近日OpenAI发布其最新的NLP模型-GPT-3(论文地址:https://arxiv.org/abs/2005.14165),并成功登顶了Github的趋势榜(https://github.com/openai/gpt-3),这个模型的出现再次证明了,在AI领域大力就是能够出奇迹,GPT3使用的数据集容量达到了45TB,参数个数1750亿,一个训练好的模型就要 700G的硬盘空间来存储。
而且近日GPT-3模型再度爆红Github,主要还是有网友根据GPT-3模型,上线了一个能够自动生成代码的网站debuid(https://debuild.co/)
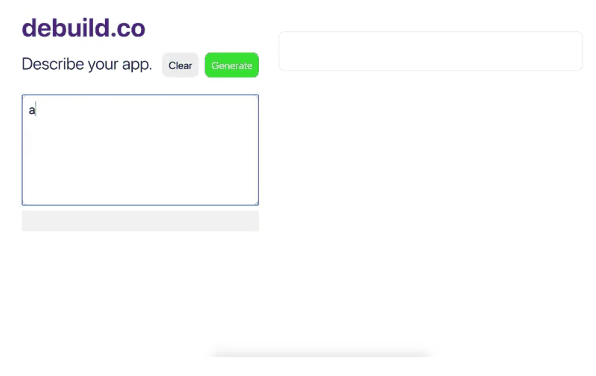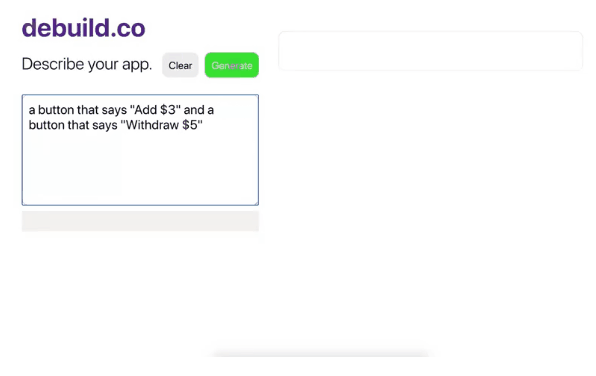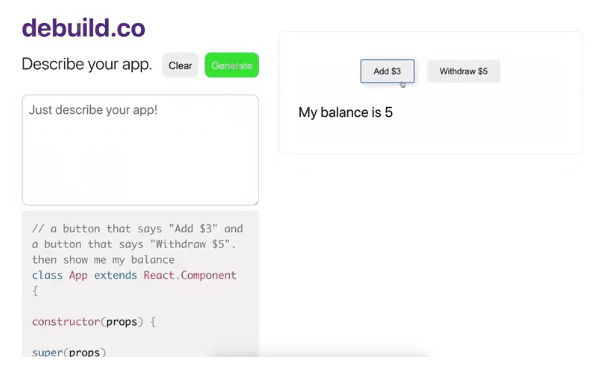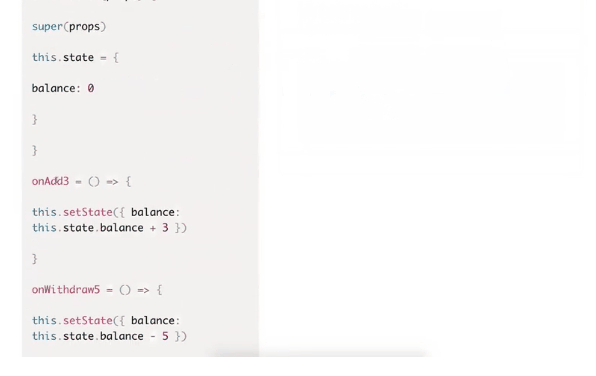
只要在这个网站注册以后,用户只要用英语描述你的需求,相关前端的代码就会被自动生成出来了,笔者这种在IT界摸爬滚打十几年的老程序,在试用了debuild网站之后,也惊得说不出话来。
初识Open AI
说起Open AI这个公司,在业界抱得大名,首先是因为其在去年DOTA2的顶级赛事TI8之后,与世界冠军OG战队举行了一场表演赛,当时Open AI的强化学习模型,在英雄阵容限定17个,部分道具和功能禁用的条件下,以2:0完胜了人类冠军,尤其是在第二场比赛中AI在15分钟就解决了战斗,展现的强大实力比较令人信服。这也使人类在对战游戏中的最后一道防线,MOBA的战略游戏也宣告失手。其开源的强化学习模型gym(https://github.com/openai/gym)也是业界比较均比较认可的游戏类模型包。翻开Open AI(https://www.openai.com/)的网址,你会发现他们除了做游戏AI,
还做这种自动玩魔方的机器人

虽然NLP好像不是Open AI最为关注的领域,不过他们在自然语言处理方面成果,一直非常引人关注,尤其是在去年年底著名魔幻电视剧《权利的游戏》全面烂尾,便有人使用本次GPT-2的上一代模型GPT-2 ,来重写剧本的结局。网友普遍反应AI改写的新结局比电视剧的版本要好。

自然语言处理发展历程
