准备写系统的总结Linux系统的一些知识以及Linux系统编程。这一篇先讲Linux搭建常用的开发环境。
目录
0x01 Linux开发环境搭建
-
安装Linux系统(虚拟机安装、云服务器)
-
安装XSHELL、XFTP(远程登录)
-
安装VS Code
以上是使用虚拟机的方法,我的电脑装了双系统就不需要XSHELL以及XFTP的东西了。具体的很多关于VMWare的操作网上都有很多,比较推荐装双系统,在这就不过多描述了。
一、远程链接操作
如果需要使用XSHELL进行链接的话,需要在Ubuntu系统中装入:
sudo apt install openssh-sever这样就可以通过SSH协议来进行远程登录。输入下面的指令获取IP地址:
ifconfig如果提示没有上面那个指令,则输入:
sudo apt install net-tools之后就可以看到自己的IP地址了:
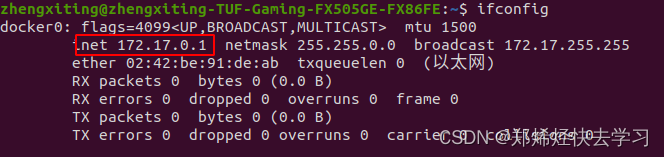
之后在XSHELL中配置一下就可以了。
接下来是VS Code链接虚拟机的部分,安装一些插件,首先安装一个中文的插件:

如果需要链接远程服务器,比如虚拟机,那么在VS Code下安装Remote Development:
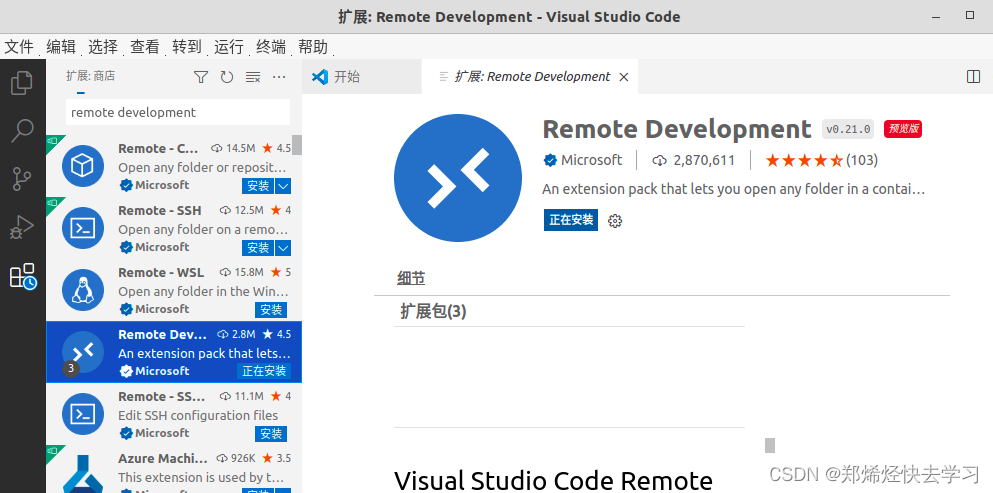
选择SSH链接:
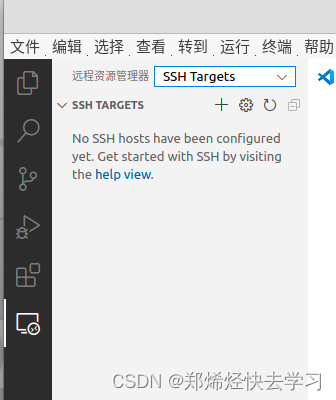
之后需要把我们的主机名称,主机IP地址,主机用户输入到config文件中:
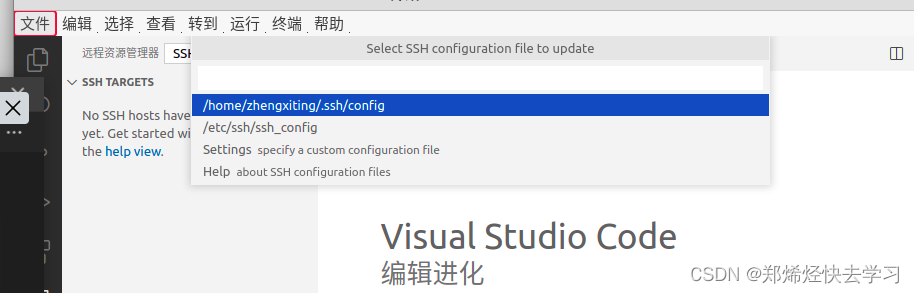
即可链接:

之后就可以与远程的服务器进行链接了,可以直接远程访问你的虚拟机。之后再安装C/C++的扩展即可。
0x02 GCC
一、安装
通过上面的操作,我们已经安装好了很多基础的模块,可以进行C/C++的编写。那么可以写完程序后我们就需要考虑编译了,我们就需要安装GCC。GCC原名为GNU C语言编译器。
sudo apt install gcc g++之后使用如下命令查看版本:
gcc --version使用Ctrl+L可以清空终端打印的所有东西。
之后我们写个hello world试验一下:
mkdir VSCode
cd VSCode
touch test.c
vim test.c你可以选择使用VS Code进行编译,也可以使用Vim。
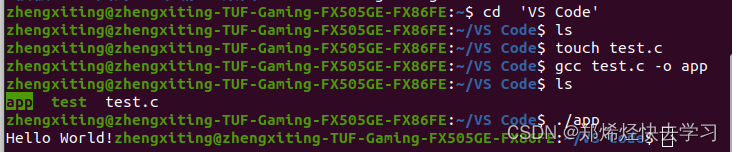
如果不加-o这个指令,他会生成Linux可执行程序.out,也可以实现相同的效果。那么GCC的工作原理是什么,我们很熟悉编译的过程中,是从高级语言到汇编语言到机器语言,才可以在计算机上运行,那么GCC在其中做了什么?
二、了解GCC
首先我们提供了一个源代码(.c/.h/.cpp...)之后进行预处理,之后我们可以得到预处理后源代码(.i),之后经过编译器,生成汇编代码(.s),之后经过汇编器,生成目标代码(.o),到这里他已经可以识别诸如0101的这种指令了,最后使用链接器,链接启动代码、库代码、其他目标代码等生成一个可执行程序(.exe/.out)。
