一提起Meta Avatar虚拟化身,常常有人吐槽它只有半截身子,看起来不自然。的确,尽管Quest整体VR体验优秀,但出于对硬件设计、成本的考虑,技术上依然有限制,比如不能准确追踪下半身,而这种限制也影响了早期的一些VR社交应用,比如《Rec Room》。

Quest不能追踪下半身,是因为头显不具备相应的传感器,而Meta也没有推出官方的体感追踪套件(比如PC VR头显可使用Vive Tracker)。Meta的策略,是尽可能简化VR的使用流程,如果为头显配备定位模块,无疑让设置过程更复杂,且硬件成本更高。为了满足用户对全身Avatar的需求,Meta不久前为Avatar加入了模拟的腿部运动,并通过Body Tracking API开放给开发者。
据了解,Meta Avatar将通过头、手三点的定位信息来推算下半身动作,这显然并不精准。拿《VRChat》来讲,虽然该应用中的虚拟化身有下半身,但并不能跟随用户下半身运动而变化,,意味着Avatar不能模拟自然下蹲、躺下等动作,如果用户在开启VR应用时摘下头显放在桌上或地上,VR内的Avatar可能会呈现奇怪的姿势,具有一定恐怖谷效应。

为了完善Avatar下半身模拟的效果,Meta研发了一种基于MLP架构的条件扩散模型:AGRoL,该模型宣称可根据稀疏的信号生成全身姿态,由于其运行速度足够快,因此也适合VR社交等在线多人应用。
关于AGRoL
Meta指出,随着AR/VR用户群增长,越来越多的人渴望能自然、精准控制的全身Avatar。然而,VR一体机在下半身追踪上具有一定局限,因为它只通过头显、手柄来定位,只能捕捉到少量、稀疏IMU的信号,而且通常仅用于定位和重建上半身部位,比如头部和手腕。想要定位下半身,通常需要额外的IMU模块,缺点是成本高、使用不方便。

简单来讲,Quest系统不能通过头显捕捉的信息准确的追踪下半身,而只能通过追踪上半身关节运动来提取有限的信息,用于合成下半身运动。也就是说,用算法来预测和模拟Avatar的下半身动作。通常,从头、手三点预测全身动作的算法依赖于生成模型,比如标准化流(Normalizing Flow),或是变分自编码器(VAE)。而在各类生成模型中,扩散模型开始在图像、视频生成方面取得不错的成果,尤其是条件扩散模型。

因此,Meta科研人员提出了一种全新的条件扩散模型:AGRoL(全称为“Avatar长腿”),该模型由简单的多层感知器架构(MLP)、运动数据调节方案组成,专门以稀疏信号为条件,根据上半身定位来生成全身姿态。据了解,这种只利用稀疏定位信息重建全身姿态的扩散模型,为市面上首例。

据称,AGRoL是专门为条件运动合成任务量身定制的,可预测出准确、流畅的全身运动。与常见的扩散架构相反,它基于紧凑型架构,可实时运行(在单个NVIDIA V100 GPU上运行时,计算过程仅6毫秒),因此可用于在线身体追踪应用,比如VR社交软件、多人VR游戏等等。
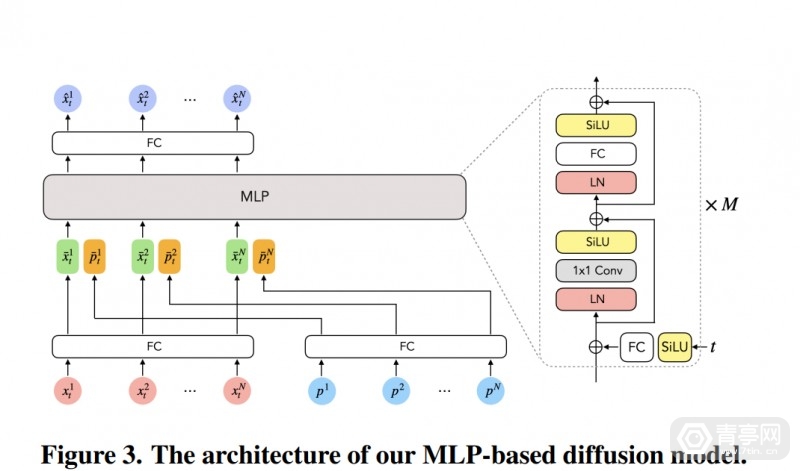
此外AGRoL提升了MLP网络性能,并超越了此前的方案,明显降低了抖动误差,因此和AvatarPoser等其他模型相比,ARGoL生成的动作更加平滑。此外,在追踪信号丢失的情况下,ARGoL的准确度下降不多,因此在追踪信号稀疏的情况下也能较准确的模拟运动。
不过,目前ARGoL方案可能出现地板穿透伪影,后续或许可以通过额外的物理约束,来改善该问题。
其他VR全身定位方案
除了预测算法外,VR也可以使用其他的全身动捕方案,比如:光学Marker、深度相机、RGB相机骨骼动作识别等等。相比之下,AGRoL虽然依靠预测而非准确追踪,但它的优势是成本低,用户无需购买甚至设置额外的硬件,因此用起来很方便。

除了AGRoL外,此前也有将人体运动数据与机器学习模型结合的方案,比如Standable。这是一种无摄像头全身追踪方案,主要是通过算法来模拟VR追踪不到的下肢(如骨盆、膝盖、腿部或关节处),其特点是校准流程轻量化,只需要确认眼部位置即可,此外支持复杂的动作模拟,比如蹲下、躺下、趴下、走路、慢跑等等。相比于Standable,AGRoL的优势是专为Quest打造,与硬件配合更好,尤其是实时运行能力强。

此前青亭网也曾报道多种VR全身定位方案,比如卡内基梅隆大学,在VR手柄上配备广角相机来追踪下半身,或是Meta此前提出的基于电磁原理的6D姿态追踪方案。值得注意的是,索尼在去年也推出了便携式全身动捕产品:Mocopi(售价360美元),未来也许和VR可以有很好的结合。参考:Meta