会从最高位去检查当前字节的各个位是否被占用,如果没有被占用则省略,最多可以将4字节的int型用1字节去表示。
详细请看:
16. 网络抖动
什么是网络抖动
如果网络发生拥塞,排队延迟将影响端到端的延迟,并导致通过同一连接传输的分组延迟各不相同,而抖动,就是用来描述这样一延迟变化的程度。
他是网络延时变化,最大延迟与最小延迟的时间差;
如最大延迟是20毫秒,最小延迟为5毫秒,那么网络抖动就是15毫秒,它主要标识一个网络的稳定性。
抖动造成原因
如果网络发生拥塞,排队延迟将影响端到端的延迟,并导致通过同一连接传输的分组延迟各不相同;
当网络设备无法发送相同数据的流量,因此他们的数据包缓冲区已满并开始丢弃数据包。如果端点上的网络没有干扰,则每个数据包都会到达。
但是,如果端点缓冲区满了,会使数据包到达的越来越晚,导致抖动。
而抖动,就是用来描述这样一延迟变化的程度。因此,抖动对于实时性的传输将会是一个重要参数,比如:VOIP,视频等。
解决方法
数据包接收端的抖动缓存;缓存指针队列对接收到的数据包进行排序后,将接收到的数据包插入抖动缓存指针队列的相应位置;
抖动缓存指针队列的出队线程定时器,以一定时间间隔触发出队线程,出队线程判断抖动缓存指针队列队头的数据包,是否应该在当前触发时刻出队,如果是,则将该数据包出队。
17. http与https的区别
HTTP协议以明文方式发送内容,不提供任何方式的数据加密。HTTP协议不适合传输一些敏感信息,比如:信用卡号、密码等支付信息。
https则是具有安全性的ssl加密传输协议。
http和https使用的是完全不同的连接方式,用的端口也不一样,前者是80,后者是443。并且https协议需要到ca申请证书。HTTPS协议是由SSL+HTTP协议构建的可进行加密传输、身份认证的网络协议,要比http协议安全。
HTTPS协议的主要作用可以分为两种:一种是建立一个信息安全通道,来保证数据传输的安全;另一种就是确认网站的真实性。HTTPS在HTTP的基础上加入了SSL协议,SSL依靠证书来验证服务器的身份,并为浏览器和服务器之间的通信加密。
希望此篇文章可以帮助到更多的同学