那么以上,就是GCC的工作流程。接下来熟悉GCC的工作指令:
- 预处理
gcc test.c -E -o test.i之后就可以生成test.i了,之后使用Vim进行查看:
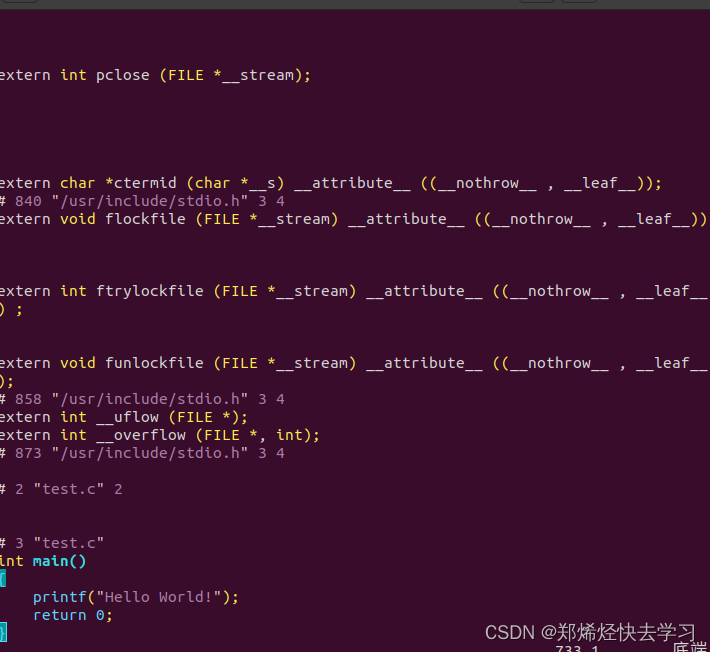
可以发现他把所声明到的库将其添加进来了,那么我们再看看汇编文件。
-
生成汇编代码
gcc test.i -S -o test.s
- 编译、汇编指定的源文件。
gcc test.s -s -o test.o这里会生成二进制文件,无法打开进行阅读,但是可以执行。
-
一般gcc是用于编译C程序,而g++是用于编译c++的,但是g++这个工具也可以用来编译C程序。gcc与g++如何区分呢,主要是看文件的后缀,c++的语法规则会更加严谨一些,C文件在编译阶段,g++会调用gcc,所以最后干脆使用g++编译就行了。
-
gcc它不会定义__cplusplus宏,而g++会,实际上,这个宏只是标志着编译器将会把代码按C还是C++语法来解释。
-
编译可以用gcc/g++,而链接可以用g++或者gcc -lstdc++。gcc命令不能自动和C++程序使用的库链接,所以通常使用g++来完成链接,但在编译阶段,g++会自动调用gcc。
那么gcc常用的参数选项总结如下:
| gcc编译选项 | 说明 |
|---|---|
| -E | 预处理指定的源文件,不进行编译 |
| -S | 编译指定的源文件,但是不进行汇编 |
| -c | 编译、汇编指定的源文件,但是不进行链接 |
| -o [file1] [file2] / [file2] -o [file1] | 将文件file2编译成可执行文件file1 |
| -I directory | 指定include包含文件的搜索目录 |
| -g | 在编译的时候,生成调试信息,该程序可以被调试器调试 |
| -D | 在程序编译的时候,指定一个宏 |
| -w | 不生成任何警告信息 |
| -Wall | 生成所有警告信息 |
| -On | n的取值范围为0-3。编译器的优化选项四个级别,0为没有优化,1为缺省值,3优化级别最高 |
| -l | 在程序编译时,指定使用的库 |
| -L | 指定编译时,搜索库的路径 |
| -fPIC / fpic | 生成与位置无关的代码 |
| -shared | 生成共享目标文件,通常用在建立共享库时 |
| -std | 指定C方言,如-std=c99,gcc默认的方言是GNU C |
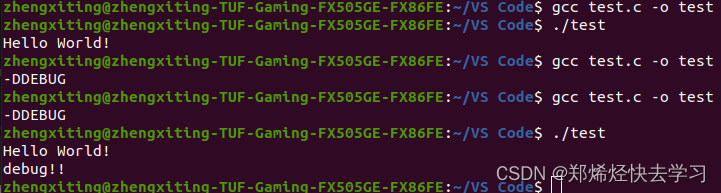
调试的时候可以这么使用:

那么在这就可以看出来了:
0x03 静态库的制作及使用
一、库的介绍
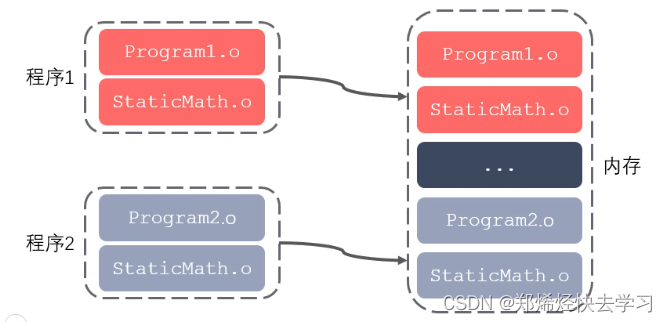