我们知道机器学习其实本质上是通过找到结果与多维输入之间的关系来进行预测的,而计算机其实是没有办法处理语言的,所以需要将自然语言转换为向量才能进行机器学习,由于在本轮AI行业全面爆发之初,行业还并未找到将单词转为向量的好办法,所以自然语言处理方面的程序一直比较慢,直到Word to Vector出现。
word2vec出世:在这项技术发明之前,自然语言处理方面的应用基本还是依靠专家制订语法规则,然后交由计算机实现的方式来推进。而word2vec的核心理念是一个单词是通过其周围的单词来定义的,word2vec算法通过负例采样暨观察一个单词不会和哪些单词一起出现;跳字处理暨观察一个单词周围的单词都有哪些,来完成单词到向量的转化过程。将单词转化为向量也被称为词嵌入(word embeding)的过程,从而让自然语言处理变成一个能让计算机自动执行的过程。一个好的词嵌入模型要满足两个条件一是词义相近的单词在空间上的距离要近,比如七彩虹、铭宣、影驰等显卡品牌对应的向量应该在词空间中的距离比较相近。二是有对应关系相同的单词对应向量的减法结果相等,比如v(中国)-v(北京)=v(英国)-v(伦敦)。
word2vec提出之后极大加速了自然语言处理的发展速度,GPT、BERT、XLNET等模型相继被提出,虽然他们的流派有自编码和自回归的不同,但是对传承词嵌入思想的继承还是比较一致的,这些模型都是在不借助语法专家的知识库的情况下,直接利用词与词之间的关系来进行模型训练。
自回归模型:本文的主角GPT系列,都是典型的自回归架构的自然语言处理模型。其实通俗的讲自回归就是使用自身做回归变量的过程,一般说来记为以下的形式。
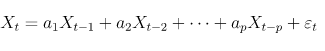
也就是说自回归模型假定t时刻的序列(Xt)可以利用前期若干时刻的随机变量的线性组合来描述。
我们来说一下什么是自然语言处理中的因式分解,先复习一下贝叶斯公式,它描述随机事件 A 和 B 的条件概率,其中P(A|B)是在 B 发生的情况下 A 发生的可能性。
![]()
假设我们I、love、you三个单词分别对应向量:X_1、X_2、X_3,那么如果我们要建模”I love you”这句话,其实就要通过贝叶斯公式解出,在自然数据这个序列出现的联合概率分布 P(X_1,X_2,X_3)。
由于词语之间的相互联系,我们除需要统计P(X_1)、P(X_2)、P(X_3)三个概率是不够的。因为X_1还依赖于其它变量存在条件分布 P(X_2|X_1) 和 P(X_3|X_1)。对于X_2和X_3也是一样,我们可以将这三个模型组合起来获得期望联合分布 P(X_1,X_2,X_3)=P(X_1)P(X_2|X_1)P(X_3|X_1,X_2)
