系列文章,欢迎订阅
本科生学深度学习-用最通俗易懂的方式学会深度学习-目录_深度学习csdn_香菜+的博客-CSDN博客
之前写了QLearning,时间有点久了,后来也忙于工作,一直没有输出,今天写下DQN
1、DQN概述
Q-Learning 则采用在线学习的方式,每个时间步都要更新 Q 值函数,并且行为只能是离散的动作,
当面对连续动作空间的时候,数据爆炸,纬度爆炸的问题很难解决,内存有限,没办法缓存太多数据,
如围棋,对于动作集合规模庞大、动作连续的场景(如机器人控制领域),其很难学习到较好的结果。
Q-Learning 使用表格来存储和更新 Q 值函数,DQN 使用深度神经网络来逼近 Q 值函数。
说直白点:用神经网络也就是一组函数代替表格,将表格进行压缩。

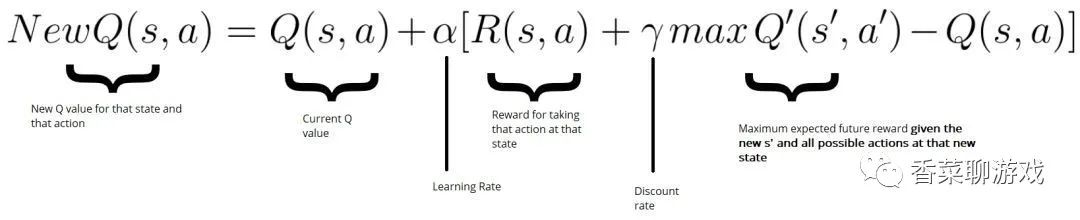
解读下公式,这个公式的重点是后面的那一坨是什么意思
Q(s,a) 是表示在状态S下执行动作a,获得Q值,可以理解为上图的(current_state,action)
R(s,a) 表示才去当前action之后获得的奖励,比如超级玛丽吃到一个金币,碰到怪物就为负的reward
Q’(s',a')表示在状态S‘下所有动作的Q值,这里取了一个max,表示取个最大值
2、dqn 知识点
1> Q值和reward
Q值是一种表示在给定状态下采取某个动作的预期回报值的函数。它表示了一个智能体在某个状态下采取某个动作所能获得的长期累积奖励值。
奖励(reward)是在强化学习任务中,作为一种指导学习的信号。它表示智能体在某种情境下采取某个动作后的立即回报,即当前时刻获得的奖励。
因此,Q值和reward的区别在于,Q值是一种长期累积奖励的预期值,而reward是指当前时刻获得的奖励值。
举个例子,在超级玛丽中,跳起吃到一个金币,这个金币就是reward,过关这个行为用Q来衡量
2>为什么需要两个网络
DQN需要分开两个网络,一个是当前的价值网络,一个是目标网络。
价值网络用于每次迭代的更新,
而目标网络用于计算目标值,
保持目标值的稳定性,从而提高训练的稳定性和收敛速度。
目标网络会以一定的频率拷贝价值网络的参数
3>为什么引入replaybuffer
Replay Buffer 是 DQN 中的一种经验回放机制,其主要作用是存储过去的经验,以便在训练神经网络时进行随机采样。
避免训练样本的相关性:每个状态和动作的奖励都是相互关联的,因此在连续的训练中,相邻的样本会有很大的相关性,导致神经网络的更新效果不佳。使用 Replay Buffer 可以将这些相关性打破,让训练样本更加独立,从而提高学习效率。
同时回放机制既可以学习自己的经验,也可以学习其他人的经验,提升了训练效率
4>误差来自哪里
误差是当前状态下预测的 Q 值与实际获得的奖励加上下一个状态的最大 Q 值的差值。
简单点:根据之前的经验的Q值 和 当前预测的Q值的差
具体公式为:loss = reward + gamma * max(Q(next_state)) - Q(state, action)
reward 表示当前状态下的实际获得的奖励,
gamma 是折扣因子,主要是控制新的值对神经网络的影响,不能推翻原来的经验
Q(next_state) 是下一个状态的 Q 值,
max(Q(next_state)) 是下一个状态中最大的 Q 值,这里当做目标值
Q(state, action) 是当前状态下对应动作的 Q 值。
DQN 的训练目标就是最小化 loss,使得网络的预测 Q 值尽可能地接近真实 Q 值。
3、dqn代码
在公司没办法验证,找了份代码,看逻辑完全正确,也很好理解
import torch # 导入torch
import torch.nn as nn # 导入torch.nn
import torch.nn.functional as F # 导入torch.nn.functional
import numpy as np # 导入numpy
import gym # 导入gym
# 超参数
BATCH_SIZE = 32 # 样本数量
LR = 0.01 # 学习率
EPSILON = 0.9 # greedy policy
GAMMA = 0.9 # reward discount
TARGET_REPLACE_ITER = 100 # 目标网络更新频率
MEMORY_CAPACITY = 2000 # 记忆库容量
env = gym.make('CartPole-v1', render_mode="human").unwrapped # 使用gym库中的环境:CartPole,且打开封装(若想了解该环境,请自行百度)
N_ACTIONS = env.action_space.n # 杆子动作个数 (2个)
N_STATES = env.observation_space.shape[0] # 杆子状态个数 (4个)
"""
torch.nn是专门为神经网络设计的模块化接口。nn构建于Autograd之上,可以用来定义和运行神经网络。
nn.Module是nn中十分重要的类,包含网络各层的定义及forward方法。
定义网络:
需要继承nn.Module类,并实现forward方法。
一般把网络中具有可学习参数的层放在构造函数__init__()中。
只要在nn.Module的子类中定义了forward函数,backward函数就会被自动实现(利用Autograd)。