库文件是计算机上的一类文件,可以简单的把库文件看成一种代码仓库,提供使用者一些可以直接拿来用的变量、函数或类。库是特殊的一种程序,编写库的程序和编写一般的程序区别不大,只是库不能单独运行。库文件有两种,静态库和动态库(共享库),区别是:静态库在程序的链接阶段被复制到了程序中;动态库在链接阶段没有被复制到程序中,而是程序在运行时由系统动态加载到内存中供程序调用。库的好处?一个是代码的保密,一个是方便部署和分发。
二、静态库
命名规则:
Linux下:libxxx.a
lib:前缀(固定)
xxx:库的名字,可以随意
.a:后缀(固定)
Windows下:libxxx.lib
制作:
-
gcc -c 获得.o文件
-
将.o文件进行打包,使用ar工具(archive)
ar rcs libxxx.a xxx.o xxx.o-
其中 r将文件插入备存文件中;c建立备存文件;s索引。
使用:
-
首先将打包好的libxxx.a移至某个目录下。
-
使用gcc -c 各种.c文件 -I 编译到某个存储.o的路径
-
使用ar rcs libxxx.a 各种.o文件
-
之后拷贝到lib目录下
-
接下来要使用库的话,需要使用gcc main.c -o app -I ./include/ -L ./lib/ -l 库的名称
0x04 动态库的制作和使用
命名规则:
Linux下:libxxx.so
lib:前缀(固定)
xxx:库的名字,自己起
.so:后缀(固定)
在Linux下是一个可执行文件
Windows:libxxx.dll
动态库的制作:
-
gcc得到.o文件,得到和位置无关的代码
gcc -c -fpic a.c b.c- gcc得到动态库
gcc -shared a.o b.o -o libcalc.so使用:
-
首先将打包好的libxxx.so移至某个目录下。
-
使用gcc -c -fpic 各种.c文件 生成.o文件
-
使用gcc -shared 各种.o文件 -o 生成动态库
-
拷贝到lib目录下,执行gcc main.c -o main -I ./include/ -L ./lib/ -l 库的名称
一、配置动态库会出现的问题以及原因
执行完上面的步骤,会出现一个报错,找不到当前动态库的文件和目录,具体原因需要看看他们的工作原理:
静态库:GCC进行链接时,会把静态库中的代码打包到可执行程序中。
动态库:GCC进行链接时,动态库的代码不会被打包到可执行程序中。
程序启动之后,动态库会被动态加载到内存中,通过ldd(list dynamic dependencies)命令检查动态库依赖关系
如何定位共享库文件呢?
当系统加载可执行代码时,能够指定其所依赖的库的名字,但是还需要知道绝对路径。此时就需要系统的动态载入器来获取该绝对路径。对于elf格式的可执行程序,是由ld-linux.so来完成的,它先后搜索elf文件的DT_RPATH段->环境变量 LD_LIBRARY_PATH -> /etc/ld.so.cache文件列表 -> /llib/,/usr/lib目录找到库文件后将其载入内存。