一般来说,变量的每个可能的排序都存在自回归因式分解。在有N个变量的问题中,就存在 N! 个因式分解。在上面提到的三个变量的例子中,我们可以列举出六个自回归因式分解,当然在AR模型中都考虑了顺序信息,不会计算所有的因式分解,
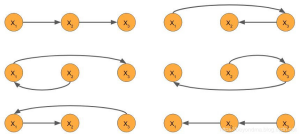
自回归的局限:自回归模型其实就是通过贝叶斯因式分解的方式来计算输入序列的概率密度。那么其劣势也就比较明显了,由于输入序列有方向性,所以自回归只能处理正向或者反向单向信息。
GPT-3的应对之道
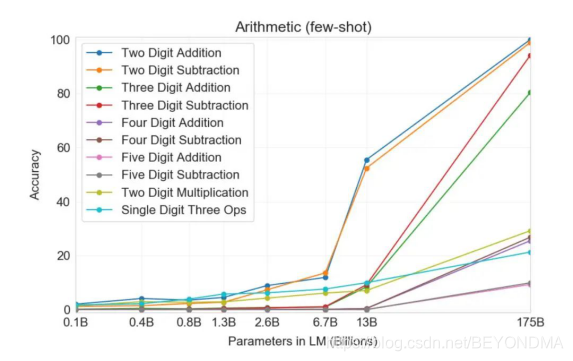
GPT-3的作者着在论文开头,就直接指出,通过对大量文本进行预训练,并且针对特定任务进行微调,模型的性能可以在许多 NLP 任务以及基准测试中获得显著提升。如图所示,X轴代码模型的参数数量级而纵轴代表准确率,可以看到,模型规模越大,准确率也会随之升高,尤其是在参数规模达到13亿以后,准确率提升的速度还会更快。简单讲也就是说GPT-3的决胜之道在于,其模型的训练集特别大,参数茫茫多。
GPT-3与 GPT-2使用了相同的模型和架构,包括改进的初始设置、预归一化和 reversible tokenization。GPT-3最主要提升点在于其在transformer的各层上都使用了交替密集和局部带状稀疏的注意力模式,我们知道理解自然语言需要注意最相关的信息。例如,在阅读过程中,人们倾向于把注意力集中在最相关的部分来寻找问题的答案。然而,如果不相关的片段对阅读理解产生负面影响,就会阻碍理解的过程,而理解过程需要有效的注意力。这一原理同样适用于自然语言的计算系统。注意力一直是自然语言理解和自然语言生成模型的重要组成部分。因此,交替密集和局部带状稀疏的注意力模式只关注k个贡献最大的状态。通过显式选择,只关注少数几个元素,与传统的注意方法相比,对于与查询不高度相关的值将被归0。
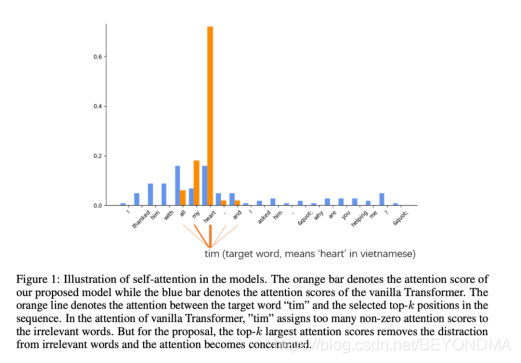
最新上线代码自动生成网站Debuild可能并不在Open AI的计划当中,如果继续向前推进使得产品经理的需求描述,直接变成可执行的全套代码,其颠覆性是我们根本无法想象的,目前已经有消息称Open AI已经开始关注GPT-3有可能引发的道德风险了,不过笔者认为大的趋势不可阻挡,也许AI会先革了程序员的命,把程序员的工作完全替代,也未为可知。