SSN数据和源码配置调试过程请参考上一篇博文:【三维目标检测】SSN(一)_Coding的叶子的博客-CSDN博客。本文主要详细介绍SSN网络结构及其运行中间状态。
1 模型总体过程
SSN主要结构如下图所示,其核心在于提出了shape-aware heads grouping和shape signature结构,前者针对不同类别目标设置不同Head,并得到不同尺度的特征图。相比于其他网络采用单一尺度的特征图,这种方法的可以有效提升精度,但是参数量也大大增加。从实现过程来看,这种结构实际上与增加anchor和FPN的作用相近似。另一方面,读者也可以类比以下yolov5的Head结构。shape signature结构主要是对目标轮廓进行编码,强调了目标轮廓形状的特点,从而最终进一步提升目标检测精度。

需要注意的是,在接下来即将详细介绍的mmdetection3d SSN程序种仅仅使用了shape-aware heads grouping结构,并没有采用shape signature结构。
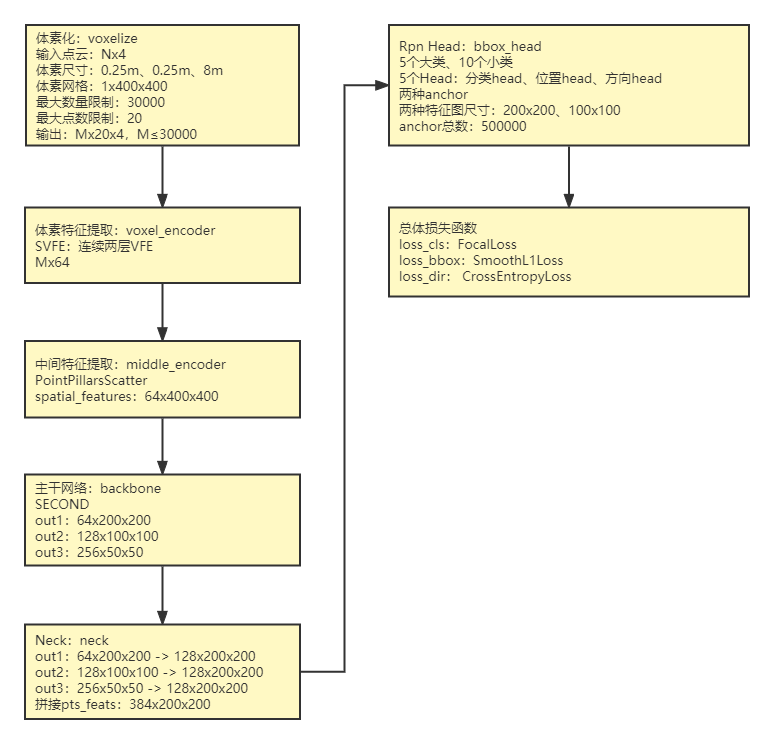
2 主要模块解析
2.1 体素化
源码中用于实现体素化的入口函数为self.voxelize(points),具体实现函数为Voxelization(voxel_size=[0.25, 0.25, 8], point_cloud_range=[-50, -50, -5, 50, 50, 3], max_num_points=20, max_voxels=(30000, 40000), deterministic=True)。函数输入分别为:
(1)points,Nx4,原始点云,N表示点云数量,4表示特征维度,特征为坐标x、y、z与反射强度r。
(2)voxel_size:单位体素的尺寸,x、y、z方向上的尺度分别为0.25m、0.25m、8m。
(3)point_cloud_range:x、y、z方向的距离范围,结合(2)中体素尺寸可以得到总的体素数量为400x400x1。
(4)max_num_points:定义每个体素中取值点的最大数量,默认为20,在voxelnet中T=35。
(5)max_voxels:表示含有点云的体素最大数量,训练时为30000,推理时为40000。训练时当数量超过30000时,仅保留30000,当数量不足40000时,则保留全部体素。
(6)deterministic:取值为True时,表示每次体素化的结果是确定的,而不是随机的。
体素化输出结果如下:
(1)voxels:Mx20x4,体素中各个点的原始坐标和反射强度,M(M≤30000)个体素,每个体素最多20个点。
(2)num_points:Mx1,每个体素中点的数量,最小数量为1,最大数量为20。
(3)coors:体素自身坐标,坐标值为整数,表示体素的按照单位尺度得到的坐标,Mx4,[batch_id, x, y, z]
2.2 体素特征提取VFE(voxel_encoder)
类似voxelnet和Pointpillars模型,体素特征通过SVFE层提取,即连续两层VFE,其中VFE层提取体素特征用的是PointNet网络。SVFW详细结构和计算过程请参考:【三维目标检测】VoxelNet(三):模型详解_Coding的叶子的博客-CSDN博客_voxelnet和【三维目标检测】Pointpillars(二)_Coding的叶子的博客-CSDN博客_voxels 点云。SVFW体素特征提取的入口函数为self.pts_voxel_encoder(voxels, num_points, coors, img_feats, img_metas)。SSN提取的体素特征voxel_features的维度为Mx64。
2.3 中间特征提取 middle_encoder
SSN采用的中间特征提取网络为PointPillarsScatter。Pointpillars的中间特征提取层将voxel_features(Mx64)每一维特征投影到各个体素当中,类似于二维图像,Mx64->400x400x1,即Mx64->160000x64,没有取值的地方像素值取为0。Canvas,64x400x400。由于体素在Z轴方向上的长度仅仅为1,所以投影后得到的是一个平面信息,这样后续可以直接用二维卷积进行特征提取,而不需要采用三维卷积或三维稀疏卷积操作。这个操作实际上可以直接用三维稀疏卷积进行替换。中间特征提取层的入口函数为self.pts_middle_encoder(voxel_features, coors, batch_size),输出特征维度为64x400x400。
2.4 主干网络特征提取
SSN主干网络采用了SECOND FPN结构,函数入口为self.pts_backbone(x),输出三种不同尺度的特征64x200x200、128x100x100、256x50x50。
backbone:SECOND
1、2.3中out 64x400x400经连续4个3x3卷积(第一个步长为2):64x200x200,out1
2、out1 64x200x200经连续6个3x3卷积(第一个步长为2):128x100x100,out2
3、out2 128x100x100经连续6个3x3卷积(第一个步长为2):256x50x50,out3
SECOND(
(blocks): ModuleList(
(0): Sequential(
(0): Conv2d(64, 64, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), bias=False)
