最近发现周围的很多小伙伴们都不太乐意使用pandas,转而投向其他的数据操作库,身为一个数据工作者,基本上是张口pandas,闭口pandas了,故而写下此系列以让更多的小伙伴们爱上pandas。
系列文章说明:
系列名(系列文章序号)——此次系列文章具体解决的需求
平台:
- windows 10
- python 3.8
- pandas >=1.2.4
/ 数据需求
最近在看一本关于使用pandas进行数据处理的书,于2020年出版,其中有一段对在线零售商品的统计数据处理部分,每个订单每个商品是单独记录,所以在只关心订单时会发现有多个同样的订单号存在,此篇讨论如何统计每月的订单量。数据读取如下:
import pandas as pd
df = pd.read_csv('Online_Retail.csv.zip', parse_dates=['InvoiceDate'])
df_new = df.dropna().copy()
# 拆出月份
df_new['YearMonth'] = df_new['InvoiceDate'].map(lambda x: 100 * x.year + x.month)
ps: 数据获取方式:
github:
https://github.com/lk-itween/FunnyCodeRepository/raw/main/PandasSaved/data/Online_Retail.csv.zip

(406829, 9)
/ 需求处理
由于只关心订单号,重复的订单号会使数据统计不准确,需要将订单号去重后再统计。
- 方式一:书中使用unique后再统计。
df_new.groupby('InvoiceNo')['YearMonth'].unique().value_counts().sort_index()
pandas从2020年发展至今已更新多次,此前书中方法可能无法执行,如此处会产生如下报错,原因为unique()执行后每行数据为列表类型,value_counts不能处理。

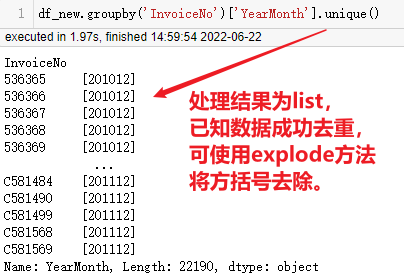
将代码更改如下就可以完成需求。
df_new.groupby('InvoiceNo')['YearMonth'].unique().explode().value_counts().sort_index()
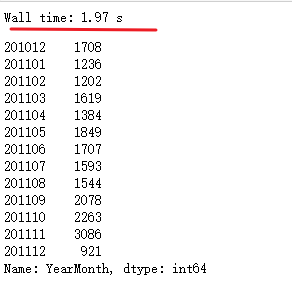
(手动水印:原创CSDN宿者朽命,https://blog.csdn.net/weixin_46281427?spm=1011.2124.3001.5343 ,公众号A11Dot派)
- 方式二:对groupby结果使用value_counts去重再统计。
df_new.groupby('InvoiceNo')['YearMonth'].value_counts().reset_index(name='count')['YearMonth'].value_counts().sort_index()
第一个value_counts的作用就是对YearMonth去重,需要的列名已作为索引,通过reset_index将索引重置为列数据,再对YearMonth进行value_counts统计每月的订单量。
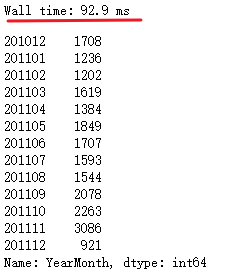
在同一台电脑上,这一方法比书中提到的方法要快,可能unique在处理上需要消耗一定时间,然而这种处理却把思想弄复杂了,pandas去重处理可以直接使用drop_duplicates。
- 方式三:drop_duplicates去重后统计。
df_new[['InvoiceNo', 'YearMonth']].drop_duplicates()['YearMonth'].value_counts().sort_index()

对比前两种方法,代码简短了不少,处理时间也减少了。
ps: 补充解法:nunique
观察数据需求可发现,是对每个月份进行统计,那么直接对月份进行分组,在各分组中进行去重统计。
df_new.groupby('YearMonth')['InvoiceNo'].nunique()
/ 总结
本篇通过引入书中例子,复现书中代码,结合现有数据处理方法,逐步优化代码处理方式,阐述各个方法的异同点,完成数据需求。源数据可通过文章开头处获取。
静观天色,晓听风雨。
于二零二二年六月二十二日作