"""
# 定义Net类 (定义网络)
class Net(nn.Module):
def __init__(self): # 定义Net的一系列属性
# nn.Module的子类函数必须在构造函数中执行父类的构造函数
super(Net, self).__init__() # 等价与nn.Module.__init__()
self.fc1 = nn.Linear(N_STATES, 50) # 设置第一个全连接层(输入层到隐藏层): 状态数个神经元到50个神经元
self.fc1.weight.data.normal_(0, 0.1) # 权重初始化 (均值为0,方差为0.1的正态分布)
self.out = nn.Linear(50, N_ACTIONS) # 设置第二个全连接层(隐藏层到输出层): 50个神经元到动作数个神经元
self.out.weight.data.normal_(0, 0.1) # 权重初始化 (均值为0,方差为0.1的正态分布)
def forward(self, x): # 定义forward函数 (x为状态)
x = F.relu(self.fc1(x)) # 连接输入层到隐藏层,且使用激励函数ReLU来处理经过隐藏层后的值
actions_value = self.out(x) # 连接隐藏层到输出层,获得最终的输出值 (即动作值)
return actions_value # 返回动作值
# 定义DQN类 (定义两个网络)
class DQN(object):
def __init__(self): # 定义DQN的一系列属性
self.eval_net, self.target_net = Net(), Net() # 利用Net创建两个神经网络: 评估网络和目标网络
self.learn_step_counter = 0 # for target updating
self.memory_counter = 0 # for storing memory
self.memory = np.zeros((MEMORY_CAPACITY, N_STATES * 2 + 2)) # 初始化记忆库,一行代表一个transition
self.optimizer = torch.optim.Adam(self.eval_net.parameters(), lr=LR) # 使用Adam优化器 (输入为评估网络的参数和学习率)
self.loss_func = nn.MSELoss() # 使用均方损失函数 (loss(xi, yi)=(xi-yi)^2)
def choose_action(self, state): # 定义动作选择函数 (x为状态)
x = torch.unsqueeze(torch.FloatTensor(state), 0) # 将x转换成32-bit floating point形式,并在dim=0增加维数为1的维度
if np.random.uniform() < EPSILON: # 生成一个在[0, 1)内的随机数,如果小于EPSILON,选择最优动作
actions_value = self.eval_net.forward(x) # 通过对评估网络输入状态x,前向传播获得动作值
action = torch.max(actions_value, 1)[1].data.numpy() # 输出每一行最大值的索引,并转化为numpy ndarray形式
action = action[0] # 输出action的第一个数
else: # 随机选择动作
action = np.random.randint(0, N_ACTIONS) # 这里action随机等于0或1 (N_ACTIONS = 2)
return action # 返回选择的动作 (0或1)
def store_transition(self, s, a, r, s_): # 定义记忆存储函数 (这里输入为一个transition)
transition = np.hstack((s, [a, r], s_)) # 在水平方向上拼接数组
# 如果记忆库满了,便覆盖旧的数据
index = self.memory_counter % MEMORY_CAPACITY # 获取transition要置入的行数
self.memory[index, :] = transition # 置入transition
self.memory_counter += 1 # memory_counter自加1
def learn(self): # 定义学习函数(记忆库已满后便开始学习)
# 目标网络参数更新
if self.learn_step_counter % TARGET_REPLACE_ITER == 0: # 一开始触发,然后每100步触发
self.target_net.load_state_dict(self.eval_net.state_dict()) # 将评估网络的参数赋给目标网络
self.learn_step_counter += 1 # 学习步数自加1
# 抽取记忆库中的批数据
sample_index = np.random.choice(MEMORY_CAPACITY, BATCH_SIZE) # 在[0, 2000)内随机抽取32个数,可能会重复
b_memory = self.memory[sample_index, :] # 抽取32个索引对应的32个transition,存入b_memory