所以,它能报这个错,是因为它找不到动态库的文件,你可以使用ldd main去看它的.so文件是否有找到。
二、解决动态库出现的问题
(1)环境配置
那么如何解决呢?解决的问题本质是将动态库加载到PATH路径中。我们可以输入env输出环境变量。那么我们只需要使用export命令来将我们的动态库添加进去,使用:
export LD_LIBRARY_PATH = $LD_LIBRARY_PATH:你的动态库路径使用pwd可以复制动态库的相关路径。
(2)用户配置
但是上面这个方法是有缺点的,它并不是永久地配置这个环境变量,当你关闭这个终端他就会失效,那么如何永久配置?
vim .bashrc之后在最下面添加我们的动态库路径:
export LD_LIBRARY_PATH = $LD_LIBRARY_PATH:你的动态库路径之后要进行保存:
source .bashrc上面这种方式为用户配置。对所有开启的终端都是有效的。
(3)系统配置
系统配置的方式:
sudo vim /etc/profile
source /etcc/profile也可以通过/etc/ld.so.cache文件来配置,但是不可以使用使用vim来配置这个文件,打开了会乱码,这个时候我们需要:
sudo vim /etc/ld.so.conf之后把我们的路径复制粘贴进去就可以了,只需要路径。然后保存:
sudo ldconfig以上的方法都是在搜索elf的文件的流程中加入的,不推荐在/lib/,/usr/lib目录下加,毕竟这是涉及系统的一些库文件,防止有些系统的动态库被替换掉。
0x05 静态库和动态库的对比
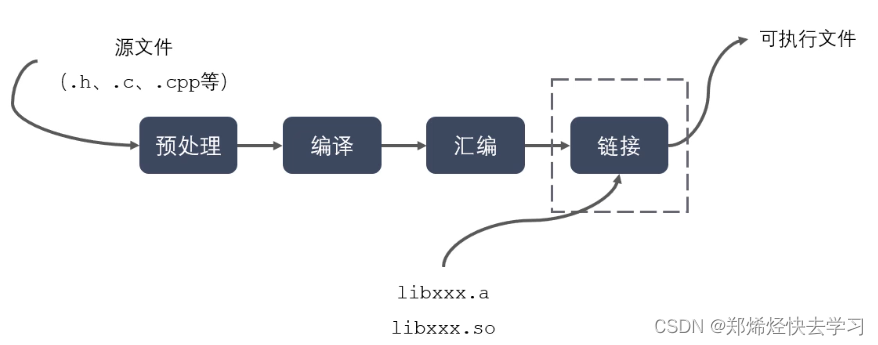
一、程序编译成可执行程序的过程
静态库与动态库在上面可以得知,他是在链接的阶段进行处理的,他们的区别来自链接阶段如何处理,对于在链接成可执行程序,分别称为静态链接方式和动态链接方式:
二、静态库的优缺点
优点:
-
静态库被打包到应用程序中加载速度快。
-
发布程序无需提供静态库,移植方便。
缺点:
-
消耗系统资源,浪费内存。
-
更新、部署、发布麻烦。
三、动态库的优缺点
优点:
-
可以实现进程间资源共享(共享库)
-
更新、部署、发布简单
-
可以控制何时加载动态库。
缺点:
-
加载速度比静态库慢。
-
发布程序时需要提供依赖的动态库。

0x06 Makefile
一、Makefile介绍
-
一个工程中的源文件不计其数,其按类型、功能、模块分别放在若干个目录中,Makefile文件定义了一系列的规则来指定哪些文件需要先编译,哪些文件需要后编译,哪些文件需要重新编译,甚至于进行更复杂的功能操作,因为Makefile文件就像一个shell脚本一样,也可以执行操作系统的命令。
-
