协同过滤常常被用于分辨某位特定顾客可能感兴趣的东西,这些结论来自于对其他相似顾客对哪些产品感兴趣的分析。协同过滤以其出色的速度和健壮性,在全球互联网领域炙手可热
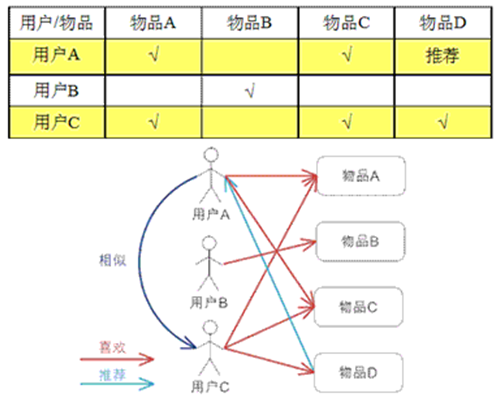
基于用户的协同过滤算法UserCF
基于用户的协同过滤,通过不同用户对物品的评分来评测用户之间的相似性,基于用户之间的相似性做出推荐。简单来讲就是:给用户推荐和他兴趣相似的其他用户喜欢的物品
基于物品的协同过滤算法ItemCF
基于item的协同过滤,通过用户对不同item的评分来评测item之间的相似性,基于item之间的相似性做出推荐。简单来讲就是:给用户推荐和他之前喜欢的物品相似的物品
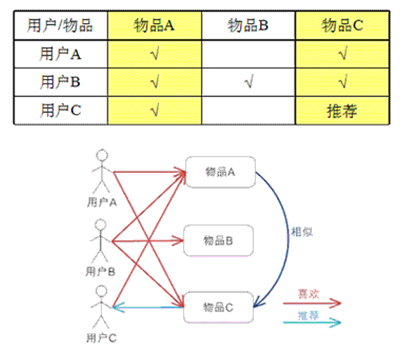
注:基于物品的协同过滤算法,是目前商用最广泛的推荐算法
案例:天池大数据竞赛
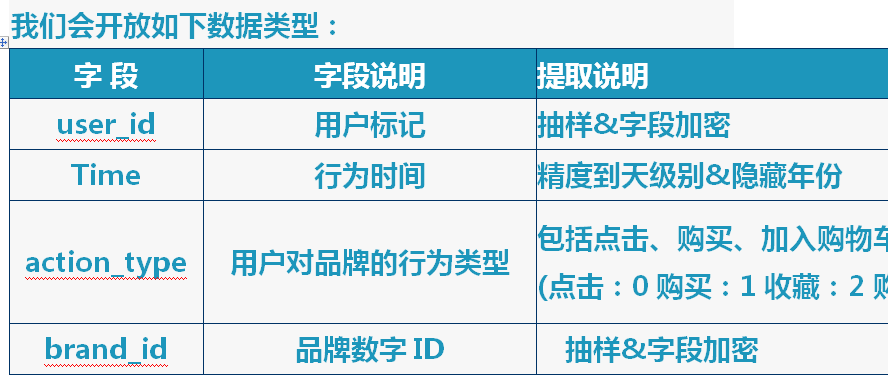
提供的数据量,涉及千万级天猫用户,万级天猫品牌,时间跨度4个月的行为记录。
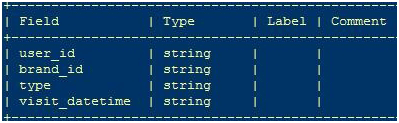
提供的训练数据在天池集群的表t_alibaba_bigdata_user_brand_total_1中,字段分别为:user_id,brand_id, type, visit_datetime。如图所示
用户4种行为类型(Type)对应代码分别为:
点击:0;购买:1;收藏:2;购物车:3
代码步骤:
- 去重
- 获取所有用户的喜欢矩阵:
|
I1
|
I2
|
I3
|
|
|
U1
|
|||
|
U2
|
- 获得所有物品之间的同现矩阵
- 两个矩阵相乘得到三维矩阵
- 三维矩阵的数据相加获得所有用户对所有物品的推荐值(二维矩阵)
- 按照推荐值降序排序。
工程结构:
Step1:
|
package com.laoxiao.mr.tianchi;
import java.io.IOException;
import java.util.Map;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
/**
* 去重复
* @author root
*
*/
public class Step1 {
public static boolean run(Configuration config,Map<String, String> paths){
try {
FileSystem fs =FileSystem.get(config);
Job job =Job.getInstance(config);
job.setJobName("step1");
job.setJarByClass(Step1.class);
job.setMapperClass(Step1_Mapper.class);
job.setReducerClass(Step1_Reducer.class);
//
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(NullWritable.class);
FileInputFormat.addInputPath(job, new Path(paths.get("Step1Input")));
Path outpath=new Path(paths.get("Step1Output"));
if(fs.exists(outpath)){
fs.delete(outpath,true);
}
FileOutputFormat.setOutputPath(job, outpath);
boolean f= job.waitForCompletion(true);
return f;
} catch (Exception e) {
e.printStackTrace();
}
return false;
}
static class Step1_Mapper extends Mapper<LongWritable, Text, Text, NullWritable>{
protected void map(LongWritable key, Text value,
Context context)
throws IOException, InterruptedException {
if(key.get()!=0){
context.write(value, NullWritable.get());
}
}
}
static class Step1_Reducer extends Reducer<Text, IntWritable, Text, NullWritable>{
protected void reduce(Text key, Iterable<IntWritable> i,
Context context)
throws IOException, InterruptedException {
context.write(key,NullWritable.get());
}
}
}
|
Step2:
|
package com.laoxiao.mr.tianchi;
import java.io.IOException;
import java.util.HashMap;
import java.util.Map;
import java.util.Map.Entry;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
/**
* 按用户分组,计算所有物品出现的组合列表,得到用户对物品的喜爱度得分矩阵
u13 i160:1,
u14 i25:1,i223:1,
u16 i252:1,
u21 i266:1,
u24 i64:1,i218:1,i185:1,
u26 i276:1,i201:1,i348:1,i321:1,i136:1,
* @author root
*
*/
public class Step2 {
public static boolean run(Configuration config,Map<String, String> paths){
try {
FileSystem fs =FileSystem.get(config);
Job job =Job.getInstance(config);
job.setJobName("step2");
job.setJarByClass(StartRun.class);
job.setMapperClass(Step2_Mapper.class);
job.setReducerClass(Step2_Reducer.class);
//
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(Text.class);
FileInputFormat.addInputPath(job, new Path(paths.get("Step2Input")));
Path outpath=new Path(paths.get("Step2Output"));
if(fs.exists(outpath)){
fs.delete(outpath,true);
}
FileOutputFormat.setOutputPath(job, outpath);
boolean f= job.waitForCompletion(true);
return f;
} catch (Exception e) {
e.printStackTrace();
}
return false;
}
static class Step2_Mapper extends Mapper<LongWritable, Text, Text, Text>{
//如果使用:用户+物品,同时作为输出key,更优
protected void map(LongWritable key, Text value,
