博主简介
博主是一名大二学生,主攻人工智能研究。感谢让我们在CSDN相遇,博主致力于在这里分享关于人工智能,c++,Python,爬虫等方面知识的分享。 如果有需要的小伙伴可以关注博主,博主会继续更新的,如果有错误之处,大家可以指正。
专栏简介: 本专栏主要研究计算机视觉,涉及算法,案例实践,网络模型等知识。包括一些常用的数据处理算法,也会介绍很多的Python第三方库。如果需要,点击这里订阅专栏 。
给大家分享一个我很喜欢的一句话:“每天多努力一点,不为别的,只为日后,能够多一些选择,选择舒心的日子,选择自己喜欢的人!”

目录
前面我们讲解了如何对图像进行美化,包括简单的打光、美白、去噪和稍显复杂的直方图均衡化、图像金字塔。那么这一章我们将二维的图像与现实生活中的物体联系起来。现实生活中的物体和图像有两个明显的不同之处:①物体是三维的,图像十二位的。②物体是运动的,图象是静止的。为了解决第一个不同,需要从三维物体采集二维图像,这往往是一个几何过程,在计算机视觉中称为相机模型。为了解决第二个不同,我们使用光流算法来进行解决。所以,本节的学习任务就是光流算法的应用。
相机模型
针孔相机模型
小孔成像,这应该是个不陌生的话题。初中时候的研究课题,今天我们介绍的第一个相机模型就是针孔相机模型。
①.相机平面,我们将相机看成一个平面,远处的光线经过此平面时被折射或反射,当然一个相机模型可能存在多个相机平面(多个透镜)。
②.图像平面,物体聚焦成像的平面。
③.相机焦距,远处平行光经过相机模型后汇聚于一点,此点与相机平面的距离称为焦距,显然焦距可以是负的。
④.投影中心,物体发出的所有光线汇聚的点。
针孔相机模型很简单,在相机平面只有一个点可以通过光线。 对于理想的针孔相机,焦距是图像到针孔平面的距离。

假设针孔相机模型焦距为f,物体高度为H,物体离针孔平面距离为x,则成像的高度h,可用公式来表示:
假设物体上某个点的坐标为(X,Y,Z),其中Z为物体到小孔的距离,则物体经过相机模型后对应的成像点的坐标为(f*X/Z,f*Y/Z),如果考虑到相机模型并非真正的平面,而是具有一定的厚度,以及焦距并非是均匀的,那么对应成像点的坐标为(f*X/Z+Cx,fy*Y/Z+Cy)。
针孔相机模型是最简单的相机模型,那么为什么在现实生活中这种相机并不存在呢?这是因为前面所讲的,物体所发出的光线或者说反射的光线,只有一条能够穿过小孔,就会显得非常暗,做过实验的应该就知道。所以需要很长时间的曝光才能得到足够亮度的图像。
射影几何
其实真正的相机模型就是将物理世界中的点(X,Y,Z)映射到平面上的点(x,y)处,显然在物理世界中的点在成像平面上有且仅有一个点与之对应,而成像平面上的点可能对应物理世界中的多个点。这种映射也叫射影变换。
采用射影变换,我们可以将点(X,Y,Z)转为点(x,y),首先将点(x,y)转为齐次坐标:(x,y,1)。则射影变换可以用一个3x3的矩阵M表示,满足(x,y,1)=Mx(X,Y,Z)。例如针孔摄像头:
在OPenCV中,齐次坐标和非齐次坐标的转换非常简单,使用函数cv2.converPointsToHomogeneous和cv2.convertPointsFromHomogeneous即可。参数为输入和输出向量。
import numpy as np
import cv2
#设置坐标
point=np.array([[1,2]])
#转为齐次坐标
pointth=cv2.convertPointsToHomogeneous(point)
#转为非齐次坐标
pointfth=cv2.convertPointsFromHomogeneous(pointth)
#输出
print('齐次坐标',pointth)
print('非齐次坐标',pointfth)透镜
透镜的工作原理是使得同一点发出的不同光线,在经过透镜后汇聚到同一点,或者更加发散。透镜成像公式非常简单,假设物距为u,焦距为f,则像距v:
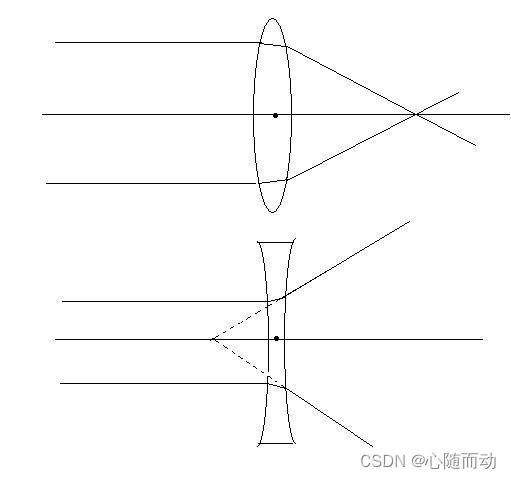
透镜一般分为凸透镜和凹透镜,其均不是真正的球面。凸透镜中间厚,两边薄。 物体放在焦距之外,对光线有汇聚作用,可在凸透镜另一侧成倒立的实像。物体放在焦距之内,在凸透镜的另一侧成倒立放大的虚像。凹凸镜则是中间薄,两边厚,对光线有发散作用,所成的像为缩小的虚像。
透镜畸变
现实中是不存在完美的透镜的,所以我们把真实的透镜与完美透镜的差异叫做透镜畸变。畸变导致的结果是远处的平行光经过透镜后不再汇聚于一点。透镜畸变分为径向畸变和切向畸变,前者由于透镜的厚度和形状不均匀导致,而后者往往是由于相机 在组装过程中造成的。
径向畸变往往在透镜的边缘附近产生,对应不完美的透镜,远离中心处的光线比靠近透镜中心处的光线更加弯曲,导致“鱼眼”效应。

径向畸变很小,对于一般的相机,如果要对径向畸变进行矫正,我们可以在r=0处进行泰勒展开,然后对成像位置x进行矫正:
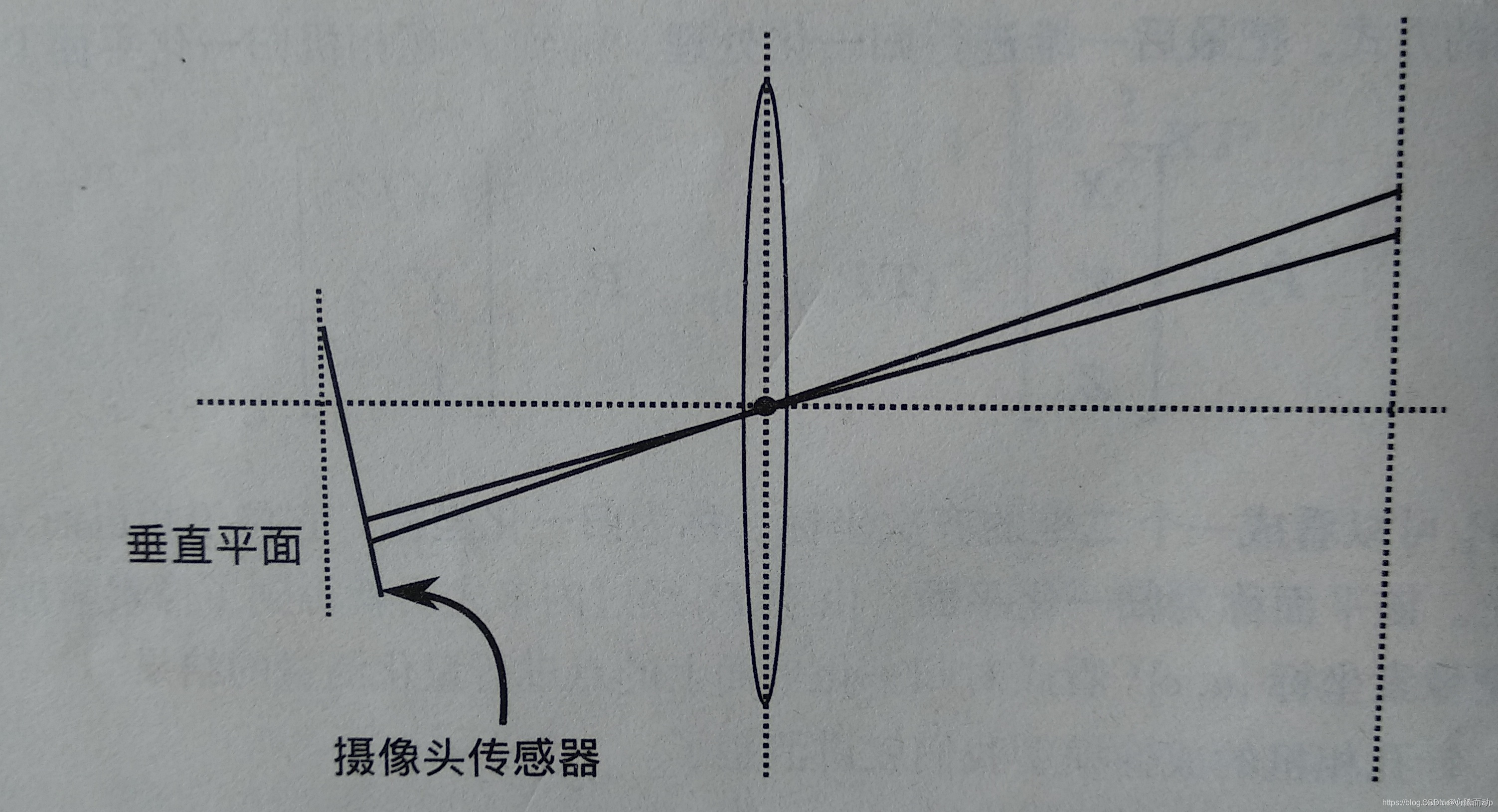
切向畸变往往由于透镜平面与成像平面不平行导致。切向畸变 导致的结果是物象比例失真。
修正:
当然,除了这些,还有其他的畸变种类,不过相比径向和切向畸变,对结果影响较小。所以一般不处理,但是好的摄像机肯定会处理。
光流
在现实生活中,物体和相机一般都是运动的,这也导致了很多的图象是视频类的,为了追踪物体或相机,研究者提出了光流的概念。光流将匹配不同图像中的相同像素,光流的理想输出是两幅图像中每个像素的速度关联,也叫做位移向量。光流分为稠密光流和稀疏光流,区别在于,前者匹配一幅图像中的所有点,而后者只匹配一部分点,这些点一般都是容易跟踪的点,例如角点。由于稀疏光流的成本比稠密光流低,所以常使用稀疏光流。
稀疏光流
稀疏光流算法也叫Lucas-Kanade稀疏光流算法,他计算围绕某些特殊点的局部窗口信息。缺点是当两幅图之间对应点移动过大时,无法在局部窗口中找到,这也导致了金字塔Lucas-Kanade算法的发展。

此算法基于3个基本假设。
①.亮度恒定,认为在整个场景中的平均亮度不变或者说像素的值不变,知识位置改变了。
②.运动缓慢,灵符图像之间的运动幅度很小。
③.空间一致性,对于同一物体,在两幅图像中的大小和形状应该基本一致。