Makefile带来的好处就是“自动化编译”,一旦写好,只需要一个make命令,整个工程完全自动编译,极大的提高了软件开发效率。make是一个命令工具,是一个解释makefile文件中指令的命令工具,一般来说,大多数的IDE都有这个命令,比如Delphi的make,Visual C++的nmake,Linux下GNU的make。
二、Makefile文件命名和规则
文件命名:makefile或者Makefile
Makefile规则:一个Makefile文件中可以有一个或者多个规则。
目标... : 依赖...
命令(Shell命令)
...-
目标:最终要生成的文件(伪目标除外)
-
依赖:生成目标所需要的文件或是目标
-
命令:通过执行命令对依赖操作生成目标(命令前必须使用Tab缩进)
Makefile中的其他规则一般都是为第一条规则服务的。
那么Makefile如何编写呢?其实就是把上面所学的gcc各种命令将其添加进去,之后保存makefile,使用make即可全部执行。
三、工作原理
命令在执行之前,需要检查规则中的依赖是否存在:
-
如果存在,执行命令。
-
如果不存在,向下检查其他规则,检查有没有一个规则是用来生成这个依赖的,如果找到了,则执行该规则中的命令。这样可以保证效率更高,方便于检查更新。
检测更新,在执行规则中的命令时,会比较目标和依赖文件的时间。
-
如果依赖的时间比目标的时间晚,需要重新生成目标。(并且只会更新已修改的依赖)
-
如果依赖的时间比目标时间早,目标不需要更新,对应规则中的命令不需要被执行。(会提示现在生成的可执行文件为最新)
这个工作原理可以得出的结论是,为什么需要编写多个源文件的各自的编译指令,因为这样子才可以提高编译的效率,不会导致说我只更改了一个文件,却所有文件都要重新编译的情况。
四、变量
自定义变量:变量名=变量值 var=hello
预定义变量:
| AR | 归档维护程序的名称,默认值为ar |
|---|---|
| CC | C编译器的名称,默认值为cc |
| CXX | c++编译器的名称,默认值为g++ |
| $@ | 目标的完整名称 |
| $< | 第一个依赖文件的名称 |
| $^ | 所有的依赖文件 |
获取变量的值:$(变量名)
如何使用:

应用在项目上:
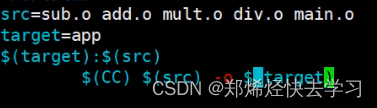
可以看到这样更加方便并且更加简洁了。
五、模式匹配
当我们有如下的规则时,可以看得出这么写其实有很多的不方便性:

那么我们可以通过模式匹配来修改:
%.o : %.c%:通配符,匹配一个字符串。两个%匹配的是同一个字符串。
那么则可以修改为如下:
%.o:%.c
gcc -c $< -o $@那么这么两句就可以匹配上面所有的文件,所以简化了很多。那么*.c与%.c有什么区别呢? *代表的是该文件下所有.c的文件,而%代表的是我们在目标中指定的依赖文件。
六、函数
在前面编写时,我们发现需要加很多次我们需要依赖的文件进去操作,那么问题来了,如果这个时候我们有成百上千个文件怎么办,这个时候我们就需要函数。
格式:$(wildcard PATTERN...)
