系统编程
第一节课
我们现在所使用的计算机都是在操作系统上对计算机进行操作的,操作系统为了让我们更加便捷的使用计算机,使用虚拟文件系统(VFS)为我们屏蔽了底层硬件的差异,把我们对计算机的操作以进程为单位来管理。
管理进程的结构
进程控制块(pcb,也称进程描述符)。每个进程描述符中有关于该进程的进程号(pid),指令,数据,状态等信息。一个计算机中所有的pcb是以双向循环链表这种数据结构连接在一起的。
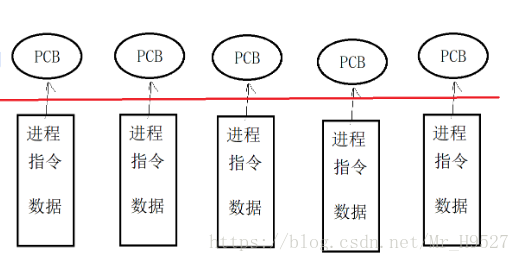
僵死进程:当进程主题被释放,而进程的pcb结构还存在时,这样的进程就被称为僵死进程(造成这种情况的一种原因是子进程已经结束但是父进程未结束,子进程就是一个僵死进程)。
操作系统内存管理方式:分页分段机制
操作系统启动时会将内存划分成等大小的一些区域,每个区域称之为页帧(大小为4k)。运行一个程序时,系统会为其在内存上的进程维护一个页表,由于在磁盘中存储程序时,也是按页存储,因此可以将该程序的每一页和内存上其所映射到的页帧一一对应(一个进程一个页表,而不是一个磁盘上的程序)。
页帧:

页表:

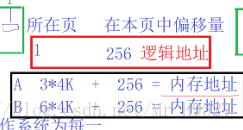
要查找一个指令或者一个数据的地址时,会根据该进程的页表查找到该指令或者数据所在内存中的页帧的地址,再加上其逻辑地址就是它在内存上的地址,假设一个数据在第一页的逻辑地址为256的地方,则根据该进程的页表可以确定该数据在下标为3的页帧上,由于在内存中的地址是从0开始偏移,每个页帧的大小为4k,则可以确定该数据在内存中的地址为:3*4k + 256(以上面的进程为例)
主函数的参数
主函数并不是像我们所想的那样没有参数,每个主函数都会有3个参数,int argc,char *argv[],char *envp[]。表示的含义分别为:传递给主函数参数的个数,参数列表,环境变量,注意参数列表中至少有一个参数,即argc>=1。(程序本身就是第一个参数)
输出缓冲区
每个进程都会有一个缓冲区,一般大小约为1M(1024k),使用标准输出函数输出的字符会先被输出到缓冲区中,当缓冲区满或者有其他可以刷新缓冲区的条件满足时,才会将缓冲区的内容输出到界面上。
缓冲区刷新的条件
- 遇到“\n”(换行符)
- 调用fflush函数主动刷新缓冲区
- 缓冲区满
- 进程结束
注意:如果以_exit函数结束进程,则不刷新缓冲区
第二节课:系统调用函数(关于文件操作)
Linux平台下的文件操作
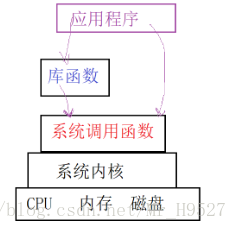
库函数:由库来实现,在用户态执行,部分库函数需要转调系统调用函数。
系统调用函数:是系统内核提供给用户访问系统管理底层硬件的接口,系统调用函数用户层只是一个接口,函数的具体实现都是由操作系统实现,并且在内核态执行。
Open函数:打开(或创建)一个文件
Int open(const char *path,int flag, /*int mode*/)这是系统调用函数open函数的参数列表,该函数返回一个非负整型值作为文件描述符,出错返回-1.第一个参数代表要打开的文件的路径和文件名,第二个参数代表指定的打开方式,第三个参数只有在需要打开的文件不存在,新创建时指定其访问权限时使用。
打开方式:
- O_RDONLY:以只读方式打开
- O_WRONLY:以只写方式打开
- O_RDWR:以读写方式打开
注意:在上面这三个常量中必须指定一个且只能指定一个。
- O_CREAT:若文件不存在,则创建它,此时会用到第三个参数
- O_TRUNC:如果文件存在且只为读写或写打开,将其长度截断为0
- O_APPEND:每次写时都追加到文件的末尾。
Read函数:读数据
Int read(int fd,void *buff, int size)该函数返回值代表读到的实际数据字节数的字节个数,fd表示要写入文件的文件描述符(open函数的返回值指定操作打开文件),buff表示读取的内容的存储缓冲区,size指定要读的数据的字节数
Write函数:写入数据
Int write(int fd, void *buff, int size)该函数返回值表示写成功的字节数,fd表示要写入的文件的文件描述符,buff指定要写的数据的起始地址,size表示要写的数据的字节长度
Close函数:关闭一个文件
Int close(int fd)关闭文件描述符为fd的文件
Lseek函数:移动读写游标
Int lseek(int fd, int size, int flag)fd表示文件描述符,size表示相对于第三个参数flag要移动的字节数。Flag的值为宏:SEEK_SET, SEEK_CUR, SEEK_END(分别表示文件的起始位置,当前位置和文件末尾)。
系统调用函数的执行过程:
每一个系统调用函数都有其唯一的系统调用号,当用户调用一个系统调用函数时,
- 首先会把该系统调用函数的系统调用号用eax寄存器保存起来,
- 然后保存进程运行的状态(即保存现场)
- 触发0x80中断,由内核态开始接管并且执行中断处理程序
- 在内核中有一个系统调用表,上面记录了每个系统调用号相对应的系统调用函数的位置,找到该位置,开始执行系统调用函数
- 系统调用函数执行完成,返回用户态继续执行进程
第三节课:fork函数
fork函数是在一个程序中创建进程的函数,pid_t fork(void),返回值表示创建出的进程的进程号,该函数没有参数。调用一次返回两次,父进程中返回子进程的pid,子进程中返回0.因为一个进程的子进程可以有很多个,而且没有一个函数可以的到该进程所有子进程的进程号,而一个进程只会有一个父进程,还可以调用getppid函数得到其父进程的进程号。
子进程会从fork之后的代码开始执行,在父进程创建出子进程后,两个 进程是相互独立的,各自运行互不干扰。父子进程谁先运行不由fork决定,而是由系统当前环境和进程调度算法决定。
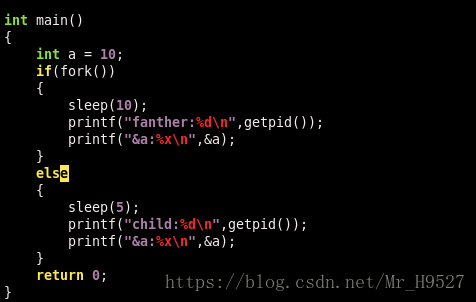
fork函数创建进程:
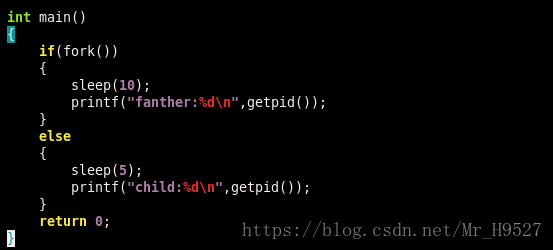
该段程序中,父进程中fork返回值为真值(子进程进程号),因此在父进程会执行if语句中的代码,我们知道,fork函数调用之后父子进程都会继续执行fork之后的代码,在子进程中fork返回值为0,因此会执行else中的语句,这也是我们经常用来控制父子进程的一种方法。运行结果如下:

父子进程间的数据共享:
父子进程对于fork之前的局部变量,全局变量,堆区空间都是不共享的。如果我们写一段代码来检测其中某一数据的位置,我们会发现输出的地址是相同的,这是为什么呢?因为fork之后父子进程就是两个独立的进程,系统会为其各自分配虚拟地址空间,在各自的虚拟地址空间中他们的位置是相同的,因此会输出同样的结果,但是父子进程的虚拟地址空间映射到的物理地址是不同的,这就是为什么输出结果一样,却不共享数据的原因。
我们知道父子进程的数据是不共享的,那么子进程是何时拷贝父进程的数据空间的呢?这里会用到写时拷贝技术。
写时拷贝技术:
Fork之后,父子进程会共用所有的空间,这时内核会将这些空间设置为只读的,如果有任意一个进程想要试图修改数据的时候,内核才会将该数据所在的页直接拷贝出来。
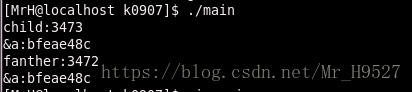
父子进程是否共享fork之前打开的文件描述符:我们用一段代码来测试一下:

在运行前该目录下是没有a.txt文件的,执行完之后,已经创建了该文件,并且给里面写入了字符串buff的值。


这说明,父子进程会共享一个文件描述符,但是会相互影响。因为该文件的读写偏移量会随着两个进程的操作都会发生变化,当父进程写入一段字符到文件里时,该文件的读写偏移量会走到文件结尾,这时如果子进程要读取文件内容的话,会发现读不到任何信息,因为读写偏移量已经到文件末尾了。那么子进程又是如何实现和父进程共享一个文件描述符的呢?
当fork创建出子进程后,子进程的pcb结构中的内容会对父进程pcb中的内容进行浅拷贝,因此会将父进程中保存的文件描述符所指向的地址的值拷贝过来,这样他们就共同指向了一个struct file结构体,而这个结构体中就保存了该文件的相关信息(注意是父子进程共同指向一个struct file,而不是子进程将父进程所指向的struct file拷贝了一份)。我们这样做之后就会牵扯出一个新的问题,如果子进程先结束,并且在结束时执行close(fd),关闭文件,那么父进程中还能对文件进行操作吗?
每个被打开的文件都会有一个strcut file结构体,而这个结构体中有一个变量是f_count,这里面就保存了指向该struct file结构的pcb个数,当f_count为1时,执行close才会真正关闭文件,大于1时只是将该引用计数减一。

第四节课:僵死进程的处理和信号
僵死进程:进程主体结束但是进程pcb仍旧存在(多进程编程中体现为:父进程未结束,但是子进程已经结束)进程结束后,进程的退出状态需要保存到pcb中,为父进程获取子进程推出状态。那么父进程是如何获取子进程的状态的呢?
wait函数

Wait函数返回的是已经结束的子进程的id号,参数一般为NULL。调用wait函数可以处理子进程。那么父进程是如何获取子进程的运行状态的呢,这里要用到信号
信号:信号是操作系统中一种事件通知机制,用于进程之间。信号是系统预先定义好的某些特定事件,发送信号和接收信号的主体是进程。信号一般都存放在/usr/include/bits/signum.h文件中。下面就是所有的信号宏

信号的处理方式:信号有三种处理方式,分别是默认(也就是系统指定该信号的处理方式),忽略(不对该信号做任何处理),自定义(自己定义一个函数,或者一个进程来响应该信号)。
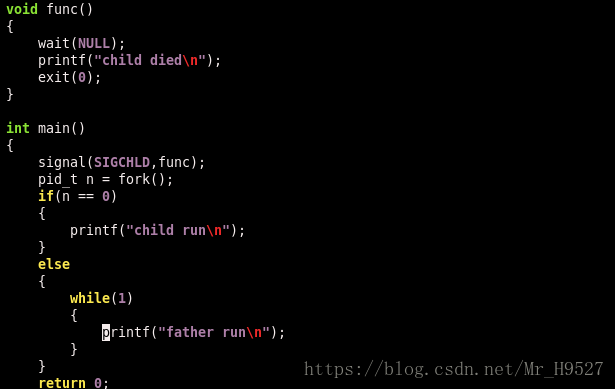
修改信号的处理方式:signal函数。

使用signal函数可以将信号的响应方式改变,第一个参数是要被修改的信号,第二个参数是要修改成的函数(响应方式)。wait函数是阻塞运行的,也就是说,一旦调用wait函数但是子进程还未结束,父进程就会停止运行,直到子进程执行完毕,wait函数执行完毕才会继续往下执行。为了提高效率,我们通常会使用signal函数把子进程状态改变的信号响应方式写入一个函数中,而该函数的实现会用到wait函数,也就是说,当父进程接收到子进程结束信号后,系统会调用该信号的响应函数,wait函数因此得以执行,而且父进程不用阻塞。
Exec函数:
当使用fork函数创建子进程后,子进程往往会调用一种exec函数以执行另一个程序,当进程调用一种exec函数时,该进程执行的程序完全被替换为新的程序,而新的程序则从其main函数开始执行,因为调用exec并不创建新进程,而是用一个全新的程序替换了当前进程的正文,数据和堆栈。
我们经常说exec函数,其实并没有exec这个函数,exec是一系列函数的总称:

这些exec函数的功能都是把进程的代码替换成另外一份全新的代码,只是在参数上有些不同,execl,execle,execlp这三个函数参数是不定的,新程序有多少个命令行参数,就要传递多少个参数,每个命令行参数都要独立成为一个参数,execv,execve,execvp可以将新程序的所有命令行参数都放在第二个参数中进行传递。Execle,execve可以传递环境变量,其他函数要调用进程中的environ变量为新程序复制当前环境。Execlp,execvp第一个参数为文件名,其他四个函数第一个参数为路径名。
这里我们用一个例子来演示一下execl函数是如何替换程序的
在exec.c文件中我们创建一个子进程,并且在子进程中调用execl函数,切换到当前目录下的可执行文件main,注意execl函数的最后一个参数要传一个NULL(也就是(char*)0),这样系统才会知道该函数参数传递完成。

在main文件中我们输出一行提示符即可

运行结果如下