首先用I(x,t)来表示t时刻,在x位置的像素,显然,由于物体与相机的移动,x也是与时间有关的函数x(t),那么第一个假设就是I(x,t)对时间的偏导数为0.即
由第二个条件可的,可以认为在短时间内,物体速度基本是不变的。
于是就得到一维情况下的光流速度方程为:
如果上述的条件均不满足,那么我们该怎么做?就可以直接使用迭代的方法(也叫牛顿法)求解,每次使用上一次的速度作为下一次的初值,然后重复计算,直至收敛。一般5次左右即可结束。
二维的情况和一维类似,将速度分解为x方向上的分量与y方向上的
,于是有;
这里需要使用最后一个假设,即窗口内的像素的移动的规律是相同的。
假设使用3*3的窗口,在当前像素周围3x3窗口内计算其运动:
现在有了一个约束方程,只要像素不是恰好处于图像的边缘位置,就可以对其进行求解。使用最小二乘法:
于是局部光流速度问题就解决了,但是当发生剧烈的运动需要尺寸变大时,效果就会很明显变差,所以我们使用金字塔Lucas-Kannade算法,首席那解决顶层光流,然后将其值作为下一层问题的初值,以此类推。由于不同层之间的图像的比例不同,所以即使每层都是用较小的窗口,也可以追踪到更长、更快的运动。利用函数cv2.calcOpticalFlowPyrLK()。
preving:前一帧图像。
nexting:后一帧图像。
prevpts:前一帧图像像素;
nextpts:后一帧图像像素;
status:是否发生相应的特征。
err:错误度量;
winsize:窗口尺寸;
maxlevel:最大深度;
criteria:算法结束条件;
import numpy as np
import cv2
#打开一个视频
cap=cv2.VideoCapture('F:\Image\\test.mp4')
ret,frame0=cap.read()
#转换为灰度图
gray0=cv2.cvtColor(frame0,cv2.COLOR_BGR2GRAY)
#获取图像中的角点
p0=cv2.goodFeaturesToTrack(gray0,mask=None,maxCorners=50,
qualityLevel=0.5,minDistance=5,blockSize=5)
mask=np.zeros_like(frame0)
while(True):
ret,frame=cap.read()
gray=cv2.cvtColor(frame,cv2.COLOR_BGR2GRAY)
#计算光流
p1,st,err=cv2.calcOpticalFlowPyrLK(gray0,gray,p0,None,winSize=(10,10),maxLevel=5,criteria=(cv2.TERM_CRITERIA_EPS,10,0.03))
#选取跟踪点
new=p1[st==1]
old=p0[st==1]
#画出轨迹
for i,(new,old) in enumerate(zip(new,old)):
#坐标值
a,b=new.ravel()
c,d=old.ravel()