-
功能:获取指定目录下指定类型的文件列表。
-
参数:PATTERN指的是某个或多个目录下的对应的某种类型的文件,如果有多个目录,一般使用空格间隔。
-
返回:得到的若干个文件的文件列表,文件名之间使用空格间隔。
$(wildcard *.c ./sub/*.c)格式:$(patsubst <patteern>,<replacement>,<text>)
-
功能:查找<text>中的单词(单词以“空格”、“Tab”或“回车”“换行”分隔)是否符合模式<pattern>,如果匹配的话,则以<replacement>替换。
-
<pattern>可以包括通配符'%',表示任意长度的子串。如果<replacement>中也包含'%',那么,<replacement>中的这个'%'将是<pattern>中的那个%所代表的字符,可以使用\来进行转义。
-
返回:函数返回被替换过后的字符串。
$(patsubst %.c,%.o,x.c,bar.c)
返回:x.o bar.o这个是用于返回.o文件。这样就可以代替刚刚上面的那两句了。
之后,我们可以使用在makefile中加入clean,可以清除多余的.o文件:

在终端中使用,即可以删除很多.o文件:
make clean但是当我们声明一个文件为clean时,使用make clean会报出clean已经是最新的提示,可是这个时候我们是需要删除东西的,这个时候我们需要把clean声明为伪目标,让其不要去外面其他的文件进行对比:
.PYONY:clean
clean:
...0x07 GDB调试
一、相关介绍
-
GDB是由GNU软件系统社区提供的调试工具,同GCC配套组成了一套完整的开发环境,GDB是Linux和许多类Unix系统中的标准开发环境。
-
一般来说,GDB主要帮助你完成下面四个方面的功能:
-
启动程序,可以按照自定义的要求随心所欲的运行程序。
-
可让被调试的程序在所指定的调置的断点处停住(断点可以是条件表达式)
-
当程序被停住时,可以检查此时程序中所发生的事。
-
可以改变程序,将一个BUG产生的影响修正从而测试其他BUG。
-
二、准备工作
-
通常,在为调试而编译时,我们会关掉编译器的优化选项('-o'),并打开调试选项('-g')。另外,`-Wall`在尽量不影响程序行为的情况下选项打开所有warning,也可以发现许多问题,避免一些不必要的BUG。
gcc -g -Wall program.c -o program-
‘-g’选项的作用是在可执行文件中加入源代码信息,比如可执行文件中第几条机器指令对应源代码的第几行,但并不是把整个源文件嵌入到可执行文件中,所以在调试时必须保证GDB能找到源文件。
三、命令
-
启动和退出
gdb 可执行程序
quit- 给程序设置参数、获取设置参数
set args 10 20
show args- GDB使用帮助
help- 查看当前文件代码
list (从默认位置显示)
list 行号 (从指定位置显示)
list 函数名 (从指定的函数显示)行号可以在vim中输入:set nu,就可以显示出来了
-
查看非当前文件代码
list 文件名:行号
list 文件名:函数名- 设置显示的行数
show list
set list 行数- 设置断点
break 行号
break 函数名
break 文件名:行号
break 文件名:函数- 查看断点信息
info break- 删除断点
delete 断点编号 - 设置断点无效
disable 断点编号- 设置断点生效
enable 断点编号- 设置条件断点(一般用在循环的位置)
break 10 if i==5 - 运行GDB程序
start (程序停在第一行)
run (遇到断点才停)- 继续运行,到下一个断点停
continue- 向下执行一行代码(不会进入函数体)
next- 变量操作
print 变量名(打印变量值)
ptype 变量名(打印变量类型)- 向下单步调试(遇到函数进入函数体)
step
finish (跳出函数体,在函数体中不可以存在可用断点)- 自动变量操作
display num (自动打印指定变量的值)
info display
undisplay 编号- 其他操作
set var 变量名=变量值
until (跳出循环)
backtrace(查看当前函数嵌套)