Context context)
throws IOException, InterruptedException {
String[] tokens=value.toString().split(",");
String item=tokens[0];
String user=tokens[1];
String action =tokens[2];
Text k= new Text(user);
Integer rv =StartRun.R.get(action);
// if(rv!=null){
Text v =new Text(item+":"+ rv.intValue());
context.write(k, v);
}
}
static class Step2_Reducer extends Reducer<Text, Text, Text, Text>{
protected void reduce(Text key, Iterable<Text> i,
Context context)
throws IOException, InterruptedException {
Map<String, Integer> r =new HashMap<String, Integer>();
for(Text value :i){
String[] vs =value.toString().split(":");
String item=vs[0];
Integer action=Integer.parseInt(vs[1]);
action = ((Integer) (r.get(item)==null? 0:r.get(item))).intValue() + action;
r.put(item,action);
}
StringBuffer sb =new StringBuffer();
for(Entry<String, Integer> entry :r.entrySet() ){
sb.append(entry.getKey()+":"+entry.getValue().intValue()+",");
}
context.write(key,new Text(sb.toString()));
}
}
}
|
Step3:
|
package com.laoxiao.mr.tianchi;
import java.io.IOException;
import java.util.Map;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
/**
* 对物品组合列表进行计数,建立物品的同现矩阵
i100:i100 3
i100:i105 1
i100:i106 1
i100:i109 1
i100:i114 1
i100:i124 1
* @author root
*
*/
public class Step3 {
private final static Text K = new Text();
private final static IntWritable V = new IntWritable(1);
public static boolean run(Configuration config,Map<String, String> paths){
try {
FileSystem fs =FileSystem.get(config);
Job job =Job.getInstance(config);
job.setJobName("step3");
job.setJarByClass(StartRun.class);
job.setMapperClass(Step3_Mapper.class);
job.setReducerClass(Step3_Reducer.class);
job.setCombinerClass(Step3_Reducer.class);
//
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(IntWritable.class);
FileInputFormat.addInputPath(job, new Path(paths.get("Step3Input")));
Path outpath=new Path(paths.get("Step3Output"));
if(fs.exists(outpath)){
fs.delete(outpath,true);
}
FileOutputFormat.setOutputPath(job, outpath);
boolean f= job.waitForCompletion(true);
return f;
} catch (Exception e) {
e.printStackTrace();
}
return false;
}
static class Step3_Mapper extends Mapper<LongWritable, Text, Text, IntWritable>{
protected void map(LongWritable key, Text value,
Context context)
throws IOException, InterruptedException {
String[] tokens=value.toString().split("\t");
String[] items =tokens[1].split(",");
for (int i = 0; i < items.length; i++) {
String itemA = items[i].split(":")[0];
for (int j = 0; j < items.length; j++) {
String itemB = items[j].split(":")[0];
K.set(itemA+":"+itemB);
context.write(K, V);
}
}
}
}
static class Step3_Reducer extends Reducer<Text, IntWritable, Text, IntWritable>{
protected void reduce(Text key, Iterable<IntWritable> i,
Context context)
throws IOException, InterruptedException {
int sum =0;
for(IntWritable v :i ){
sum =sum+v.get();
}
V.set(sum);
context.write(key, V);
}
}
}
|
Step4:
|
package com.laoxiao.mr.tianchi;
import java.io.IOException;
import java.util.HashMap;
import java.util.Iterator;
import java.util.Map;
import java.util.regex.Pattern;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.input.FileSplit;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
/**
*
* 把同现矩阵和得分矩阵相乘
* @author root
*
*/
public class Step4 {
public static boolean run(Configuration config, Map<String, String> paths) {
try {
FileSystem fs = FileSystem.get(config);
Job job = Job.getInstance(config);
job.setJobName("step4");