(1): NaiveSyncBatchNorm2d(64, eps=0.001, momentum=0.01, affine=True, track_running_stats=True)
(2): ReLU(inplace=True)
(3): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(4): NaiveSyncBatchNorm2d(64, eps=0.001, momentum=0.01, affine=True, track_running_stats=True)
(5): ReLU(inplace=True)
(6): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(7): NaiveSyncBatchNorm2d(64, eps=0.001, momentum=0.01, affine=True, track_running_stats=True)
(8): ReLU(inplace=True)
(9): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(10): NaiveSyncBatchNorm2d(64, eps=0.001, momentum=0.01, affine=True, track_running_stats=True)
(11): ReLU(inplace=True)
)
(1): Sequential(
(0): Conv2d(64, 128, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), bias=False)
(1): NaiveSyncBatchNorm2d(128, eps=0.001, momentum=0.01, affine=True, track_running_stats=True)
(2): ReLU(inplace=True)
(3): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(4): NaiveSyncBatchNorm2d(128, eps=0.001, momentum=0.01, affine=True, track_running_stats=True)
(5): ReLU(inplace=True)
(6): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(7): NaiveSyncBatchNorm2d(128, eps=0.001, momentum=0.01, affine=True, track_running_stats=True)
(8): ReLU(inplace=True)
(9): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(10): NaiveSyncBatchNorm2d(128, eps=0.001, momentum=0.01, affine=True, track_running_stats=True)
(11): ReLU(inplace=True)
(12): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(13): NaiveSyncBatchNorm2d(128, eps=0.001, momentum=0.01, affine=True, track_running_stats=True)
(14): ReLU(inplace=True)
(15): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(16): NaiveSyncBatchNorm2d(128, eps=0.001, momentum=0.01, affine=True, track_running_stats=True)
(17): ReLU(inplace=True)
)
(2): Sequential(
(0): Conv2d(128, 256, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), bias=False)
(1): NaiveSyncBatchNorm2d(256, eps=0.001, momentum=0.01, affine=True, track_running_stats=True)
(2): ReLU(inplace=True)
(3): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(4): NaiveSyncBatchNorm2d(256, eps=0.001, momentum=0.01, affine=True, track_running_stats=True)
(5): ReLU(inplace=True)
(6): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(7): NaiveSyncBatchNorm2d(256, eps=0.001, momentum=0.01, affine=True, track_running_stats=True)
(8): ReLU(inplace=True)
