1.简介
本文根据2021年OpenAI的《Evaluating Large Language Models Trained on Code》翻译总结的。
主要是介绍Codex,其是在GPT语言模型基础上,用来自GitHub上的开源代码进行微调的。学习了编写python代码的能力。GitHub Copilot 就是采用了Codex的能力。以前类似的模型有CodeBERT、PyMT5等。
我们发现可以训练语言模型来通过自然语言文本描述生成代码。
文中提出了3个模型,一个是基于GPT-3在代码上微调来通过文本描述生成代码的Codex模型(非监督学习);一个是进行监督训练,通过文本描述生成代码的Codex-S模型;一个是通过代码生成代码文本描述的Codex-D模型。
2.评价框架
BLEU等基于匹配的评价规则不适用于评价生成的代码,故此我们使用pass@k评价。
如下式,对每个任务,我们生成n个代码样本(n>=k),计算正确代码样本的数量c,其都通过了单元测试
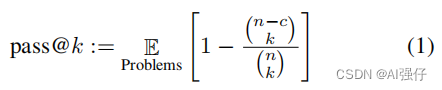
上式采用排列组合阶乘,可能产生非常大的数值,导致数值不稳定。下面代码提高了一个稳定的简化版本,其逐项评估。

Np.prod:返回给定轴上的数组元素的乘积。
3.人类手写的评价数据集
我们手写了164个代码来评估进行pass@k评估。示例如下:

4.代码微调Codex
我们用包括12B参数的GPT-3在代码上微调来产生Codex。
代码是在2020年5月从github上搜集的,每个python文件是1MB以下的。最终我们的数据集是159GB。
5.监督预训练Codex-S
我们尝试了一个监督微调模型,叫Codex-S。
我们从一些流行的代码测试、面试准备网站上搜集了一些代码,搜集了1万个训练样本;另外,是从github 含有CI(continuous integration)的工程,搜集了4万个训练样本。
训练目标是最小化negative log-likelihood。
6.Docstring(代码描述)生成:Codex-D
通过代码生成代码的描述文字。也是通过最小化negative log-likelihood。该模型,我们叫为Codex-D。
7.模型的缺点
1)我们创建的模型Codex-12B其能力还很弱,不如一个入门的计算机学生。增大训练数据应该会提升效果。
2)Codex可能失败,或者产生反直觉的行为;
3)以文本为条件的模型在变量绑定上有问题,尤其出现多变量时,如下面的w没处理。