job.setJarByClass(StartRun.class);
job.setMapperClass(Step4_Mapper.class);
job.setReducerClass(Step4_Reducer.class);
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(Text.class);
// FileInputFormat.addInputPath(job, new
// Path(paths.get("Step4Input")));
FileInputFormat.setInputPaths(job,
new Path[] { new Path(paths.get("Step4Input1")),
new Path(paths.get("Step4Input2")) });
Path outpath = new Path(paths.get("Step4Output"));
if (fs.exists(outpath)) {
fs.delete(outpath, true);
}
FileOutputFormat.setOutputPath(job, outpath);
boolean f = job.waitForCompletion(true);
return f;
} catch (Exception e) {
e.printStackTrace();
}
return false;
}
static class Step4_Mapper extends Mapper<LongWritable, Text, Text, Text> {
private String flag;// A同现矩阵 or B得分矩阵
//每个maptask,初始化时调用一次
protected void setup(Context context) throws IOException,
InterruptedException {
FileSplit split = (FileSplit) context.getInputSplit();
flag = split.getPath().getParent().getName();// 判断读的数据集
System.out.println(flag + "**********************");
}
protected void map(LongWritable key, Text value, Context context)
throws IOException, InterruptedException {
String[] tokens = Pattern.compile("[\t,]").split(value.toString());
if (flag.equals("step3")) {// 同现矩阵
String[] v1 = tokens[0].split(":");
String itemID1 = v1[0];
String itemID2 = v1[1];
String num = tokens[1];
Text k = new Text(itemID2);// 以前一个物品为key 比如i100
Text v = new Text("A:" + itemID1 + "," + num);// A:i109,1
context.write(k, v);
} else if (flag.equals("step2")) {// 用户对物品喜爱得分矩阵
String userID = tokens[0];
for (int i = 1; i < tokens.length; i++) {
String[] vector = tokens[i].split(":");
String itemID = vector[0];// 物品id
String pref = vector[1];// 喜爱分数
Text k = new Text(itemID); // 以物品为key 比如:i100
Text v = new Text("B:" + userID + "," + pref); // B:u401,2
context.write(k, v);
}
}
}
}
static class Step4_Reducer extends Reducer<Text, Text, Text, Text> {
protected void reduce(Text key, Iterable<Text> values, Context context)
throws IOException, InterruptedException {
// A同现矩阵 or B得分矩阵
//某一个物品,针对它和其他所有物品的同现次数,都在mapA集合中
Map<String, Integer> mapA = new HashMap<String, Integer>();// 和该物品(key中的itemID)同现的其他物品的同现集合// 。其他物品ID为map的key,同现数字为值
Map<String, Integer> mapB = new HashMap<String, Integer>();// 该物品(key中的itemID),所有用户的推荐权重分数。
for (Text line : values) {
String val = line.toString();
if (val.startsWith("A:")) {// 表示物品同现数字
String[] kv = Pattern.compile("[\t,]").split(
val.substring(2));
try {
mapA.put(kv[0], Integer.parseInt(kv[1]));
} catch (Exception e) {
e.printStackTrace();
}
} else if (val.startsWith("B:")) {
String[] kv = Pattern.compile("[\t,]").split(
val.substring(2));
try {
mapB.put(kv[0], Integer.parseInt(kv[1]));
} catch (Exception e) {
e.printStackTrace();
}
}
}
double result = 0;
Iterator<String> iter = mapA.keySet().iterator();
while (iter.hasNext()) {
String mapk = iter.next();// itemID
int num = mapA.get(mapk).intValue();
Iterator<String> iterb = mapB.keySet().iterator();
while (iterb.hasNext()) {
String mapkb = iterb.next();// userID
int pref = mapB.get(mapkb).intValue();
result = num * pref;// 矩阵乘法相乘计算
Text k = new Text(mapkb);
Text v = new Text(mapk + "," + result);
context.write(k, v);
}
}
}
}
}
|
Step5:
|
package com.laoxiao.mr.tianchi;
import java.io.IOException;
import java.util.HashMap;
import java.util.Iterator;
import java.util.Map;
import java.util.regex.Pattern;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
/**
*
* 把相乘之后的矩阵相加获得结果矩阵
*
* @author root