(9): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(10): NaiveSyncBatchNorm2d(256, eps=0.001, momentum=0.01, affine=True, track_running_stats=True)
(11): ReLU(inplace=True)
(12): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(13): NaiveSyncBatchNorm2d(256, eps=0.001, momentum=0.01, affine=True, track_running_stats=True)
(14): ReLU(inplace=True)
(15): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(16): NaiveSyncBatchNorm2d(256, eps=0.001, momentum=0.01, affine=True, track_running_stats=True)
(17): ReLU(inplace=True)
)
)
)2.5 上采样拼接 self.neck
Neck层分别对out1、out2、out3上采样后进行拼接,函数入口为self.pts_neck(x),拼接后输出特征pts_feats维度为384x200x200:
out1:64x200x200 -> 128x200x200
out2:128x100x100 -> 128x200x200
out3:256x50x50 -> 128x200x200
拼接out:128x200x200、128x200x200、128x200x200 ->384x200x200 (self.extract_feat)
2.6 检测头 bbox_head
SSN的head结构入口函数为self.pts_bbox_head(pts_feats)。由于不同类别目标的点云自身在轮廓结构上有所差异,SSN设计针对不同类别设置了不同的Head。各个单独的Head与常规的RPN Head一致,主要包括分类head、位置head和方向head。另一方面,根据特征图越小视野越大这一卷积操作特征,我们知道小的特征图适合检测大目标。因而,针对车辆和卡车这种大目标,特征图尺度由200x200降为100x100。
各个Head分支参数分别如下,将所有结果进行拼接可得到分类分数cls_score(500000x10)、位置bbox_pred(500000x9)和方向dir_cls_preds(500000x2),其中500000是anchor总数。位置的9个维度分别为中心偏移(dx、dy、dz)、尺寸对数(log(dw)、log(dl)、log(dz))、角度rz、速度(vx、vy)。
(1)2种anchor、2个类别(bicycle、motorcycle)、特征图200x200 ->160000
pts_feats、Cls Conv2d(384, 64)、Conv2d(64, 64)、Conv2d(64, 40) -> cls_score 40x200x200 -> 160000x10
pts_feats、Cls Conv2d(384, 64)、Conv2d(64, 64)、Conv2d(64, 36) ->bbox_pred 36x200x200 -> 160000x9
pts_feats、Cls Conv2d(384, 64)、Conv2d(64, 64)、Conv2d(64, 8) ->bbox_pred 8x200x200 -> 160000x2
(2)2种anchor、1个类别(pedestrian)、特征图200x200 ->80000
pts_feats、Cls Conv2d(384, 64)、Conv2d(64, 64)、Conv2d(64, 20) -> cls_score 20x200x200 -> 80000x10
pts_feats、Cls Conv2d(384, 64)、Conv2d(64, 64)、Conv2d(64, 18) ->bbox_pred 18x200x200 -> 80000x9
pts_feats、Cls Conv2d(384, 64)、Conv2d(64, 64)、Conv2d(64, 4) ->bbox_pred 4x200x200 -> 80000x2
(3)2种anchor、2个类别(traffic_cone、barrier)、特征图200x200 ->160000
pts_feats、Cls Conv2d(384, 64)、Conv2d(64, 64)、Conv2d(64, 40) -> cls_score 40x200x200 -> 160000x10
pts_feats、Cls Conv2d(384, 64)、Conv2d(64, 64)、Conv2d(64, 36) ->bbox_pred 36x200x200 -> 160000x9
pts_feats、Cls Conv2d(384, 64)、Conv2d(64, 64)、Conv2d(64, 8) ->bbox_pred 8x200x200 -> 160000x2
(4)2种anchor、1个类别(car)、特征图100x100 ->20000
pts_feats、Cls Conv2d(384, 64, 2)、Conv2d(64, 64)、Conv2d(64, 20) -> cls_score 20x100x100 -> 20000x10
pts_feats、Cls Conv2d(384, 64)、Conv2d(64, 64)、Conv2d(64, 18) ->bbox_pred 18x100x100 -> 20000x9