b_s = torch.FloatTensor(b_memory[:, :N_STATES])
# 将32个s抽出,转为32-bit floating point形式,并存储到b_s中,b_s为32行4列
b_a = torch.LongTensor(b_memory[:, N_STATES:N_STATES+1].astype(int))
# 将32个a抽出,转为64-bit integer (signed)形式,并存储到b_a中 (之所以为LongTensor类型,是为了方便后面torch.gather的使用),b_a为32行1列
b_r = torch.FloatTensor(b_memory[:, N_STATES+1:N_STATES+2])
# 将32个r抽出,转为32-bit floating point形式,并存储到b_s中,b_r为32行1列
b_s_ = torch.FloatTensor(b_memory[:, -N_STATES:])
# 将32个s_抽出,转为32-bit floating point形式,并存储到b_s中,b_s_为32行4列
# 获取32个transition的评估值和目标值,并利用损失函数和优化器进行评估网络参数更新
q_eval = self.eval_net(b_s).gather(1, b_a)
# eval_net(b_s)通过评估网络输出32行每个b_s对应的一系列动作值,然后.gather(1, b_a)代表对每行对应索引b_a的Q值提取进行聚合
q_next = self.target_net(b_s_).detach()
# q_next不进行反向传递误差,所以detach;q_next表示通过目标网络输出32行每个b_s_对应的一系列动作值
q_target = b_r + GAMMA * q_next.max(1)[0].view(BATCH_SIZE, 1)
# q_next.max(1)[0]表示只返回每一行的最大值,不返回索引(长度为32的一维张量);.view()表示把前面所得到的一维张量变成(BATCH_SIZE, 1)的形状;最终通过公式得到目标值
loss = self.loss_func(q_eval, q_target)
# 输入32个评估值和32个目标值,使用均方损失函数
self.optimizer.zero_grad() # 清空上一步的残余更新参数值
loss.backward() # 误差反向传播, 计算参数更新值
self.optimizer.step() # 更新评估网络的所有参数
dqn = DQN() # 令dqn=DQN类
for i in range(400): # 400个episode循环
print('<<<<<<<<<Episode: %s' % i)
s = env.reset() # 重置环境
episode_reward_sum = 0 # 初始化该循环对应的episode的总奖励
while True: # 开始一个episode (每一个循环代表一步)
env.render() # 显示实验动画
a = dqn.choose_action(s) # 输入该步对应的状态s,选择动作
s_, r, done, info = env.step(a) # 执行动作,获得反馈
# 修改奖励 (不修改也可以,修改奖励只是为了更快地得到训练好的摆杆)
x, x_dot, theta, theta_dot = s_
r1 = (env.x_threshold - abs(x)) / env.x_threshold - 0.8
r2 = (env.theta_threshold_radians - abs(theta)) / env.theta_threshold_radians - 0.5
new_r = r1 + r2
dqn.store_transition(s, a, new_r, s_) # 存储样本
episode_reward_sum += new_r # 逐步加上一个episode内每个step的reward
s = s_ # 更新状态
if dqn.memory_counter > MEMORY_CAPACITY: # 如果累计的transition数量超过了记忆库的固定容量2000
# 开始学习 (抽取记忆,即32个transition,并对评估网络参数进行更新,并在开始学习后每隔100次将评估网络的参数赋给目标网络)
dqn.learn()
if done: # 如果done为True
# round()方法返回episode_reward_sum的小数点四舍五入到2个数字
print('episode%s---reward_sum: %s' % (i, round(episode_reward_sum, 2)))
break4、dqn 总结
DQN 训练过程中需要使用多个优化技巧,如目标网络、延迟更新等,以提高训练的效果和稳定性。
DQN 相关的两个实现是doubleDQN和duelingDQN,两者都是改进版本,后面再介绍
最后,学习强化学习重在理解,先理解思想再谈使用
本书由官方认证:跨平台开发王者,编写一套代码,可同时发布到iOS/Android/Web,以及微信/支付宝/百度/头条/QQ/快手/钉钉/淘宝/360等多个平台,“基础+进阶+实战+源码+9个章节实训案例”,边学边练,真正掌握使用uni-app开发项目