*
*/
public class Step5 {
private final static Text K = new Text();
private final static Text V = new Text();
public static boolean run(Configuration config, Map<String, String> paths) {
try {
FileSystem fs = FileSystem.get(config);
Job job = Job.getInstance(config);
job.setJobName("step5");
job.setJarByClass(StartRun.class);
job.setMapperClass(Step5_Mapper.class);
job.setReducerClass(Step5_Reducer.class);
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(Text.class);
FileInputFormat
.addInputPath(job, new Path(paths.get("Step5Input")));
Path outpath = new Path(paths.get("Step5Output"));
if (fs.exists(outpath)) {
fs.delete(outpath, true);
}
FileOutputFormat.setOutputPath(job, outpath);
boolean f = job.waitForCompletion(true);
return f;
} catch (Exception e) {
e.printStackTrace();
}
return false;
}
static class Step5_Mapper extends Mapper<LongWritable, Text, Text, Text> {
/**
* 原封不动输出
*/
protected void map(LongWritable key, Text value, Context context)
throws IOException, InterruptedException {
String[] tokens = Pattern.compile("[\t,]").split(value.toString());
Text k = new Text(tokens[0]);// 用户为key
Text v = new Text(tokens[1] + "," + tokens[2]);
context.write(k, v);
}
}
static class Step5_Reducer extends Reducer<Text, Text, Text, Text> {
protected void reduce(Text key, Iterable<Text> values, Context context)
throws IOException, InterruptedException {
Map<String, Double> map = new HashMap<String, Double>();// 结果
for (Text line : values) {// i9,4.0
String[] tokens = line.toString().split(",");
String itemID = tokens[0];
Double score = Double.parseDouble(tokens[1]);
if (map.containsKey(itemID)) {
map.put(itemID, map.get(itemID) + score);// 矩阵乘法求和计算
} else {
map.put(itemID, score);
}
}
Iterator<String> iter = map.keySet().iterator();
while (iter.hasNext()) {
String itemID = iter.next();
double score = map.get(itemID);
Text v = new Text(itemID + "," + score);
context.write(key, v);
}
}
}
}
|
Step6:
|
package com.laoxiao.mr.tianchi;
import java.io.DataInput;
import java.io.DataOutput;
import java.io.IOException;
import java.util.Map;
import java.util.regex.Pattern;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.io.WritableComparable;
import org.apache.hadoop.io.WritableComparator;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
/**
*
* 按照推荐得分降序排序,每个用户列出10个推荐物品
*
* @author root
*
*/
public class Step6 {
private final static Text K = new Text();
private final static Text V = new Text();
public static boolean run(Configuration config, Map<String, String> paths) {
try {
FileSystem fs = FileSystem.get(config);
Job job = Job.getInstance(config);
job.setJobName("step6");
job.setJarByClass(StartRun.class);
job.setMapperClass(Step6_Mapper.class);
job.setReducerClass(Step6_Reducer.class);
job.setSortComparatorClass(NumSort.class);
job.setGroupingComparatorClass(UserGroup.class);
job.setMapOutputKeyClass(PairWritable.class);
job.setMapOutputValueClass(Text.class);
FileInputFormat
.addInputPath(job, new Path(paths.get("Step6Input")));
Path outpath = new Path(paths.get("Step6Output"));
if (fs.exists(outpath)) {
fs.delete(outpath, true);
}
FileOutputFormat.setOutputPath(job, outpath);
boolean f = job.waitForCompletion(true);
return f;
} catch (Exception e) {
e.printStackTrace();
}
return false;
}
static class Step6_Mapper extends Mapper<LongWritable, Text, PairWritable, Text> {
protected void map(LongWritable key, Text value, Context context)
throws IOException, InterruptedException {