#划轨迹曲线
mask=cv2.line(mask,(int(a),int(b)),(int(c),int(d)),[0,0,255],2)
frame=cv2.circle(frame,(int(a),int(b)),5,[0,0,255],-1)
img=cv2.add(frame,mask)
#显示图像
cv2.imshow('frame',img)
#按esc建退出
k=cv2.waitKey(30) & 0xff
if k==27:
break
#更新上一层的图像和追踪点
gray0=gray.copy()
p0=new.reshape(-1,1,2)
#释放资源
cap.release()
稠密光流的另一个重要算法就是DualTV-L模型。首先定义能量损失,指的是前后帧强度的差:
其中,表示t时刻图像在x处的强度,a是相对影响的权重系数,u是能量流向量。原先的Horn-Schunck算法在所有可能的流场中找到使
最小的u,可以使用拉格朗日乘子法的到。而DualTV-L模型对能量公式进行了改进,将平方和变为直接求和。
如此做的好处就是局部梯度收到的惩罚较小,在不连续的问题上效果更好。
在OPenCV中使用cv2.optflow.DualTVL1OpticalFlow_create()函数创建DualTV-L光流,然后使用flow.calc()计算光流。参数说明:
lambda:权重系数。
nscales:金字塔尺读数。
epsilon:停止准则。
跟踪
视频跟踪其实应用的非常广泛,比如监控跟拍,无人视频监控等,更高端点的就是战斗机的显示头盔,会跟踪敌方战机,为驾驶员提供帮助。这些功能的实现,都离不开算法。这里就简单的介绍一些算法。后面我会专门介绍跟踪算法。
跟踪主要分为两大类:生成模型和判别模型。目前的流行是判别模型:
经典的判别模型有Struck和TLD两种,原理非常简单。将钨锑矿作为正样本,将背景作为负样本,然后使用机器学习模型进行分类训练,之后将训练后的模型应用在后续帧上即可,相当于在每一帧做一个目标检测。
例如,行人检测用HOG特征+SVM分类器,Struck算法用到了类haar特征+SVM分类器。
生成类算法模型有卡尔曼滤波、粒子滤波和mean-shift等,其在当前帧对目标区域进行区域建模,然后在下一帧寻找与模型最相似的区域,这就与前面面讲的光流有关系了。
说到跟踪算法,就要提一下相关滤波。最经典的就是CSK、KCF、DCF、CN等算法。他们的具体工作方法和前面讲到的高斯滤波很相似,简单地说就是一个单层的卷积神经网络。
例如,我来一个分析;
假设原图像为f,卷积核为h,则输出图像为:
g=f*h;
两边同时进行傅里叶变换:
G=FH
最小二乘法优化:
min
求导得:
CSK,KCF算法将原本的单通道线性卷积(MOSSE)拓展为了Kernel卷积,并且加入正则化项,防止过度拟合。另外,KCF和CSK的基础上拓展了很多多通道的HOG特征,CN算法在CSK的基础上拓展了多通道颜色的特征。HOG是梯度特征,而CN是颜色特征,两者恰好互补。
好了,今天的内容就到这里了,拜拜了你嘞!