pts_feats、Cls Conv2d(384, 64)、Conv2d(64, 64)、Conv2d(64, 4) ->bbox_pred 4x100x100 -> 20000x2
(5)2种anchor、4个类别(truck、trailer、bus、construction_vehicle)、特征图100x100 -> 80000
pts_feats、Cls Conv2d(384, 64, 2)、Conv2d(64, 64)、Conv2d(64, 80) -> cls_score 80x100x100 -> 80000x10
pts_feats、Cls Conv2d(384, 64)、Conv2d(64, 64)、Conv2d(64, 72) ->bbox_pred 72x100x100 -> 80000x9
pts_feats、Cls Conv2d(384, 64)、Conv2d(64, 64)、Conv2d(64, 16) ->bbox_pred 16x100x100 -> 80000x2
Outs outs = self.pts_bbox_head(pts_feats)
cls_score: 500000x10
bbox_pred:500000x9
dir_cls_preds:500000x22.7 损失函数
losses = self.pts_bbox_head.loss(*loss_inputs, gt_bboxes_ignore=gt_bboxes_ignore)
2.7.1 标签计算.
根据Iou为每个anchor选择匹配的真实目标框
- 找到最大Iou的真实目标框和索引
- Iou小于指定阈值如0.4的anchor设置为负样本,对应gt_inds序号为0。
- Iou大于指定阈值如0.6的anchor设置为正样本,对应gt_inds需要设置为样本标签序号,从1开始。
- gt_inds取值为-1的点对应样本介于正负样本之间的情况。
目标位置采用偏移回归的方式,如下所示。其中,a表示anchor,g表示真实标签,t表示模型预测标签。
za = za + ha / 2
zg = zg + hg / 2
diagonal = torch.sqrt(la**2 + wa**2)
xt = (xg - xa) / diagonal
yt = (yg - ya) / diagonal
zt = (zg - za) / ha
lt = torch.log(lg / la)
wt = torch.log(wg / wa)
ht = torch.log(hg / ha)
rt = rg - ra
limited_val = val - torch.floor(val / period + offset) * period2.7.2 损失计算
SSN总体损失包括目标类别损失、方向损失和位置偏移回归损失。目标类别和方向的损失函数分别为FocalLoss和CrossEntropyLoss。位置偏移回归的9个维度损失函数均为SmoothL1Loss,并且速度(最后两个维度)损失权重为0.2,其它权重均为1.0。在实验过程中,随机选择了两组样本,其负样本的点数量为999823,而正样本数量仅为91。针对这种正负样本不均衡的情况,目标类别损失函数采用了FocalLoss。
loss_cls = self.loss_cls(cls_score, labels, label_weights, avg_factor=num_total_samples)
loss_cls FocalLoss
[1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 0.2, 0.2]
loss_bbox = self.loss_bbox(bbox_pred, bbox_targets, bbox_weights, avg_factor=num_total_samples)
SmoothL1Loss
loss_dir = self.loss_dir(dir_cls_preds, dir_targets, dir_weights, avg_factor=num_total_samples)
CrossEntropyLoss2.8 顶层结构
顶层结构主要包含以下三部分:
(1)特征提取:self.extract_feat,通过PointPillars网路机构进行特征提取,输出结果见2.5节。
(2)bbox Head:结果预测,见2.6节。
(3)损失函数:见2.7节。
def forward_train(self, points=None, img_metas=None, gt_bboxes_3d=None, gt_labels_3d=None, gt_labels=None, gt_bboxes=None, img=None, proposals=None, gt_bboxes_ignore=None):
img_feats, pts_feats = self.extract_feat(points, img=img, img_metas=img_metas)
losses_pts = self.forward_pts_train(pts_feats, gt_bboxes_3d, gt_labels_3d, img_metas, gt_bboxes_ignore)
losses.update(losses_pts)
return losses3 训练命令
python tools/train.py configs/ssn/hv_ssn_secfpn_sbn-all_2x16_2x_nus-3d.py4 运行结果