String[] tokens = Pattern.compile("[\t,]").split(value.toString());
String u = tokens[0];
String item = tokens[1];
String num = tokens[2];
PairWritable k =new PairWritable();
k.setUid(u);
k.setNum(Double.parseDouble(num));
V.set(item+":"+num);
context.write(k, V);
}
}
static class Step6_Reducer extends Reducer<PairWritable, Text, Text, Text> {
protected void reduce(PairWritable key, Iterable<Text> values, Context context)
throws IOException, InterruptedException {
int i=0;
StringBuffer sb =new StringBuffer();
for(Text v :values){//输出前10个推荐物品
if(i==10)
break;
sb.append(v.toString()+",");
i++;
}
K.set(key.getUid());
V.set(sb.toString());
context.write(K, V);
}
}
static class PairWritable implements WritableComparable<PairWritable>{
// private String itemId;
private String uid;
private double num;
public void write(DataOutput out) throws IOException {
out.writeUTF(uid);
// out.writeUTF(itemId);
out.writeDouble(num);
}
public void readFields(DataInput in) throws IOException {
this.uid=in.readUTF();
// this.itemId=in.readUTF();
this.num=in.readDouble();
}
public int compareTo(PairWritable o) {
int r =this.uid.compareTo(o.getUid());
if(r==0){
return Double.compare(this.num, o.getNum());
}
return r;
}
public String getUid() {
return uid;
}
public void setUid(String uid) {
this.uid = uid;
}
public double getNum() {
return num;
}
public void setNum(double num) {
this.num = num;
}
}
static class NumSort extends WritableComparator{
public NumSort(){
super(PairWritable.class,true);
}
public int compare(WritableComparable a, WritableComparable b) {
PairWritable o1 =(PairWritable) a;
PairWritable o2 =(PairWritable) b;
int r =o1.getUid().compareTo(o2.getUid());
if(r==0){
return -Double.compare(o1.getNum(), o2.getNum());
}
return r;
}
}
static class UserGroup extends WritableComparator{
public UserGroup(){
super(PairWritable.class,true);
}
public int compare(WritableComparable a, WritableComparable b) {
PairWritable o1 =(PairWritable) a;
PairWritable o2 =(PairWritable) b;
return o1.getUid().compareTo(o2.getUid());
}
}
}
|
StartRun:
|
package com.laoxiao.mr.tianchi;
import java.util.HashMap;
import java.util.Map;
import org.apache.hadoop.conf.Configuration;
public class StartRun {
public static void main(String[] args) {
Configuration config = new Configuration();
config.set("fs.defaultFS", "hdfs://node1:9000");
// config.set("yarn.resourcemanager.hostname", "node5");
//所有mr的输入和输出目录定义在map集合中
Map<String, String> paths = new HashMap<String, String>();
paths.put("Step1Input", "/usr/input/(sample)sam_tianchi_2014002_rec_tmall_log.csv");
paths.put("Step1Output", "/output/step1");
paths.put("Step2Input", paths.get("Step1Output"));
paths.put("Step2Output", "/output/step2");
paths.put("Step3Input", paths.get("Step2Output"));
paths.put("Step3Output", "/output/step3");
paths.put("Step4Input1", paths.get("Step2Output"));
paths.put("Step4Input2", paths.get("Step3Output"));
paths.put("Step4Output", "/output/step4");
paths.put("Step5Input", paths.get("Step4Output"));
paths.put("Step5Output", "/output/step5");
paths.put("Step6Input", paths.get("Step5Output"));
paths.put("Step6Output", "/output/step6");
Step1.run(config, paths);
Step2.run(config, paths);
Step3.run(config, paths);
Step4.run(config, paths);
Step5.run(config, paths);
Step6.run(config, paths);
}
public static Map<String, Integer> R = new HashMap<String, Integer>();
static {
R.put("click", 1);
R.put("collect", 2);
R.put("cart", 3);
R.put("alipay", 4);
}
}
|